Gemini 3.5 Flash Tops the Vending Bench Cost-Efficiency Frontier

Gemini 3.5 Flash reaches cost-intelligence Pareto optimality on the Vending Bench benchmark
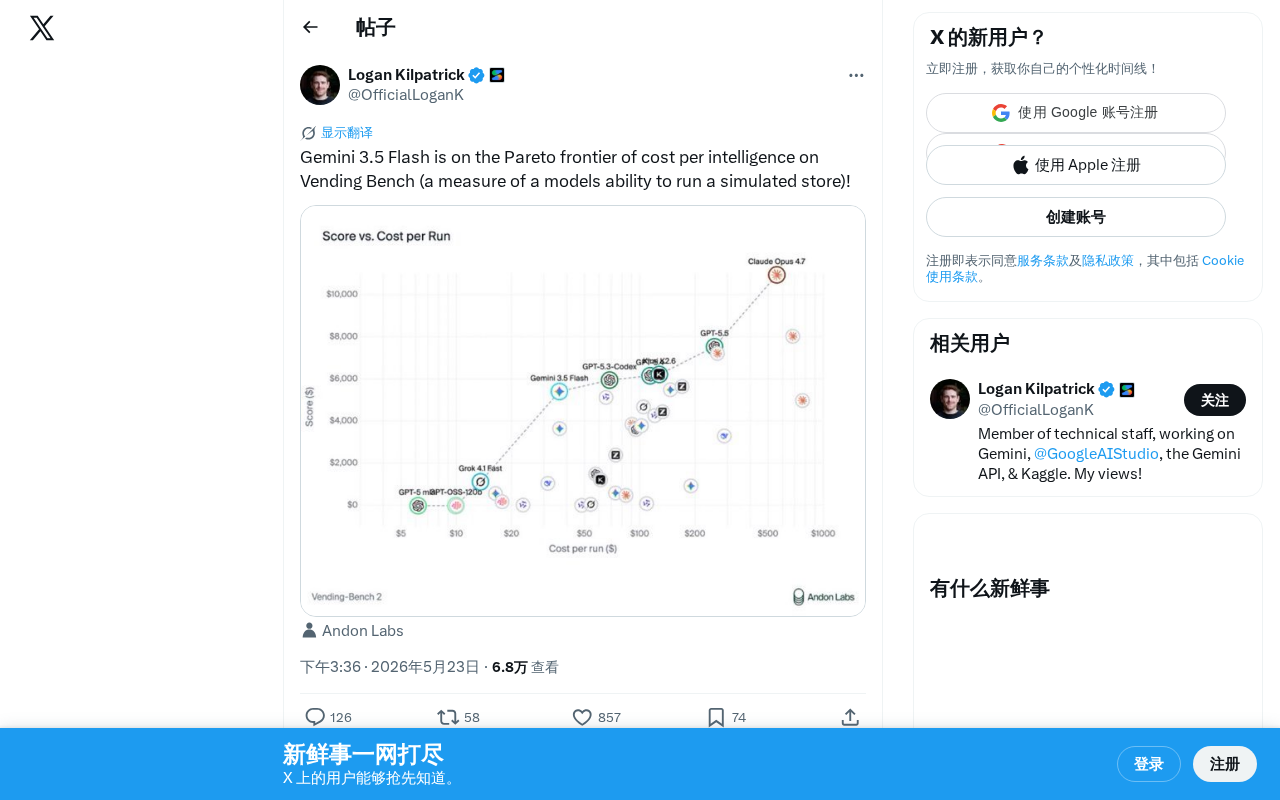
Google's Gemini 3.5 Flash model has reached the "cost-intelligence" Pareto Frontier on the Vending Bench benchmark, which simulates store operations—meaning no other model offers better intelligence at the same cost, or lower cost at the same intelligence level. This is enabled by technical optimizations including knowledge distillation and Sparse Mixture of Experts architecture, reflecting the AI industry's shift from pure performance competition to cost-efficiency competition.
Gemini 3.5 Flash Achieves Pareto Optimality in Cost-Efficiency
Google's newly released Gemini 3.5 Flash model has delivered impressive results on the Vending Bench benchmark, successfully reaching the "cost-intelligence" Pareto Frontier and demonstrating a highly competitive cost-performance advantage.
What Is Vending Bench?
Vending Bench is a benchmark that measures an AI model's ability to operate a simulated store. Unlike traditional academic benchmarks, it simulates real-world business operations, requiring models to demonstrate comprehensive capabilities across multiple dimensions including inventory management, pricing strategy, and customer interaction. These practical benchmarks are gaining increasing attention in the industry because they better reflect how models perform in real-world applications.
