Fireworks AI上线Qwen 3.7 Plus:零数据留存与99.9% SLA企业级部署
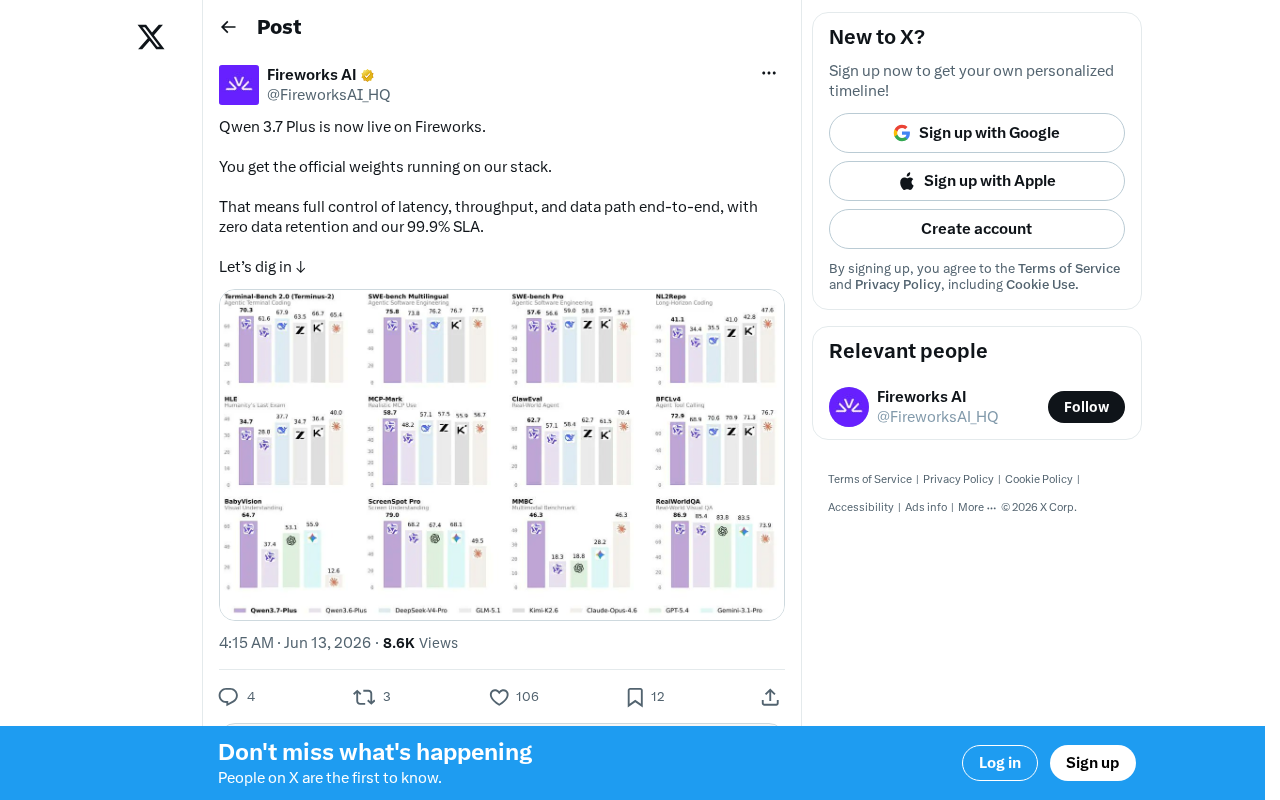
Qwen 3.7 Plus登陆Fireworks平台
Fireworks AI近日宣布,Qwen 3.7 Plus模型已正式在其平台上线。用户可以直接使用官方权重,在Fireworks的基础设施栈上运行这一最新模型。
Qwen 3.7 Plus是阿里巴巴通义千问团队推出的最新一代大语言模型,采用了Mixture of Experts(MoE,混合专家)架构,总参数量达到约3090亿,但在推理时仅激活其中约450亿参数。这种架构设计使得模型在保持极高能力上限的同时,推理计算成本远低于同等总参数规模的稠密模型。在多项公开基准测试中,Qwen 3.7 Plus的表现已经接近甚至超越了部分闭源商业模型,尤其在代码生成、数学推理和多语言理解等任务上表现突出。
Fireworks AI是一家专注于AI模型推理服务的基础设施公司,由前Meta PyTorch团队核心成员Lin Qiao于2022年创立。公司的核心技术优势在于其自研的推理引擎FireAttention,该引擎针对Transformer架构进行了深度优化,能够在保持模型精度的前提下大幅提升推理效率。Fireworks的定位并非训练平台,而是专注于将开源模型以最优性能交付给企业用户,这使其在推理即服务(Inference-as-a-Service)赛道中形成了鲜明的差异化定位。
核心亮点:端到端全链路可控
Fireworks此次上线Qwen 3.7 Plus,强调的核心卖点是端到端的全链路控制能力,具体包括以下几个方面:
延迟与吞吐量精细化调控
对于生产环境中的AI应用而言,延迟和吞吐量是两个至关重要的性能指标。Fireworks平台允许用户对这两个参数进行精细化调控,开发者可以根据具体业务场景——无论是实时对话还是批量处理——灵活调整模型的推理配置,以达到最优的性价比。
在大语言模型推理场景中,延迟通常被细分为两个关键指标:首Token延迟(Time to First Token, TTFT)和生成速度(Tokens Per Second, TPS)。TTFT衡量的是用户发出请求到收到第一个输出Token之间的等待时间,直接影响用户的感知响应速度;TPS则衡量模型持续生成文本的速率,决定了长文本输出场景下的用户体验。吞吐量(Throughput)则从系统层面衡量单位时间内平台能够处理的总请求数或总Token数。在实际生产中,延迟和吞吐量之间往往存在权衡关系——更激进的批处理(batching)策略可以提升吞吐量,但可能增加单个请求的延迟。Fireworks允许用户根据业务优先级在这两个维度之间进行精细调节,例如实时聊天场景优先保障低延迟,而离线数据处理场景则可以牺牲部分延迟来换取更高的吞吐量和更低的单位成本。
对于Qwen 3.7 Plus这样的MoE架构模型,推理优化面临着独特的技术挑战。MoE模型在推理时需要通过门控网络(Gating Network)动态选择激活哪些专家模块,这一路由过程本身会引入额外的计算开销和内存访问模式的不确定性。同时,虽然每次推理仅激活约450亿参数,但全部3090亿参数仍需加载到显存或通过高速互联在多卡之间分布,这对GPU显存管理和卡间通信带宽提出了很高要求。Fireworks的自研推理引擎FireAttention针对这类稀疏激活架构进行了专门优化,包括专家并行(Expert Parallelism)策略和智能的KV Cache管理,使得MoE模型能够在其平台上获得接近理论最优的推理效率。
