DeepSeek V3.2深度解读:DSA稀疏注意力、强化学习与Agent三大突破

DeepSeek V3.2发布,凭借三大技术突破达到GPT-5级别水平
DeepSeek发布V3.2和V3.2 Special两款模型,前者为平衡型日常模型达GPT-5水平,后者为极致推理版本在多项数学竞赛中排名世界第一。核心技术突破包括:DSA稀疏注意力机制大幅提升长文本处理效率、将强化学习计算量提升至预训练的10%持续提升推理能力、以及构建1800种环境的大规模Agent任务合成实现"边思考边调用工具"的创新能力。
DeepSeek近日突然发布了两款新模型——DeepSeek V3.2和DeepSeek V3.2 Special。虽然版本号看似只是小幅迭代,但从官方评测数据来看,这两款模型的实力已足以媲美GPT-5、对标Gemini 3.0 Pro。本文将从官方发布信息、论文技术细节和实际测试三个维度,全面拆解DeepSeek V3.2的核心技术突破。
DeepSeek V3.2与V3.2 Special:两款模型的定位与能力差异
DeepSeek此次发布的两款模型有着明确的差异化定位。DeepSeek V3.2是一个平衡型的日常使用模型,目前已在官方网页版、App及API全面上线,综合能力达到GPT-5水平,仅略低于Gemini 3.0 Pro,相比国内其他开源大模型则有明显优势。
DeepSeek V3.2 Special则是一个极致推理版本,目前仅通过API提供服务,更适合开发者使用。这个版本在美国数学邀请赛(AMC/AIME)、哈佛MIT数学竞赛以及国际数学奥林匹克竞赛等多个顶级竞赛指标上,均达到了世界第一的水平,甚至超过了GPT-5和Gemini 3.0 Pro。值得一提的是,该模型并未针对这些竞赛任务做过定向训练,这意味着其推理能力是真实的泛化能力,而非过拟合的结果。
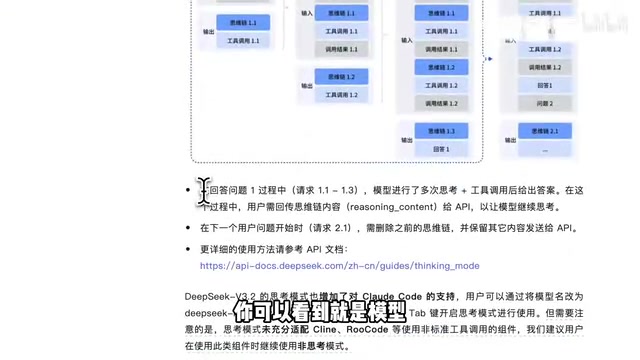
两款模型都延续了DeepSeek一贯的开源传统。此外,V3.2还有一个值得关注的特性——边思考边调用工具的能力,这在以往任何模型中都未曾出现。模型可以在思维链推理过程中穿插使用搜索、爬虫等工具,多次交替思考与检索后再给出最终答案。
技术背景:Agent与工具调用的范式演进 大模型的工具调用能力(Tool Use / Function Calling)最早由OpenAI在2023年的GPT-4 API中系统化引入,允许模型以结构化JSON格式调用外部函数。然而早期实现中,思维链推理(Chain-of-Thought)与工具调用是严格串行的:模型先完成一段推理,再决定是否调用工具,调用完成后再继续推理。这种模式在复杂任务中会导致推理路径僵化,模型无法根据工具返回的中间结果动态调整思考方向。DeepSeek V3.2实现的"边思考边调用工具"本质上是将ReAct(Reasoning + Acting)框架与深度思维链进行了原生融合,使工具调用成为推理过程的内生组成部分,而非外挂的后处理步骤。这与Anthropic在Claude中探索的"扩展思考+工具使用"方向高度一致,代表了Agent架构的重要演进方向。
三大核心技术突破详解
从DeepSeek V3.2的论文来看,这次升级主要有三个关键技术创新,分别在注意力机制、强化学习和Agent能力上实现了突破。
DSA稀疏注意力机制:让长文本处理更快更准
长文本处理一直是大模型的性能瓶颈。传统注意力机制要求每个token都与上下文中所有其他token进行交互,计算复杂度呈二次方增长——就像一个派对上,每个新来的人都要和在场所有人握手,100个人就需要近5000次握手。
