GPT-5.5 Instant医疗问答能力追平前沿推理模型
GPT-5.5 Instant医疗问答能力追平前沿推理模型
每周2.3亿次健康咨询,OpenAI如何应对?
OpenAI近日宣布,GPT-5.5 Instant在健康相关问题上的表现已经追平其前沿Thinking模型。这一消息意义重大——ChatGPT每周有超过2.3亿人次使用它来咨询健康与养生问题,这个数字几乎相当于一个中等国家的人口规模。
值得解释的是,GPT-5.5 Instant属于OpenAI产品线中的轻量级快速响应模型,而Thinking模型(如o1、o3系列)则是具备深度推理能力的前沿模型,它们在回答前会进行多步骤的内部思考链(Chain of Thought)推理。Thinking模型通常在复杂推理任务上表现更优,但响应速度较慢且计算成本更高。GPT-5.5 Instant能在健康问答领域追平Thinking模型,意味着通过针对性训练和优化,轻量模型也能在特定垂直领域达到接近深度推理模型的表现水平,同时保持更快的响应速度和更低的运行成本。
当AI成为数亿人的"第一健康顾问",模型在医疗场景下的准确性和可靠性就不再只是技术指标,而是关乎公共健康的重大议题。
GPT-5.5 Instant的四大医疗能力提升
根据OpenAI披露的信息,GPT-5.5 Instant在健康问答领域实现了四个关键维度的显著进步:
紧急情况识别能力增强
模型现在能更好地识别用户描述中可能需要紧急医疗救治的信号。当用户描述胸痛、呼吸困难等危急症状时,模型能够更准确地判断严重程度,并及时建议用户寻求专业医疗帮助,而非仅仅给出一般性的健康建议。
从技术角度看,紧急情况识别本质上是一个医疗分诊(Triage)问题。在传统医疗体系中,分诊由经过专业训练的护士或急诊医生完成,他们依据标准化的分诊量表(如曼彻斯特分诊系统、急诊严重度指数ESI)来判断患者的紧急程度。AI要实现类似能力,需要理解症状组合的临床意义——例如,单纯的胸痛可能是肌肉拉伤,但胸痛伴随左臂放射痛、出汗和呼吸困难则高度提示急性心肌梗死。模型需要学会识别这些"红旗症状"(Red Flag Symptoms)的组合模式,才能做出恰当的紧急程度判断。
主动追问相关上下文
在医疗问诊中,信息的完整性至关重要。GPT-5.5 Instant学会了像经验丰富的医生一样,主动询问与症状相关的背景信息——比如症状持续时间、既往病史、用药情况等。这种"追问"能力大幅提升了回答的针对性和准确性。
在临床医学中,医生通常遵循结构化的问诊框架来收集信息。最常用的是OLDCARTS框架:发病时间(Onset)、部位(Location)、持续时间(Duration)、特征(Character)、加重/缓解因素(Aggravating/Alleviating factors)、伴随症状(Related symptoms)、时间模式(Timing)和严重程度(Severity)。此外,既往病史、家族史、用药史和过敏史也是诊断的关键线索。AI模型学会主动追问这些信息,本质上是在模拟医生的临床思维过程,将碎片化的用户描述补充为完整的临床图景,从而提供更有针对性的健康建议。
坦诚表达不确定性
医学领域充满不确定性,AI最危险的行为之一就是在不确定时表现得过于自信。GPT-5.5 Instant在这方面有了明显改善,能够更好地向用户说明哪些判断是有把握的,哪些存在不确定性,从而帮助用户做出更理性的决策。
在机器学习领域,模型对自身预测的置信度是否与实际准确率相匹配,被称为"校准"(Calibration)问题。一个校准良好的模型,当它表示80%的置信度时,其预测确实有约80%的概率是正确的。早期的大语言模型普遍存在"过度自信"问题——即使在错误的回答上也表现得非常确定,这在医疗场景下尤其危险,可能导致用户忽视严重症状或采取不当措施。改善不确定性表达涉及RLHF(基于人类反馈的强化学习)中的专门训练,让模型学会区分"有充分证据支持的判断"和"需要进一步检查才能确认的推测",并以恰当的方式向用户传达这种区别。
