Deep Agents:企业级Agent工程化落地与Deep Research实践指南
Deep Agents框架系统性解决企业级AI Agent开发痛点,赋能Deep Research等生产级应用落地。
企业级AI Agent开发面临工具失控、上下文污染、成本失控、安全隐患等核心痛点。LangChain推出基于LangGraph的Deep Agents框架,系统性解决这些问题。其核心应用场景Deep Research采用"规划-搜索-反思-再搜索"的Agentic RAG范式,实现复杂任务自主拆解、多轮深度搜索和结构化报告生成。企业出于业务适配和数据合规需求,应基于该框架进行定制化私有部署开发。
引言:智能体开发的十大痛点
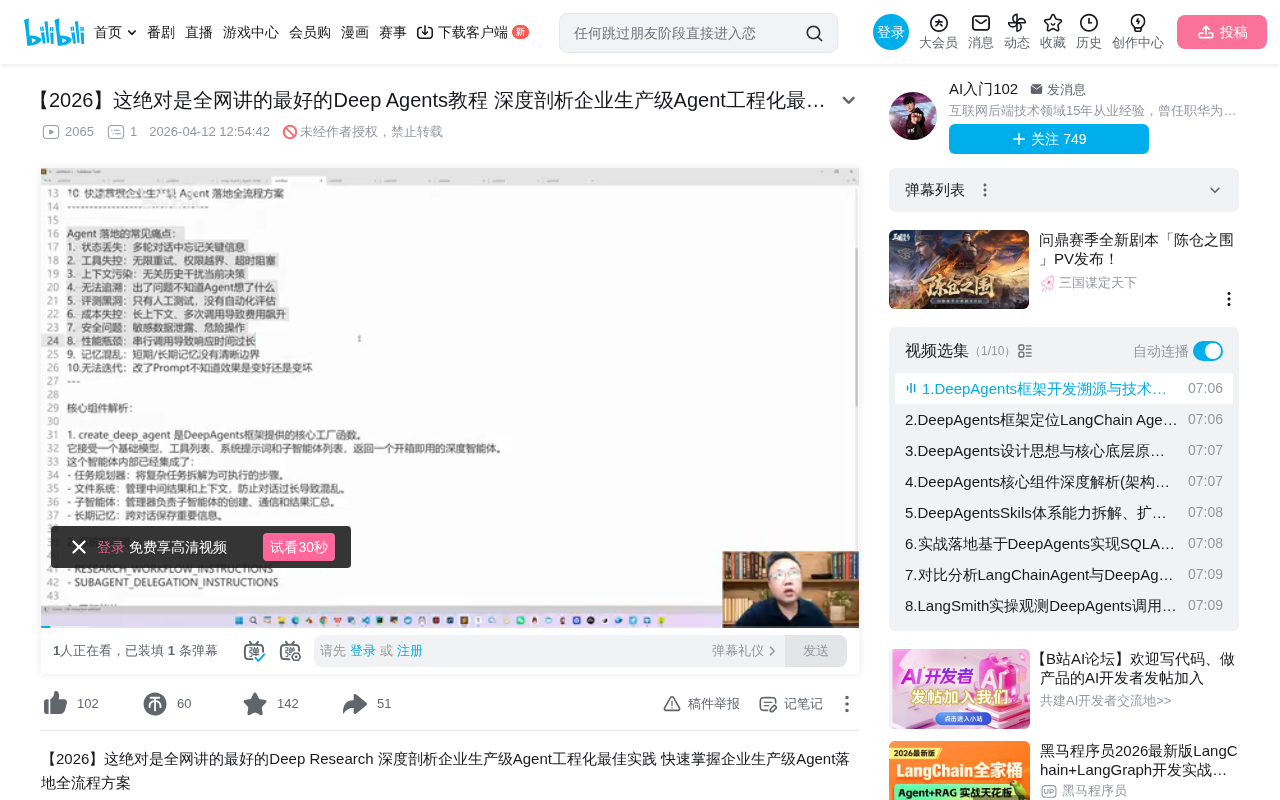
在企业级AI Agent开发过程中,开发者们普遍面临着一系列棘手的问题。根据实际项目经验,这些痛点可以归纳为十个核心方面,其中最为严重的两个问题是工具失控和上下文污染。
工具失控的技术根源
AI Agent(智能体)是一种能够感知环境、自主规划并执行动作的AI系统。与传统的单次问答式LLM不同,Agent具备"思考-行动-观察"的循环能力(即学术界所称的ReAct范式)。工具调用(Tool Calling/Function Calling)是Agent的核心能力之一,允许LLM在推理过程中动态调用外部API、数据库查询、代码执行等工具。
所谓工具失控,指的是在企业场景中,Agent需要调用的工具往往不是一两个,而是由大量工具组成的工具集。当工具数量从个位数扩展到数十甚至数百个时,模型需要从语义上精准匹配用户意图与工具描述,这对Embedding质量、工具描述规范性以及参数提取准确性都提出了极高要求。在这种情况下,Agent可能无法精准调用正确的工具,或者在调用工具时无法从用户的query中准确提取关键参数(arguments),导致整个流程失败。
上下文污染的本质
大语言模型的"上下文窗口"(Context Window)是指模型在单次推理中能够处理的最大token数量。GPT-4o支持128K tokens,Claude 3.5支持200K tokens。在多轮对话或长链路Agent任务中,历史消息、工具调用记录、中间结果会不断累积填充上下文窗口。
上下文污染正是由此而来——无关的历史信息干扰了当前的决策过程,使得Agent的输出质量大幅下降。其技术本质是"Lost in the Middle"现象:当无关信息占据大量上下文时,模型的注意力机制受到干扰,对窗口中间位置信息的关注度显著下降,从而产生决策偏差或遗忘关键信息。有效的上下文管理策略包括滑动窗口、摘要压缩和选择性记忆等。
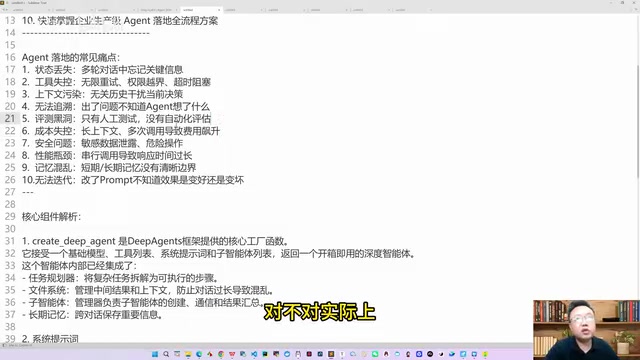
除此之外,还有几个不容忽视的问题:
- 成本失控:特别是在使用自主规划型Agent处理长链路任务时,token消耗惊人。以GPT-4o为例,输入token约$2.5/百万,输出token约$10/百万,一个复杂研究任务的单次执行可能消耗数万甚至数十万tokens,在高并发企业场景下成本会快速放大
- 安全隐患:敏感数据泄露和危险操作风险,比如通过shell命令执行自动化操作时可能误删文件、修改密码
- 性能瓶颈:响应延迟和吞吐量限制影响用户体验
- 状态丢失:多轮交互中的状态管理困难
这些问题如果逐一手动解决,工程量巨大且容易顾此失彼。正是在这样的背景下,LangChain从V1版本开始,将核心重点转向了Agent定位,推出了Deep Agents框架,旨在系统性地解决上述痛点。
