DeepSeek-V3.2 Released: Coding and Math Capabilities Join the Global Top Tier

DeepSeek-V3.2 matches Gemini 3.0 Pro, setting new open-source SOTA in coding, math, and Agent capabilities.
DeepSeek has released V3.2, matching Gemini 3.0 Pro across three core capabilities: coding, mathematical reasoning, and Agent development, setting a new open-source model SOTA record. Built on a MoE architecture with approximately 671 billion total parameters but only 37 billion activated per inference, it achieves highly efficient reasoning. This breakthrough proves there is no insurmountable ceiling for open-source models and holds significant implications for lowering AI barriers and driving industry competition.
Overview
DeepSeek recently released its V3.2 model, matching Gemini 3.0 Pro across multiple benchmarks, with coding, math, and Agent development capabilities joining the global top tier and setting a new SOTA record for open-source models. This update once again demonstrates the formidable strength of Chinese open-source large language models in the global AI competition.
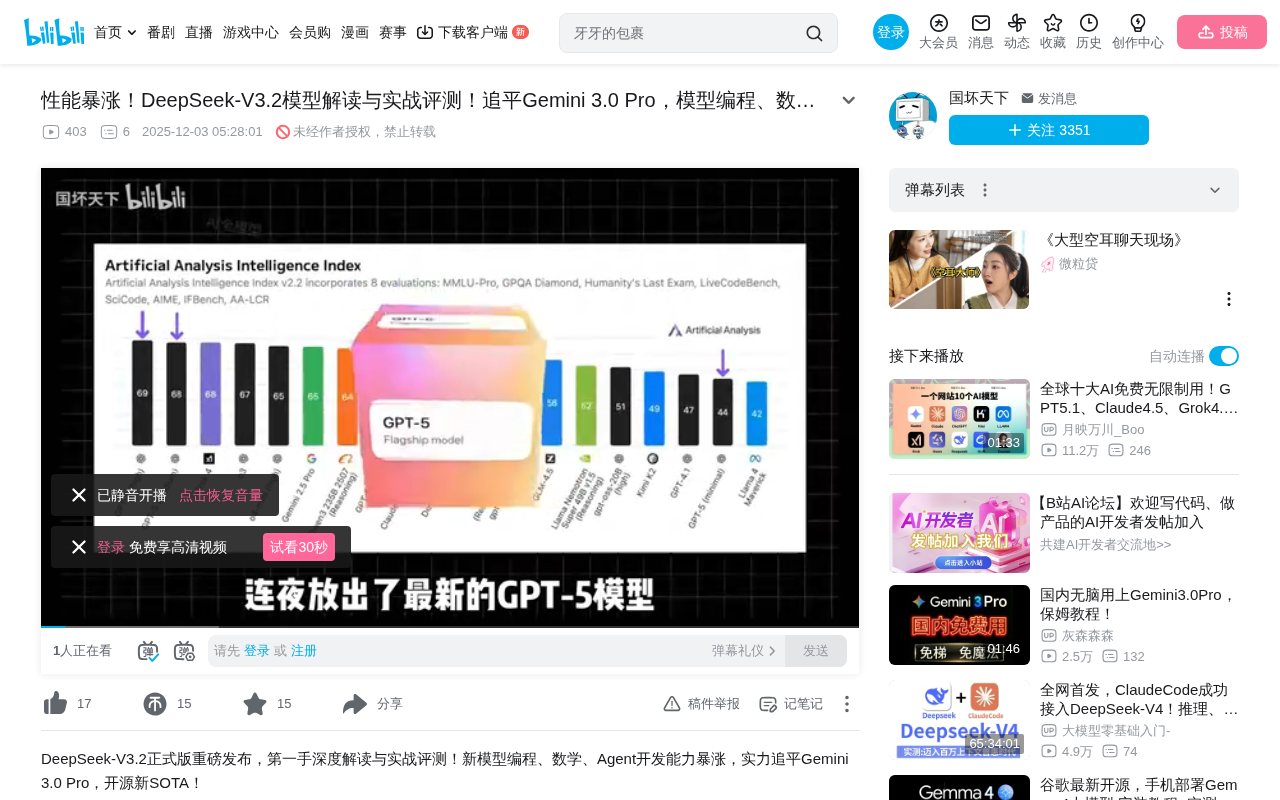
DeepSeek-V3.2 Technical Architecture Background
The DeepSeek model series adopts a Mixture of Experts (MoE) architecture—a technical approach that achieves efficient scaling through conditional computation. The core idea behind MoE is distributing model parameters across multiple "expert" sub-networks, activating only a subset of experts during each inference pass. This maintains the knowledge capacity that comes with a large parameter count while significantly reducing actual computational overhead. The DeepSeek-V3 series reportedly has approximately 671 billion total parameters, but only activates around 37 billion parameters per inference, making it far more efficient than dense models of equivalent parameter scale. It is precisely this architectural advantage that enables DeepSeek to continuously iterate on model capabilities with limited computational resources, ultimately achieving a qualitative leap in the V3.2 version.