复杂信息的通俗化表达
医学术语对普通用户来说往往晦涩难懂。新模型在将复杂的医学概念转化为易于理解的语言方面表现更佳,降低了健康信息的理解门槛。
医生主导的评估体系是关键
OpenAI特别强调,这些医疗能力提升的背后,由医生主导的评估体系(Physician-led evaluation)起到了至关重要的作用。
AI在医疗领域的进步不能仅靠算法工程师闭门造车,必须有专业医疗人员深度参与模型的评估和优化。医生能够从临床实践的角度判断模型回答的准确性、安全性和实用性,这种跨学科协作模式可能成为AI医疗应用的标准范式。
具体而言,医生主导的AI评估体系通常包含多个层面:首先是临床准确性评估,由各专科医生判断AI回答是否符合当前医学证据和临床指南;其次是安全性评估,识别可能导致患者延误治疗或采取有害行为的回答;第三是沟通质量评估,判断信息传达是否清晰、是否考虑了患者的健康素养水平。这种评估模式借鉴了循证医学(Evidence-Based Medicine)的理念,将临床专业知识与AI技术开发相结合。在实践中,这通常需要建立由多学科医生组成的评审团队,制定标准化的评分量表,并进行大规模的盲评实验,以确保评估结果的客观性和可重复性。
免费开放的普惠价值
有意思的是,GPT-5.5 Instant面向所有ChatGPT免费用户开放。这意味着这些医疗问答能力的提升不仅惠及付费用户,而是能够触达更广泛的人群——包括那些可能因经济原因难以获得优质医疗咨询的群体。
在全球医疗资源分布极不均衡的背景下,一个免费、高质量的AI健康助手的潜在社会价值不可估量。根据世界卫生组织的数据,全球约有一半人口无法获得基本医疗服务,低收入国家平均每万人仅有不到10名医生,而高收入国家这一数字超过30名。在许多发展中地区,患者可能需要长途跋涉数小时才能见到医生,且面临语言障碍和高昂费用。在这一背景下,免费的AI健康助手可以作为初级健康信息获取的补充渠道,帮助用户进行初步的症状评估和健康教育。
当然,这也对模型的安全性提出了更高要求,毕竟使用者中包含大量缺乏医学常识、可能过度依赖AI建议的普通用户。如何在提供有用信息的同时避免用户将AI建议等同于医嘱,是产品设计中需要持续关注的问题。
冷静看待AI医疗的边界
尽管GPT-5.5 Instant的进步令人瞩目,但我们仍需保持清醒:AI健康助手是信息获取的补充工具,而非专业医疗诊断的替代品。"追平前沿Thinking模型"这一表述本身也需要更多细节来验证——具体的评测基准、测试范围和对比方法都值得进一步关注。
从趋势来看,OpenAI正在将医疗健康作为AI能力提升的重点方向之一。每周2.3亿次的健康咨询量既是巨大的责任,也是推动模型持续进化的强大动力。这一数据本身也构成了独特的飞轮效应:海量的真实用户交互为模型优化提供了丰富的训练信号,而模型能力的提升又会吸引更多用户使用,进一步扩大数据规模。如何在利用这些数据改进模型的同时保护用户隐私,将是OpenAI需要持续平衡的核心挑战。
核心要点
相关推荐
198页Codex中文手册深度解读:从入门到高阶全流程
深度拆解字节跳动内部整理的198页Codex中文使用手册,涵盖安装配置、Commands指令体系、MCP工作流、Skills模板、多Agent协作与后台任务调度,助你系统掌握AI编程助手的完整使用链路。
Trae AI编程工具:下载安装与上手使用完整教程
详细介绍字节跳动Trae AI编辑器的核心优势、下载安装流程、Python环境配置及AI对话编程实战,免费中文原生支持,国内直连无需科学上网,助你快速上手AI编程。
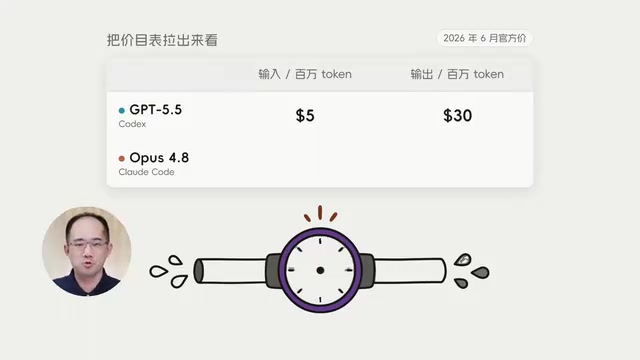
Codex vs Claude Code费用对比:10倍差价的真实原因拆解
同一编程任务Codex花15美元,Claude Code花155美元,10倍差价从何而来?本文从Token单价、消耗量、工作模式三个维度深度拆解原因,并给出实用的选择建议和省Token技巧。