GPT-5.6 First Leak: How Self-Training Loops Enable OpenAI's Three-Week Iteration Cycle
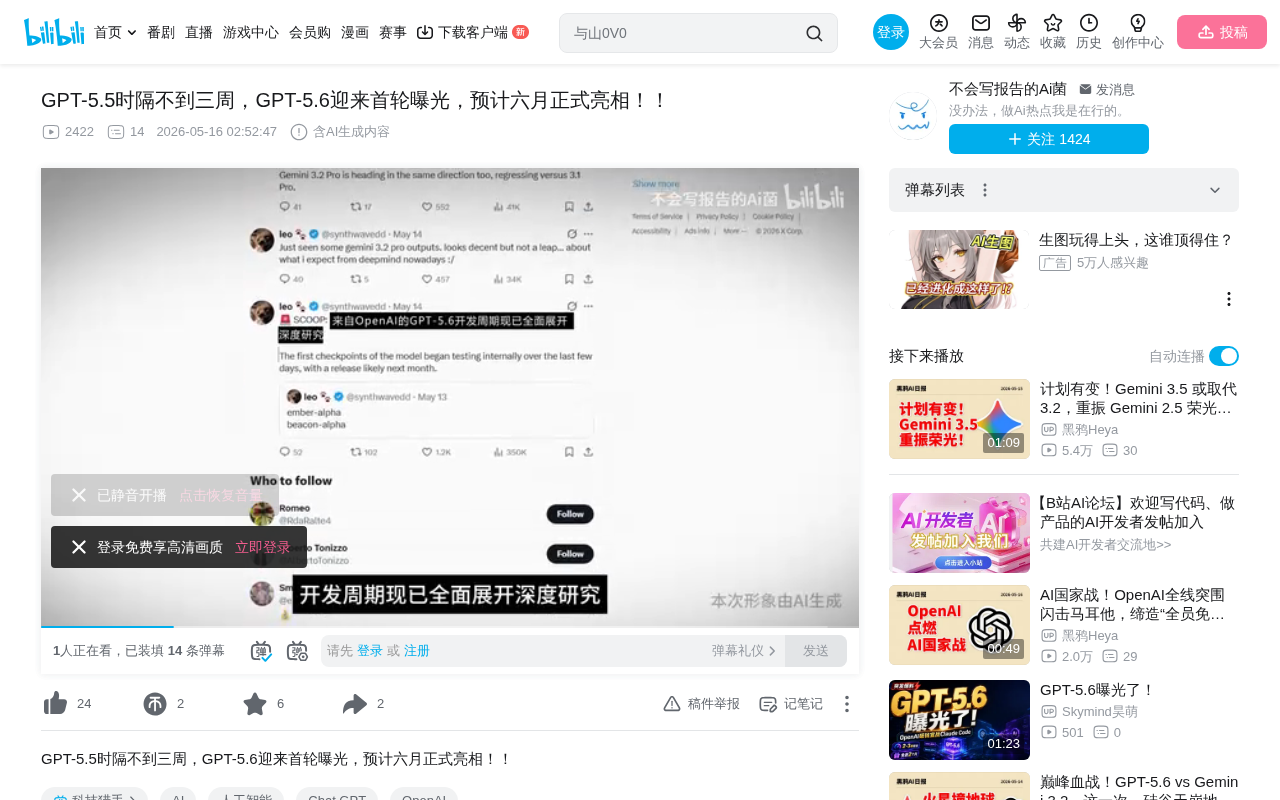
GPT-5.6 enters internal testing as self-training loops drive OpenAI's three-week iteration cycle.
According to leaks, OpenAI's GPT-5.6 first internal checkpoints have begun testing, with a June release expected — just three weeks after GPT-5.5. The core acceleration comes from the self-training loop mechanism introduced in GPT-5.3: the model's high-quality code and data outputs are used as training material for the next round, forming a self-reinforcing flywheel. However, this also introduces risks including model collapse, error amplification, and compressed safety evaluation windows.
Core News: GPT-5.6 Has Entered Internal Testing
According to a leak from a Bilibili content creator, OpenAI's GPT-5.6 development cycle is fully underway. The first batch of internal checkpoints began testing in recent days, with a formal public release expected next month (June).
In the large model development pipeline, a checkpoint refers to a periodically saved snapshot of the model's state during training. Internal checkpoint testing means the model hasn't completed its full training process but has reached an evaluable intermediate state. This stage typically involves capability benchmarks (such as MMLU, HumanEval, etc.), safety red-teaming, and alignment evaluations. From checkpoint testing to official release, models usually still need to go through fine-tuning optimization, safety hardening, inference efficiency optimization, and API adaptation. A one-month window is quite tight, suggesting that OpenAI may have already highly automated these post-processing workflows.