零数据留存:数据安全与隐私保障
Fireworks明确承诺**零数据留存(Zero Data Retention)**策略。在企业对数据隐私和合规性要求日益严格的背景下,这一特性尤为关键。用户的输入数据和模型输出不会被平台保留,数据路径端到端可控,对于金融、医疗、法律等数据敏感度极高的行业来说,这是选择AI推理服务商时的核心考量因素。
零数据留存策略的技术实现通常涉及多个层面:在传输层,所有API请求和响应通过TLS加密传输;在计算层,推理过程中的中间状态(包括KV Cache等临时数据)在请求完成后立即从GPU显存和系统内存中清除;在存储层,平台不将任何用户的prompt或模型输出写入持久化存储。这一策略直接回应了企业在使用第三方AI服务时最核心的顾虑——数据是否会被用于模型再训练或被第三方访问。在全球范围内,欧盟的《通用数据保护条例》(GDPR)、美国的《健康保险可携性和责任法案》(HIPAA)以及中国的《数据安全法》等法规都对数据处理和留存提出了严格要求。零数据留存策略使得企业在使用Fireworks托管的Qwen 3.7 Plus时,能够更容易地满足这些合规框架的要求,降低法律和监管风险。
99.9% 企业级SLA保障
Fireworks为Qwen 3.7 Plus提供99.9%的服务等级协议(SLA)。这一承诺意味着每年的计划外停机时间不超过约8.76小时,对于需要高可用性的生产级应用来说,是一个相当可靠的保障水平。
值得注意的是,SLA中的"99.9%"(通常称为"三个九")在云服务行业是一个标准的企业级可用性承诺。作为对比,"四个九"(99.99%)意味着每年停机时间不超过约52.6分钟,通常只有核心云基础设施服务(如AWS S3、Google Cloud Spanner)才会提供这一级别的保障。对于AI推理服务这一相对新兴的领域,99.9%的SLA已经表明Fireworks将其定位为可用于关键业务流程的生产级服务,而非仅供实验和原型开发的工具。SLA通常还附带服务信用(Service Credit)条款,即当平台未能达到承诺的可用性水平时,用户可以获得相应的费用减免,这为企业提供了额外的财务保障。
行业趋势:开源模型的商业化推理竞争加剧
此次Fireworks上线Qwen 3.7 Plus,折射出当前AI基础设施领域的一个重要趋势:围绕开源模型的商业化推理服务竞争正在加剧。
随着Qwen、Llama、DeepSeek等开源模型的能力不断提升,模型本身不再是唯一的竞争壁垒。真正的差异化开始转向推理层面——谁能提供更低的延迟、更高的吞吐量、更强的安全保障以及更灵活的部署选项,谁就能在这场竞争中占据优势。
Fireworks、Together AI、Groq等推理平台正在围绕这些维度展开激烈角逐。Fireworks选择在第一时间支持Qwen 3.7 Plus,并以官方权重加全栈控制作为卖点,显然是希望在开源模型的企业级部署市场中抢占先机。
