Gemini 3.5 Flash Surpasses Pro in Vision Capabilities, 6x Faster Inference
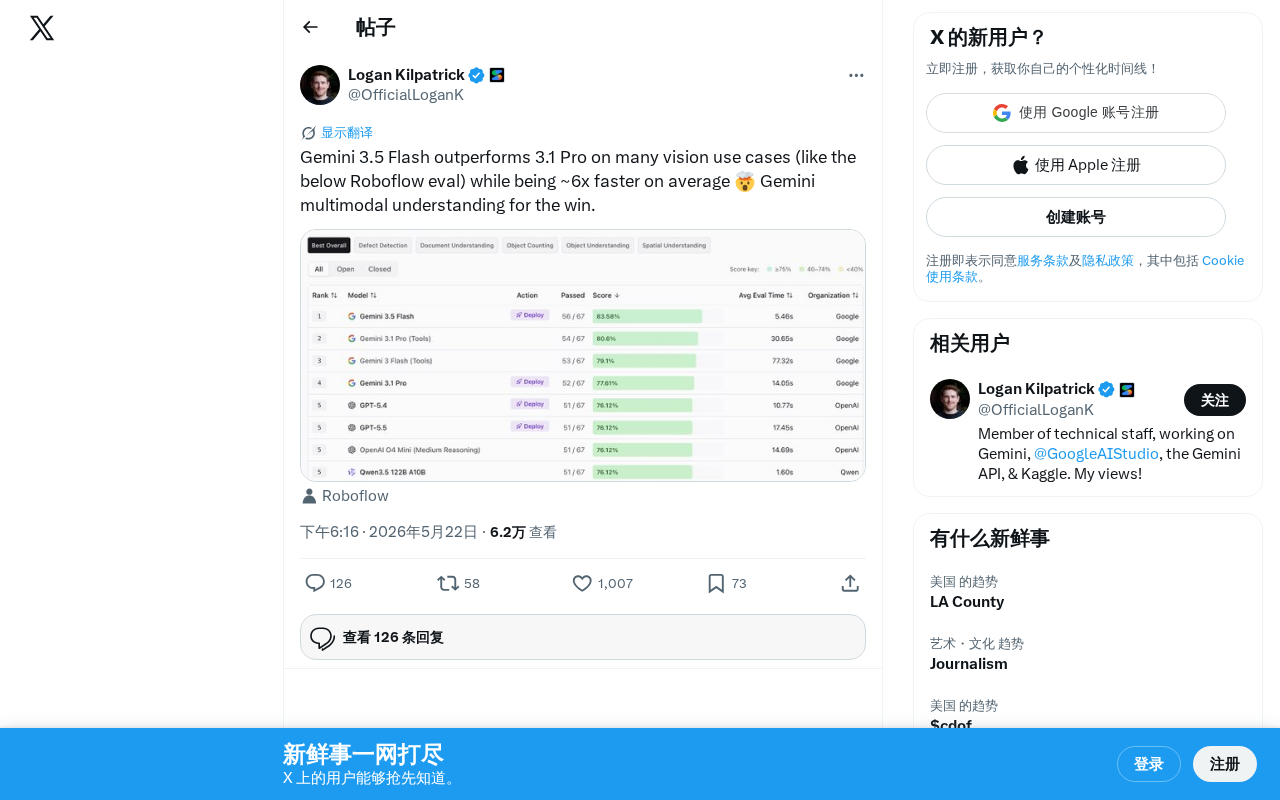
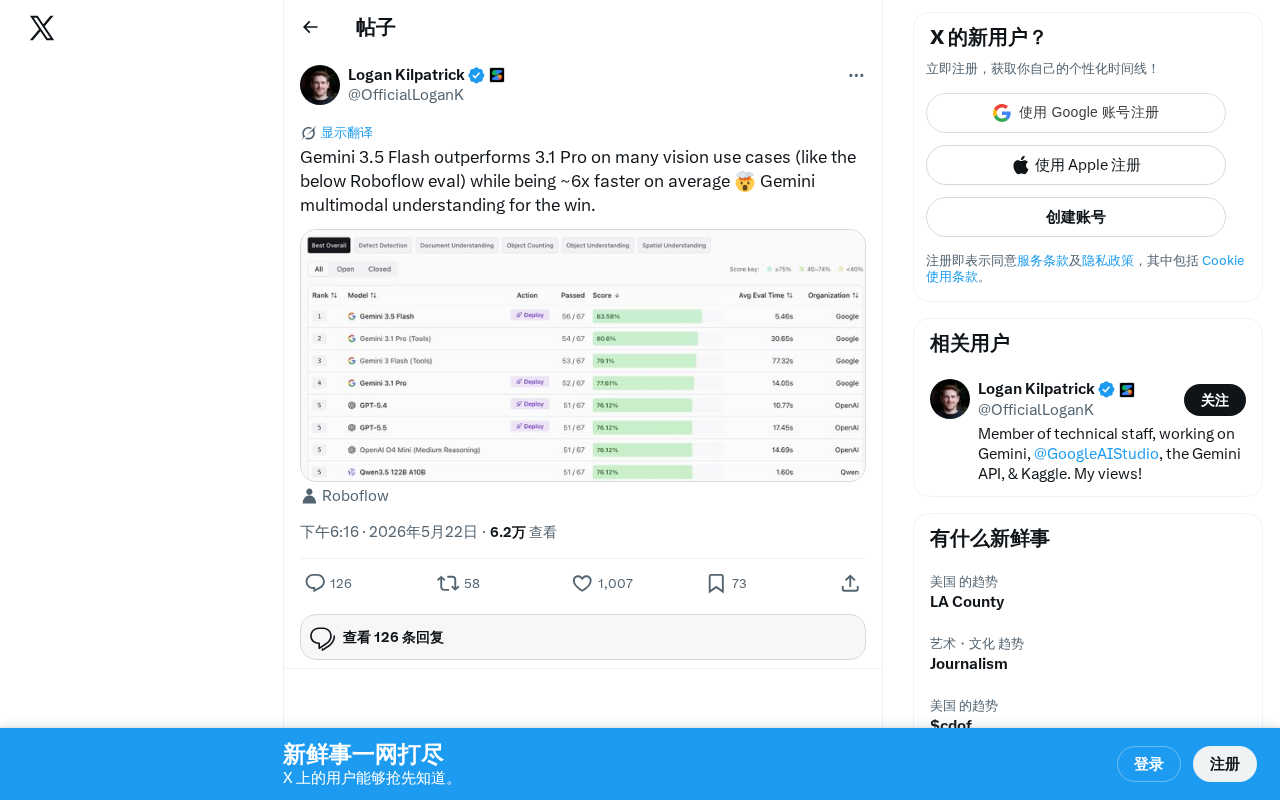
Gemini 3.5 Flash outperforms the previous-gen flagship Pro model on vision tasks with 6x faster speed
Google's newly released Gemini 3.5 Flash lightweight model outperforms the previous-generation flagship Gemini 3.1 Pro in Roboflow's vision benchmarks while achieving approximately 6x faster inference speed. This breaks the conventional wisdom that "bigger models mean better performance," delivering a rare win-win in both capability and speed, and offering developers a high-performance, low-cost vision AI solution.
Core Finding: Flash Model Outperforms Pro
Google's newly released Gemini 3.5 Flash delivers outstanding performance across multiple visual understanding tasks. According to evaluation data from Roboflow, it actually outperforms the previous-generation flagship model Gemini 3.1 Pro on many vision use cases, while averaging approximately 6x faster inference speed.
This result has surprised the industry—typically, Flash (lightweight) models are expected to underperform Pro (flagship) models in capability, but Gemini 3.5 Flash has broken this convention. To understand the significance of this upset, it helps to know that Google's Gemini model family uses a tiered naming strategy: Ultra for maximum performance, Pro for flagship-level balance, Flash for lightweight high-speed inference, and Nano for on-device deployment. This tiered logic is similar to product line segmentation in the chip industry, with each tier showing significant differences in parameter scale, compute requirements, and inference latency. Flash models typically learn from larger teacher models through Knowledge Distillation, achieving near-large-model capabilities with fewer parameters. They're designed for latency-sensitive production environments requiring high-concurrency API calls. This makes Flash outperforming Pro all the more remarkable.