What's particularly interesting is that barely three weeks have passed since GPT-5.5's release, and the new 5.6 version is already in internal testing. This iteration speed far exceeds external expectations and signals that OpenAI's model update cadence is accelerating significantly.
The Key Behind the Acceleration: Self-Training Loop Mechanism
Why is OpenAI able to push model iterations forward so rapidly? According to the leaked information, the core reason lies in a major technical breakthrough introduced with GPT-5.3 — the self-training mechanism.
What Is a Self-Training Loop?
In simple terms, starting with GPT-5.3, OpenAI began using AI-generated code produced by the model itself to feed back into the model for training and deployment. The entire process forms a self-reinforcing closed loop:
- Model generates high-quality code and data → 2. These outputs are used as training material for the next round → 3. A stronger model is trained → 4. The stronger model generates better data → Repeat
Once this flywheel effect is set in motion, iteration speed only accelerates. Every improvement in a generation's output quality directly boosts the training efficiency of the next generation.
Self-training is not an entirely new concept — its roots trace back to semi-supervised learning. As early as 2020, Google's Noisy Student Training demonstrated the effectiveness of using a teacher model to generate pseudo-labels for training a student model. However, scaling self-training in the large language model domain faces unique challenges: evaluating the quality of generated text is far more complex than verifying pseudo-labels in image classification. OpenAI had already partially adopted model self-evaluation mechanisms in RLHF (Reinforcement Learning from Human Feedback), but GPT-5.3's breakthrough extended this approach to the entire training data pipeline — not just evaluation, but the training material itself is produced by the model. This is essentially the ultimate application of a bootstrapping strategy.
A Paradigm Shift from Linear to Exponential
Traditional large model training is heavily dependent on human-annotated data and external corpus collection — these steps are often the bottlenecks constraining iteration speed. The self-training mechanism fundamentally breaks this limitation — the model itself becomes the data producer, forming a nearly self-sufficient training loop.
This also explains why the intervals between versions from GPT-5.3 to 5.5 to 5.6 have compressed from months to weeks.
Industry Impact and Outlook
Intensifying Competition
If OpenAI has truly achieved a "three-week iteration" cadence, it will put enormous pressure on competitors like Anthropic and Google DeepMind. Rapid capability improvements mean the differentiation window at the product level is shrinking dramatically.
The current large model competition has entered an infrastructure arms race phase. Anthropic's Claude series relies on its Constitutional AI methodology, while Google DeepMind maintains competitiveness through the Gemini series and TPU compute advantages. If OpenAI has truly achieved a self-training flywheel effect, it means the relative importance of the two traditional barriers — compute and data — has fundamentally shifted. Model capability itself becomes the most critical competitive resource, because stronger models can produce better training data. Once this positive feedback loop is established, the difficulty for latecomers to catch up grows exponentially, potentially forming a true technological moat.
Potential Risks of Self-Training Loops
While self-training loops can accelerate iteration, they also carry risks that cannot be ignored:
- Model Collapse: Over-reliance on self-generated content for training data may lead to decreased output diversity
- Error Amplification: Model biases and hallucinations may be continuously reinforced through the loop
- Safety Evaluation Pressure: Faster iteration means compressed time windows for safety testing
Model Collapse is a concept formally introduced in a 2023 Nature paper by research teams from Oxford University and Cambridge University. The research showed that when generative models repeatedly train on their own generated data, the output distribution gradually degrades — low-probability events are systematically forgotten, tail information in the distribution is lost, and model outputs ultimately converge toward uniformity. This is analogous to quality degradation from repeatedly photocopying a document. To avoid this problem, OpenAI likely needs to introduce diversity preservation mechanisms in the self-training loop, such as mixing in a certain proportion of real human data, setting output diversity thresholds, or employing adversarial filtering strategies to ensure distribution coverage of training data.
What This Means for Users
If GPT-5.6 does indeed debut in June, users can expect further improvements in reasoning capabilities, code generation, multimodal understanding, and more. However, specific performance results will need to be verified through benchmarks after the official release.
Summary
Based on currently available information, OpenAI is accelerating model iteration through its self-training loop mechanism, and GPT-5.6's rapid progress is a direct manifestation of this strategy. That said, it's worth noting that current information comes primarily from a single leak source, and specific release timing and performance details still await official confirmation from OpenAI.
Key Takeaways
- GPT-5.6's first internal checkpoints have begun testing, with a June release expected
- Only three weeks since GPT-5.5's release, iteration speed has significantly accelerated
- The core acceleration comes from the self-training loop mechanism introduced in GPT-5.3 — using model-generated AI code to train the model in return
- The self-training flywheel effect transforms iteration from linear to exponential acceleration
- Rapid iteration also brings potential risks including model collapse, error amplification, and safety evaluation pressure
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.