DeepSeek-V3.2 Performance Highlights
Major Leap in Coding Capabilities
DeepSeek-V3.2 has made significant progress in code generation and programming tasks. The DeepSeek series has consistently maintained its leading position among open-source models in the programming domain, and V3.2 further narrows the gap with top closed-source models.
In practical programming scenarios, the model better understands complex code logic, generates more accurate code snippets, and maintains code context consistency across multi-turn conversations. This has significant practical value for developers using AI-assisted programming in their daily work. Notably, coding capability evaluation typically involves multiple benchmark dimensions, including HumanEval (function-level code generation), MBPP (basic programming problems), SWE-bench (real software engineering tasks), and LiveCodeBench (competitive programming). DeepSeek-V3.2's comprehensive performance across these tests indicates that its code comprehension and generation capabilities have evolved from "can write code" to "can solve real engineering problems."
Enhanced Mathematical Reasoning
Mathematical reasoning is one of the core metrics for measuring the intelligence level of large language models. DeepSeek-V3.2's performance on math benchmarks has matched Gemini 3.0 Pro, meaning open-source models have reached new heights in logical reasoning and mathematical problem-solving.
Improvements in mathematical reasoning are typically closely related to the model's Chain-of-Thought (CoT) reasoning mechanism. Modern large models significantly improve their performance on complex math problems by learning to decompose problems step by step and verify intermediate steps during training. Commonly used math evaluation benchmarks include MATH (high school competition mathematics), GSM8K (elementary math word problems), and AIME (American Invitational Mathematics Examination problems). DeepSeek-V3.2 matching Gemini 3.0 Pro on these tests means it has achieved top-tier performance in symbolic reasoning, numerical computation, and formal proofs.
Improved Agent Development Capabilities
Agent (intelligent agent) development is a hot direction in current AI applications. DeepSeek-V3.2's improvements in tool calling, multi-step reasoning, and task planning—core Agent capabilities—make it a strong choice for building AI Agent applications. For developers looking to build automated workflows based on open-source models, this is significant good news.
An AI Agent refers to an AI system capable of autonomously perceiving its environment, formulating plans, and executing multi-step operations to complete complex tasks. Unlike traditional single-turn Q&A, Agents need to possess core capabilities including Tool Use, Task Decomposition, Memory Management, and Self-Reflection. Current mainstream Agent frameworks include LangChain, AutoGPT, CrewAI, and others, all of which rely on the underlying large model's function calling and multi-step reasoning capabilities. A model's performance on Agent benchmarks (such as BFCL, τ-bench, etc.) directly determines its reliability as the Agent's "brain." DeepSeek-V3.2's breakthrough in these capabilities means developers can build Agent systems based on open-source models that rival those powered by GPT-4o.
Significance for the Open-Source Ecosystem
The Value of a New Open-Source SOTA
The significance of DeepSeek-V3.2 reaching this level as an open-source model goes beyond the performance numbers themselves:
- Lowering barriers to entry: Developers and enterprises can freely deploy and fine-tune the model without relying on closed-source APIs
- Driving industry competition: Progress in open-source models pushes closed-source models to continuously innovate
- Data security assurance: Local deployment solutions provide viable options for scenarios with data privacy requirements
SOTA (State-of-the-Art) here refers to the best technical level achieved in a given field at a specific point in time. In AI research, setting a new SOTA means surpassing the highest scores of all previously published models on recognized benchmarks. It's important to distinguish that the open-source SOTA and the overall SOTA are two different concepts—the former only counts models whose weights are publicly downloadable, while the latter includes all closed-source commercial models. DeepSeek-V3.2 setting a new open-source SOTA while matching some closed-source models' performance marks an accelerating convergence of these two lines.