A Major Breakthrough in Multimodal Visual Understanding
Cross-Generational Leap in Vision Capabilities
Gemini 3.5 Flash's performance on vision tasks is particularly impressive. Roboflow, as a well-known platform in the computer vision field, provides evaluations with high reference value. Serving over 500,000 developers with a full-pipeline toolchain from data annotation to model training and deployment, Roboflow's evaluations typically cover multiple dimensions including Object Detection, Image Classification, OCR, and Visual Question Answering (VQA), using real-world datasets rather than synthetic benchmarks—making their results highly relevant to practical application scenarios.
The evaluation results show that 3.5 Flash not only has a significant speed advantage but also achieves a qualitative leap in visual understanding accuracy. This indicates that Google has made important advances in model architecture optimization and training strategies, compressing stronger visual understanding capabilities into a smaller model footprint. Specifically, several key technical breakthroughs may be involved: Mixture of Experts (MoE) architecture allows the model to activate only a subset of parameters during inference, dramatically reducing computational cost; improved visual encoders (such as more efficient Vision Transformer variants) can represent image information with fewer tokens; improvements in training data quality and Curriculum Learning strategies can also significantly boost model data efficiency. Additionally, Google's deep expertise in TPU hardware-software co-optimization enables models to fully exploit hardware parallelism during inference.
Winning on Both Speed and Performance
Conventionally, AI model performance and inference speed are seen as a trade-off—larger models mean stronger capabilities but slower responses. However, Gemini 3.5 Flash achieves a rare "win-win":
- Performance gains: Outperforms Gemini 3.1 Pro on visual understanding tasks
- Speed advantage: Approximately 6x faster average inference speed
- Cost efficiency: Flash versions are typically priced lower, suitable for large-scale deployment
A 6x inference speed improvement carries engineering significance far beyond the number itself: the same hardware resources can serve 6x the concurrent requests, and end-to-end API call latency drops from seconds to hundreds of milliseconds, enabling latency-sensitive scenarios like real-time video analysis and interactive document processing. From a cost perspective, faster inference directly reduces GPU time consumption per API call. Combined with Flash's inherently lower pricing strategy (typically 1/5 to 1/10 of Pro pricing), total usage costs may decrease by more than an order of magnitude. This is particularly critical for e-commerce platforms, security systems, and autonomous driving data annotation pipelines that need to process massive volumes of images.
Industry Impact
Practical Value for Developers
For developers and enterprises, this result means that when building vision AI applications, they no longer need to make difficult trade-offs between performance and cost. Whether for document understanding, image analysis, video processing, or multimodal retrieval, Gemini 3.5 Flash offers an extremely cost-effective option.
Shifting Competitive Landscape in Multimodal AI
This also intensifies competition in the multimodal AI space. The 2024-2025 multimodal AI competition has reached a fever pitch: OpenAI's GPT-4o achieves native multimodal fusion across text, images, and audio; Anthropic's Claude 3.5 Sonnet excels in document understanding and code generation; Meta's Llama series continues pushing forward in open-source multimodal capabilities. Google's differentiation strategy leverages its massive multimodal data advantage accumulated through its search engine, along with training efficiency gains from its custom TPU chips.
The success of the Flash series demonstrates that the competitive focus is shifting from "who has the largest model" to "who can deliver optimal performance at the lowest cost." This trend will profoundly impact the business model of AI infrastructure—cloud providers need to rethink pricing strategies, while application developers gain unprecedented cost flexibility.
Conclusion
Gemini 3.5 Flash's performance validates a trend: AI model evolution is no longer simply about "bigger is better," but about finding optimal balance points among efficiency, speed, and performance. This trend is known in academia as "Scaling Efficiency"—maximizing model capability within a fixed compute budget rather than endlessly expanding model scale. For application scenarios requiring vision AI capabilities, Gemini 3.5 Flash is undoubtedly one of the most noteworthy options available today.
Key Takeaways
- Gemini 3.5 Flash outperforms the previous-generation flagship Gemini 3.1 Pro in Roboflow's vision evaluations
- Inference speed is approximately 6x faster on average, achieving a win-win in both performance and speed
- A lightweight Flash model surpassing a flagship Pro model breaks the traditional assumption that model size correlates with performance
- For developers, this means vision AI applications can achieve both high performance and low cost simultaneously
- The improvement in multimodal understanding reflects Google's technical breakthroughs in model architecture optimization
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.