Codex vs Claude Code费用对比:10倍差价的真实原因拆解
一个任务两份账单:10倍差价从何说起
同一个复杂编程任务,分别交给 OpenAI 的 Codex 和 Anthropic 的 Claude Code 来完成,结果账单一出来:Codex 花了 15 美元,Claude Code 花了 155 美元——整整 10 倍的差距。而且这并非偶然,类似的差距在多次实测中反复出现。
这不禁让人发问:Claude Code 更贵,是因为它更强吗?10 倍差价到底差在哪里?本文将从 Token 单价、消耗量和工作模式三个维度,拆解这个问题的真实答案。
Token单价对比:一个反直觉的事实
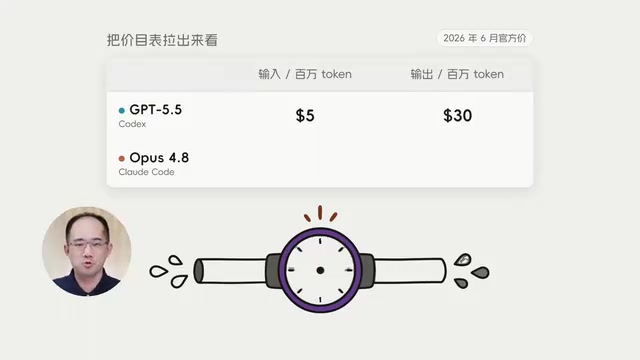
很多人第一反应是"Codex 便宜是因为 OpenAI 单价低",但拉出官方价格表,你会发现事实恰恰相反。
在深入对比之前,有必要先理解 Token 的计费逻辑。Token 是大语言模型处理文本的基本单位,大致相当于一个英文单词的 3/4 或一个中文汉字。所有主流 AI 服务商都按 Token 数量计费,且输入和输出分开定价。输出 Token 之所以通常比输入贵好几倍,是因为生成每一个输出 Token 都需要模型进行一次完整的前向推理计算,而输入 Token 可以并行处理,计算资源消耗远低于逐个生成的输出过程。理解了这一点,才能看懂后面的成本拆解。
Codex 主力模型的定价为:每百万 Token 输入 5 美元,输出 30 美元。而 Claude Code 主力模型的定价为:每百万 Token 输入 5 美元,输出 25 美元。
第一个结论非常反直觉:Codex 的 Token 单价不仅不便宜,在输出端反而比 Claude Code 还贵。 所以这 10 倍差价根本不是靠单价打出来的。
Token消耗量:4倍的用量差距
既然不是单价问题,那就只能是用量了。实测数据显示,同类复杂任务中:
- Codex 大约消耗 150 万 Token
- Claude Code 大约消耗 620 万 Token
差了 4 倍多。根据社区中不同用户、不同任务的反馈,这个倍数在 3.2 到 4.2 之间波动,但无一例外,Codex 明显更省 Token。
那么问题来了:Token 消耗差 4 倍,为什么最终账单能差到 10 倍?这需要从三个层面来拆解。
10倍差价的三层深层原因
第一层:输出风格差异——惜字如金 vs 边干边聊
Codex 非常"惜字如金",你让它写代码,它倾向于直接给你一段能跑的结果,不多解释。而 Claude Code 则更像一个"边干边汇报"的工程师——它会把判断过程写出来,会反问你确认需求,还会顺手讲讲为什么这么写。
这种风格差异并非偶然,而是源于两家公司截然不同的产品设计哲学。OpenAI 的 Codex 脱胎于代码补全工具(最早的 Codex 模型就是 GitHub Copilot 的后端),其设计基因就是"最短路径输出可执行代码"。而 Anthropic 从创立之初就将"可解释性"和"安全对齐"作为核心理念,Claude 系列模型被训练为更倾向于展示推理过程、主动确认意图,这种"透明化思考"的设计在 Claude Code 中被进一步强化——它不只是写代码,更试图让你理解它为什么这样写。