From a technical classification standpoint, Vending Bench falls under the category of next-generation "Agent Benchmarks." Traditional benchmarks like MMLU (Massive Multitask Language Understanding) and HumanEval (code generation evaluation) primarily test a model's knowledge base or single-task capabilities, whereas Agent Benchmarks require models to make continuous decisions in a persistently running environment, involving state tracking, long-term planning, and dynamic responses. The store operation scenario simulated by Vending Bench requires models to handle complex variables such as supply chain fluctuations, seasonal demand changes, and competitor pricing—challenges that closely mirror what LLMs face in enterprise-level applications. The rise of such benchmarks reflects the industry's shift in focus from "what a model knows" to "what a model can do."
The Significance of the Pareto Frontier
What Is the Pareto Frontier?
In multi-objective optimization, the Pareto Frontier represents a set of "non-dominated" optimal solutions—meaning one metric cannot be further improved without sacrificing another. In this context, the two key dimensions are:
- Cost: API fees per call
- Intelligence level: The model's score on Vending Bench
Being on the Pareto Frontier means that at the same cost level, no other model can deliver higher intelligence, or at the same intelligence level, no cheaper option exists.
The concept of Pareto Optimality originates from the theories of Italian economist Vilfredo Pareto and was initially used to describe the efficiency state of resource allocation. In computer science, the Pareto Frontier is widely applied to multi-objective optimization problems, such as the trade-off between power consumption and performance in chip design, or the balance between latency and throughput in network architecture. The introduction of the Pareto Frontier in AI model evaluation marks a maturation of evaluation methodology—single leaderboards can no longer satisfy practical decision-making needs, and developers need to find the solution best suited to their specific scenario within a multi-dimensional constraint space. A model on the Pareto Frontier is a "non-dominated solution," meaning any attempt to surpass it in one dimension necessarily comes at a cost in another.
Practical Implications for Developers
This result carries significant implications for developers building AI-driven business applications. In real-world deployments, the balance between cost and performance is often the most critical decision factor. As a lightweight model in the Flash series, Gemini 3.5 Flash is inherently positioned as a high cost-efficiency solution, and its excellent performance on this practical benchmark further validates that positioning.
AI model API costs are typically charged per token, split across input tokens and output tokens. Taking the current market as an example, GPT-4o is priced at approximately $2.5/million input tokens and $10/million output tokens, while Flash-tier models are typically 5-10x cheaper. However, actual deployment costs go far beyond API call fees—one must also consider token consumption from prompt engineering, retry rates (how often the model needs to be re-called after failures), and the added system complexity required to compensate for model limitations. Therefore, the value of Pareto Frontier analysis lies in its comprehensive consideration of "how much you spend" and "how much intelligence you get," helping developers avoid the traps of "cheap but requiring extensive compensatory engineering" or "powerful but unsustainably expensive."
Technical Optimizations Behind the Flash Series
Google's Flash series models achieve their high cost-efficiency through multiple cutting-edge technical approaches. Core strategies include: Knowledge Distillation, which uses large model outputs as training signals to train smaller models, enabling them to inherit the reasoning patterns of larger models; Sparse Mixture of Experts (SMoE), which activates only a subset of parameters during inference to reduce computational overhead; and inference-time compute optimization, which reduces actual computational consumption per inference through more efficient attention mechanisms and KV cache strategies. These techniques enable Flash models to maintain performance close to—or even matching—Pro-tier models on specific tasks, while operating with significantly fewer parameters and at much lower computational costs.
Industry Trend: From Pure Performance Competition to Cost-Efficiency Competition
The current AI model competition has shifted from purely pursuing peak performance to a more pragmatic cost-efficiency dimension. Major providers have launched model series at different tiers:
- Google's Gemini series (Pro/Flash/Nano)
- OpenAI's GPT series (GPT-4o/GPT-4o-mini)
- Anthropic's Claude series (Opus/Sonnet/Haiku)
In this competition, "Flash"-tier mid-range models are becoming the workhorses of real-world applications. They maintain sufficient intelligence levels while dramatically reducing deployment costs, making AI applications economically viable in a much broader range of scenarios.
Behind the multi-tier product lines from major providers lies an architectural trend toward "Model Routing." In production environments, enterprises are increasingly adopting cascade strategies: simple queries are handled by lightweight models, while complex tasks are escalated to heavyweight models. This architecture can reduce overall costs by 60-80% while maintaining user experience. OpenAI's ChatGPT product internally employs a similar routing mechanism. In this context, the cost-efficiency performance of Flash-tier models directly determines what proportion of traffic they can handle, which in turn affects the economic viability of the entire system.
Conclusion
Gemini 3.5 Flash's Pareto-optimal performance on Vending Bench once again demonstrates Google's technical prowess in model efficiency optimization. For enterprises that need to deploy AI agents under cost constraints, models that balance both performance and economics will be the most pragmatic choice. As more practical benchmarks emerge, we'll be able to more comprehensively evaluate the overall competitiveness of various models in real business scenarios.
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.