LangChain的框架演进
LangChain是目前最广泛使用的LLM应用开发框架之一,由Harrison Chase于2022年10月创立。其早期版本(V0.x)以Chain(链式调用)为核心抽象,帮助开发者快速串联LLM调用、提示词模板和工具。然而随着Agent应用复杂度的提升,Chain模式的局限性逐渐显现:缺乏动态规划能力、状态管理薄弱、生产级可靠性不足。为此,LangChain推出了LangGraph作为底层图计算引擎,支持有状态的、可循环的Agent工作流,并在此基础上构建了面向企业生产环境的Deep Agents框架,标志着从"原型开发工具"向"生产级Agent工程平台"的战略转型。
什么是Deep Research?
Deep Research是Deep Agents的一个核心应用场景,也是目前企业中需求最为旺盛的能力之一。它在政府机关、事业单位、国企央企以及咨询公司中有着广泛的应用。
Deep Research的定义
Deep Research是一种由大语言模型(LLM)驱动的智能体搜索技术,基于AI Agent的搜索能力构建。与传统的关键词搜索或简单的一问一答式ChatBot不同,Deep Research的核心理念是像人类研究员一样,针对复杂课题进行自主规划、多轮搜索和深度信息整合,最终生成一份结构化的专业报告。
从技术架构上看,Deep Research是RAG(检索增强生成)的高级演进形态。传统RAG是"单次检索+单次生成"的静态流程,而Deep Research采用的是"规划-搜索-反思-再搜索"的动态迭代范式,学术界称之为Agentic RAG或Iterative RAG。其核心创新在于引入了"反思机制"(Reflection):Agent在每轮搜索后会评估信息的充分性和可信度,判断是否需要补充搜索、调整搜索策略或深入某个子方向,从而处理开放性复杂问题。
其应用场景非常广泛:
- 市场调研:行业分析、竞品研究、市场趋势预测
- 学术研究:论文初稿生成、文献综述整理
- 财经分析:投资研究报告、行业财务分析
- 咨询报告:企业战略分析、政策研究
Deep Research的三大核心能力
自主规划与执行
当用户提出一个复杂需求,比如"撰写一份关于新能源汽车市场的调研报告"或"基于某个课题的论文框架",Deep Research会将复杂任务自动分解为多个子问题,并动态调整搜索策略。这种能力的关键在于"Research"——它不是简单的单次搜索,而是多轮迭代式的深度探索。每一轮搜索结束后,系统会通过反思机制评估已获取信息的完整性,决定下一步的探索方向。
多元信息整合
系统会从多种不同的数据源中获取信息,包括网页、PDF文档、图像等,然后将这些异构信息进行统一整合。这一步骤模拟了人类研究员在做课题时从多个渠道收集资料的过程。
结构化报告生成
最终,通过大模型的生成能力,将整合后的信息输出为结构化的专业报告。整个过程采用端到端的推理方式,确保报告的逻辑连贯性和专业性。值得注意的是,OpenAI的Deep Research底层使用了专门针对搜索推理优化的o3模型,体现了强推理能力对该类任务的关键作用。
通用产品 vs 定制化开发:企业该如何选择
目前市面上已有多款Deep Research产品,包括OpenAI的Deep Research、Google Gemini的Deep Research,以及国内通义千问推出的千问Deep Research。
然而,这些产品有一个共同的特点——它们都是通用型产品。对于企业而言,通用产品虽然能在一定程度上辅助工作,但要达到满意的效果,往往需要打一个问号。
为什么企业需要定制化Deep Research?