AI 编程最怕的就是放大效应:每一轮对话中的微小差异,经过几十轮迭代叠加,就能滚成好几倍的 Token 差距。要理解这种放大效应的威力,可以做一个简单的数学推演:假设每轮对话 Claude Code 比 Codex 多输出 30% 的 Token,同时上下文也因此多膨胀 30%。第一轮差距只有 30%,但到了第 N 轮,累计的 Token 消耗差距接近 1.3 的 N 次方。经过 10 轮对话,差距就扩大到约 3.4 倍;20 轮下来,差距可达 11 倍以上。这就是为什么"每轮多说几句话"这种看似微不足道的差异,最终能在账单上制造出数量级的鸿沟。一个闷头干活,一个边干边聊,几十轮下来,差距自然惊人。
第二层:上下文管理策略——克制读取 vs 全量读取
上下文(Context)是 AI 在回答前需要读取和整合的所有信息——你说过的话、它读过的文件、命令输出、错误日志等等。关键在于,上下文也要按 Token 计费。
从技术层面来说,上下文窗口(Context Window)是 Transformer 架构的核心约束之一。模型在生成每一个新 Token 时,都需要对上下文中的所有 Token 进行注意力计算(Attention),其计算复杂度与上下文长度的平方成正比(即 O(n²))。这意味着上下文从 10 万 Token 膨胀到 40 万 Token,不仅 Token 费用翻了 4 倍,底层的计算资源消耗实际上翻了 16 倍。虽然服务商不会直接按计算量收费,但上下文越长,每次 API 调用的延迟越高、成本越大,这也是为什么上下文管理策略对最终账单影响如此深远。
Claude Code 的读法比较"实在":每读一个文件、每跑一条命令,往往会把整段原文塞进上下文,而且不太会主动清理。好处是能尽量贴合你的需求,不容易跑偏;但代价是,假如中途读了一份上万行的日志,这份日志会一直占用 Token,上下文就像滚雪球一样越滚越大。
Codex 在这件事上更加克制——读得更省,上下文增长更慢。所以在同样大小的上下文窗口下,Codex 的实际 Token 利用效率更高。
第三层:工作性格——直奔目标 vs 反复验证
Claude Code 更"较真":同一个 bug,它会主动多翻几个相关文件,多查几遍,多确认几次自己有没有搞错。这种认真的代价就是每一步都在烧 Token。
Codex 则更"直奔目标":看准了就动手,很少解释,很少绕路,也很少让你反复确认。
把这三层叠加起来——输出更啰嗦 × 上下文更臃肿 × 验证更频繁——4 倍的 Token 差距经过单价加权,最终就膨胀成了 10 倍的账单差距。
多花的钱是浪费吗?Claude Code的隐藏价值
看到这里,似乎 Codex 完胜。但如果真是这样,Claude Code 就不会拥有那么多忠实用户了。
Claude Code 多烧掉的那几倍 Token 并不全是浪费。 因为它读得全、查得细、想得多,在一些对比测试中,Claude Code 抓到过 Codex 漏掉的 Race Condition(竞态条件)——这是一种偶尔才冒出来、平时测试很难复现的隐藏 bug,在生产环境中最为棘手。
竞态条件是并发编程中最经典也最棘手的问题之一。当两个或多个线程(或进程)同时访问共享资源,且最终结果取决于它们执行的先后顺序时,就可能出现竞态条件。它的危险之处在于:在开发和测试环境中,由于负载较低、时序相对固定,竞态条件可能永远不会触发;但在生产环境的高并发场景下,它会以极低的概率随机出现,导致数据损坏、死锁甚至安全漏洞。历史上许多重大系统故障——从银行重复扣款到航天器软件崩溃——都与竞态条件有关。正因为这类 bug 几乎无法通过常规单元测试捕获,Claude Code 那种"多翻几个文件、多查几遍关联逻辑"的工作方式,反而更有可能在代码审查阶段就将其揪出来。
不仅如此,有人做过一组盲评实验:把两边写出来的代码盖住名字给开发者看,结果 67% 的人觉得 Claude Code 写的代码更干净、更易维护。
所以目前来看,没有绝对的谁好谁坏,各有优劣,选择哪个本质上是一个取舍问题。
实用建议:不同场景怎么选与省钱技巧

既然 Codex 省在"读得省、不绕路",Claude Code 贵在"读得全、查得细、确认得多",我们完全可以根据任务性质来灵活选择。
适合选 Codex 的场景
- 写文案、日常开发、快速迭代
- 做原型验证、概念验证(PoC)
- 预算比较吃紧的个人项目
- 对代码质量要求"够用就行"的场景
适合选 Claude Code 的场景
- 复杂系统重构
- 生产级代码编写
- 对质量和容错要求非常高的项目
- 需要处理并发、安全等敏感逻辑的场景
通用省 Token 技巧
- 明确需求再开工:一次性把需求描述清楚,减少来回确认的轮次
- 控制上下文规模:避免一次性喂入过大的文件,按需分段提供
- 善用任务拆分:把大任务拆成小任务,每个小任务独立会话,避免上下文无限膨胀。这一点尤其重要——前面提到上下文的注意力计算复杂度是 O(n²),这意味着一个 20 万 Token 的长会话拆成 4 个 5 万 Token 的短会话,理论上总计算量可以降低到原来的 1/4,虽然实际节省幅度取决于服务商的具体计费方式,但拆分会话几乎总是能显著降低成本
- 混合使用:简单任务用 Codex 快速搞定,关键模块用 Claude Code 精雕细琢。这种"双引擎"策略在实践中被越来越多的开发团队采用——用 Codex 搭建脚手架和处理样板代码,再用 Claude Code 对核心业务逻辑、安全模块和并发处理进行深度审查和优化,既控制了总成本,又在关键环节保证了代码质量
总结:效率与质量的取舍
回到最初的问题:Claude Code 更贵是因为它比 Codex 强吗?
答案是:并不是。 一个注重效率,一个注重质量。10 倍差价的本质不在于 Token 单价,而在于两种截然不同的工作哲学——Codex 像一个沉默高效的执行者,Claude Code 像一个严谨细致的审查者。效率重要还是质量更重要,取决于你手上的具体任务和预算约束。
最聪明的做法,或许不是二选一,而是让它们各司其职。
相关推荐
LifeSciBench:173位科学家打造的生命科学AI基准测试
LifeSciBench是由173位生物技术与制药领域科学家共同开发的生命科学AI基准测试,涵盖750项专家任务和七大研究工作流程,为AI在生命科学领域的评估提供专业标准。

OpenAI o3诊断罕见儿童疾病:NEJM AI研究深度解读
OpenAI联合波士顿儿童医院在NEJM AI发表研究,展示o3 Deep Research模型如何帮助临床医生诊断此前未解决的罕见儿童疾病病例,为等待多年的家庭带来答案。
GPT-5.4驱动药物化学项目:从文献综述到实验验证的完整闭环
GPT-5.4驱动药物化学项目:从文献综述到实验验证的完整闭环
GPT-5.4联合Maria AI与自动化实验室,首次完整驱动药物化学项目闭环,从文献综述、假说生成到实验验证。深入解析AI在药物发现中的角色突破、人机协作新范式及对行业的深远影响。