这些竞争者各自采取了不同的差异化策略。Together AI侧重于提供从微调到推理的完整工作流,允许用户在其平台上对开源模型进行定制化训练后直接部署,形成了"训练-推理一体化"的闭环体验。Groq则走了一条截然不同的硬件路线——其自研的LPU(Language Processing Unit)芯片专为大语言模型推理设计,通过确定性计算架构实现了极低的推理延迟,在速度基准测试中频频刷新纪录,但其硬件供应的扩展性仍是市场关注的焦点。此外,Cerebras凭借其晶圆级芯片WSE(Wafer Scale Engine)也在推理速度上展现了惊人的性能。而传统云厂商如AWS(通过Bedrock)、Google Cloud(通过Vertex AI)和Azure也在积极将开源模型纳入其托管服务体系,凭借既有的企业客户关系和全球基础设施网络参与竞争。
这场竞争的本质是AI产业价值链的重新分配。当模型层趋向开源和同质化时,价值开始向推理基础设施层和应用层两端迁移。推理平台通过在性能优化、安全合规、开发者体验等方面建立差异化优势,正在成为连接开源模型与企业应用之间不可或缺的中间层。
对开发者和企业的实际意义
对于希望在生产环境中使用Qwen 3.7 Plus的开发者和企业来说,Fireworks提供了一个开箱即用的托管方案。相比自建推理基础设施,使用托管服务可以显著降低运维成本和工程复杂度,同时获得企业级的可靠性保障。
自建Qwen 3.7 Plus推理服务的门槛不容小觑。以其3090亿总参数的MoE架构为例,即使采用FP8量化,完整加载模型权重也需要数百GB的GPU显存,通常需要多台配备高端GPU(如NVIDIA H100或A100)的服务器通过高速NVLink或InfiniBand互联组成推理集群。除硬件成本外,团队还需要掌握模型并行(Tensor Parallelism、Pipeline Parallelism、Expert Parallelism)、动态批处理、KV Cache优化、量化部署等一系列复杂的工程技术,并持续投入人力进行系统监控、故障恢复和性能调优。对于大多数企业而言,这些投入的总拥有成本(TCO)远高于使用托管推理服务的费用。
不过,开发者在选择AI推理平台时仍需综合考虑定价策略、区域覆盖、与现有技术栈的兼容性等因素,做出最适合自身业务需求的决策。特别是在定价方面,不同平台对MoE模型的计费方式存在差异——有些按激活参数量计费(更接近实际计算成本),有些则按总参数量计费,这会显著影响最终的使用成本。此外,是否支持函数调用(Function Calling)、结构化输出(Structured Output)、长上下文窗口等高级功能,以及API的兼容性(是否兼容OpenAI API格式)等细节,也是技术选型时需要仔细评估的要素。
核心要点
相关推荐
GML 5.2多模态升级实测:DeepSeek V4全面跑通验证
基于OneBlockBase平台实测GML 5.2与DeepSeek V4多模态升级,详解视觉识别与文本协同工作流搭建、前置拦截安全机制、界面生成效果及部署配置要点,验证纯文本模型通过工作流编排升级多模态的可行方案。
DeepSeek+Cline配置教程:10元替代月费20美金的AI编程方案
详解DeepSeek API搭配VS Code插件Cline的完整配置流程,包括API Key获取、Plan/Act双模型策略、项目管理文件体系等进阶技巧,10元充值即可获得接近顶尖水平的AI编程体验。
5步让Codex接入DeepSeek,无需GPT账号也能用
详细图文教程:通过CC Switch中转工具,5步将Codex接入DeepSeek API,无需GPT账号即可使用AI编程助手的全部功能,包括代码补全、技能插件等,成本更低体验无损。