企业的实际需求通常具有强烈的行业特性和业务特性。比如:
- 金融行业需要对接特定的数据源和合规要求
- 咨询公司需要符合自身方法论的报告模板
- 研究机构需要对接内部知识库和专有数据
除业务适配性外,数据安全与合规是企业选择定制化方案的深层驱动力。金融、医疗、政府等强监管行业对数据出境有严格限制,将敏感业务数据发送至OpenAI或Google的云端API存在合规风险。定制化开发允许企业选择私有化部署的开源模型(如Qwen、DeepSeek、LLaMA系列),将整个推理链路保持在企业内网环境中。此外,定制化开发还能对接企业内部知识库(内网文档、专有数据库)、集成企业现有的身份认证和权限管理系统,以及根据行业规范定制报告模板和输出格式——这些都是通用SaaS产品无法提供的核心价值。
Deep Research的核心实现流程
总结来看,Deep Research的实现包含三个关键步骤:
- 复杂任务拆解:将用户的复杂需求分解为可执行的子任务序列,每个子任务对应一个明确的搜索或分析目标。这一步骤借鉴了任务规划(Task Planning)领域的研究成果,通过层次化分解将开放性问题转化为结构化的执行计划
- 联网搜索与信息采集:通过互联网搜索引擎和各类数据源,进行多轮深度信息检索和整理。每轮搜索后的反思机制决定是否需要继续迭代,直至信息充分
- 结构化报告生成:利用大模型的理解和生成能力,将采集到的信息整合为逻辑清晰、结构完整的专业报告
这三个步骤环环相扣,构成了一个完整的自动化研究流程。通过Deep Agents框架的支持,开发者可以在此基础上进行灵活的定制和扩展,满足不同企业场景的具体需求。在成本控制方面,框架通常还会集成模型路由(小模型处理简单子任务)、语义缓存(避免重复查询)等优化策略,帮助企业在效果与成本之间取得平衡。
总结与展望
Deep Agents的出现,标志着AI Agent开发从"能用"向"好用"的关键转变。它系统性地解决了工具失控、上下文污染、成本失控、安全隐患等企业级痛点,为生产级Agent的落地提供了工程化的最佳实践方案。
对于企业而言,掌握Deep Agents的核心理念和实践方法,不仅能够快速构建Deep Research等高价值应用,更能为后续更复杂的Agent系统奠定坚实的技术基础。随着AI Agent从概念走向大规模落地,Deep Agents无疑是每一位AI工程师都应该深入了解的关键技术。
核心要点
- 企业级Agent开发面临工具失控、上下文污染、成本失控、安全隐患等十大核心痛点,其技术根源分别在于大规模工具集的语义匹配难题和上下文窗口的"Lost in the Middle"现象
- LangChain V1推出Deep Agents框架(基于LangGraph图计算引擎),系统性解决生产级Agent的工程化落地问题
- Deep Research是Deep Agents的核心应用场景,本质上是RAG的高级演进——通过"规划-搜索-反思-再搜索"的Agentic RAG范式,实现自主规划、多轮搜索和深度信息整合,最终生成专业报告
- 通用型Deep Research产品难以满足企业定制化需求,企业出于业务适配性和数据合规双重考量,需基于框架进行行业化私有化开发
- Deep Research核心流程包含复杂任务拆解、联网搜索采集、结构化报告生成三个关键步骤,并可集成模型路由和语义缓存等成本优化策略
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。