技术背景:注意力机制的O(n²)困境 Transformer架构中的自注意力机制(Self-Attention)自2017年提出以来一直是大语言模型的核心组件,但其O(n²)的计算复杂度始终是制约长文本处理的根本瓶颈。具体而言,对于长度为n的序列,标准注意力需要计算n×n的注意力矩阵,当上下文窗口从4K扩展到128K甚至更长时,显存占用和计算时间呈平方级爆炸。学界为此提出了多种稀疏化方案,包括Longformer的滑动窗口注意力、BigBird的随机+局部+全局混合注意力,以及FlashAttention系列的IO感知优化。DSA的创新之处在于引入了动态的重要性感知选择机制,而非静态的位置模式,使稀疏化更贴近实际语义需求,从而在速度与精度之间取得了更优的平衡。
DeepSeek提出的DSA(DeepSeek Sparse Attention)稀疏注意力机制采用了一种"只和重要的人握手"的策略。模型先通过快速扫描(论文中称为Lightning Attention),识别出最关键的token,然后只与这些关键token进行深度交互。这样每个token可能只需要与20个重要token交互,总计算量大幅下降。
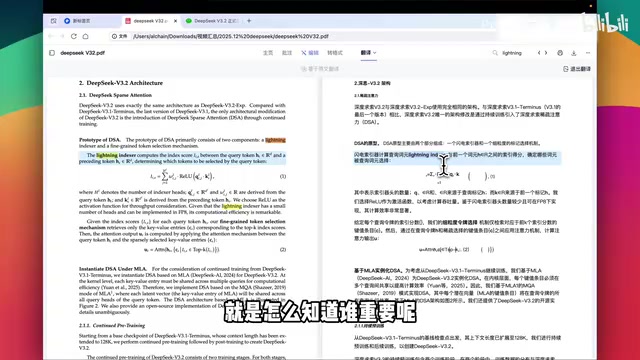
训练过程分为两步:第一步是"教门童看人"——先用完整的注意力机制跑一遍,找出真正重要的token,然后用这些结果训练一个轻量级的选择器;第二步是"门童和主人各干各的"——选择器和主模型分开训练,避免互相干扰。
一个反直觉的发现是:DSA稀疏注意力不仅更快,在某些任务上甚至更准。原因在于很多token实际上是"干扰项",与当前推理无关,跳过它们反而让模型更专注于有效信息。
可扩展的强化学习框架:后训练计算量达预训练的10%
DeepSeek的另一个核心竞争力在于大规模强化学习。他们将后训练(Post-Training)阶段的强化学习计算量提升到了预训练的10%左右,而大多数公司这一比例仅为1%-5%。
技术背景:RL在大模型后训练中的演进 强化学习用于语言模型对齐(Alignment)的历史可追溯至OpenAI 2022年提出的RLHF(基于人类反馈的强化学习),其核心思路是训练一个奖励模型来模拟人类偏好,再用PPO算法优化语言模型。然而RLHF存在奖励模型不稳定、训练成本高昂等问题。DeepSeek此前在R1系列中率先大规模采用GRPO(Group Relative Policy Optimization)算法,绕过了独立奖励模型的需求,直接通过规则验证(如数学答案正确性)提供奖励信号。将后训练RL计算量提升至预训练的10%,意味着在数千张GPU上持续运行数周的额外训练,这对训练稳定性、奖励设计和基础设施的要求极高,也是为何大多数实验室难以在同等规模上复制这一能力的根本原因。
DeepSeek观察到一个重要规律:持续增加强化学习的计算资源,就能持续提升模型性能,而且目前还没有到达天花板。他们的假设是,推理能力可以通过进一步增加计算预算获得更多提升。这种"敢于在RL上重注投入并保持训练稳定"的能力,是很多其他公司难以复制的技术壁垒。
大规模Agent任务合成:1800种环境×85000条复杂指令
为了训练模型的"边思考边用工具"能力,DeepSeek构建了一套大规模的Agent任务合成流水线,包含1800种环境和85000种以上的复杂指令。
其核心设计理念是"Hard to solve, but easy to verify
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。