The Global AI Model Competition Landscape
The current global AI model competition is extremely intense. OpenAI's GPT series, Google's Gemini, Anthropic's Claude, and xAI's Grok are all iterating rapidly. DeepSeek-V3.2's ability to join the top tier in such a competitive environment demonstrates the technical prowess of Chinese AI research teams.
The open-source vs. closed-source debate in the large model space is one of the most critical structural issues in the industry today. The closed-source camp is represented by OpenAI (GPT-4o/o3), Anthropic (Claude 4), and Google (Gemini), commercializing through paid API models; the open-source camp is represented by Meta (Llama series), DeepSeek, Mistral, Alibaba (Qwen), and others, driving community ecosystems by opening model weights. The advantages of open-source models lie in local deployment, customizable fine-tuning, and no vendor lock-in, but they previously lagged behind closed-source models by one to two generations in absolute performance. DeepSeek-V3.2's breakthrough is rewriting this narrative, proving that there is no insurmountable ceiling for the open-source approach.
Gemini is a multimodal large model series from Google DeepMind, with 3.0 Pro being the latest generation version targeting developers and high-performance applications, positioned between the lightweight Flash version and the flagship Ultra version. Gemini 3.0 Pro excels in reasoning capabilities, long-context processing, and tool calling, and is widely regarded as a top-tier product among closed-source models. DeepSeek-V3.2 matching this level means the open-source community has, for the first time, touched the ceiling of top closed-source models in comprehensive capabilities.
Practical Usage Recommendations
Applicable Scenarios
Based on DeepSeek-V3.2's capability improvements, the following scenarios deserve special attention:
- Code development assistance: Code generation, debugging, and refactoring for complex projects
- Mathematics and research: Mathematical proofs, data analysis, scientific computing
- Agent application development: Automated workflows, intelligent assistant building
- General conversation: Daily Q&A, content creation, knowledge retrieval
Deployment Options
Users can experience the V3.2 model through DeepSeek's official API, open-source community deployment, or third-party platforms. For individual developers, it's recommended to first evaluate through the official platform, then decide whether to proceed with local deployment based on actual needs.
Regarding local deployment, since DeepSeek-V3.2 uses a MoE architecture with a massive total parameter count, full deployment has high hardware requirements, typically requiring clusters of multiple high-end GPUs (such as NVIDIA A100/H100). However, the community has developed various quantization schemes (such as GPTQ, AWQ, GGUF formats) that can significantly reduce VRAM requirements with some precision loss. For developers with limited resources, efficient inference frameworks like vLLM and SGLang can be used to optimize deployment efficiency, or tools like Ollama can run quantized versions on consumer-grade hardware for initial experimentation.
Conclusion
The release of DeepSeek-V3.2 marks another major step forward for open-source large models in core capabilities. Matching or even surpassing some closed-source models across three key dimensions—coding, math, and Agent development—has a positive driving effect on the entire AI industry's development. As the gap between open-source and closed-source models continues to narrow, developers will have more quality options, and the innovation space for AI applications will further expand.
From a broader perspective, DeepSeek-V3.2's success also validates an important technical pathway: through ingenious architectural design (MoE), efficient training strategies, and continuous engineering optimization, world-class large language models can be trained even under relatively constrained computational resources. This provides an extremely valuable reference for the global AI research community, especially for teams facing compute constraints.
Key Takeaways
- DeepSeek-V3.2 joins the global top tier in coding, math, and Agent development capabilities
- Model performance reportedly matches Gemini 3.0 Pro, setting a new open-source model SOTA record
- Open-source models reaching top-tier levels is significant for lowering AI barriers and driving industry competition
- Applicable to multiple scenarios including code development assistance, mathematical research, and Agent application development
- The MoE architecture enables efficient inference while maintaining a large parameter count, representing the core advantage of DeepSeek's technical approach
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.