开源模型写代码总报错?问题可能出在编程框架上
开源模型不是不行,是框架没跟上
DeepSeek、Kimi、Gemini、Qwen、MiniMax……这些开源或国产大模型正变得既强悍又便宜。但当开发者在编程智能体中使用这些模型时,经常遇到工具调用失败、代码编辑出错等问题,于是得出结论:"开源模型不行"。
但事实可能并非如此。问题往往不在模型本身,而在于承载模型的编程框架。
一个编程智能体(Coding Agent)远不止是模型本身——它还包括文件管理、工具调用、终端操作、缓存策略、上下文处理和错误恢复机制。这些组件共同构成了所谓的"框架层":文件系统的读写管理要求模型理解项目结构并精确修改文件;工具调用协议需要将模型输出正确解析为实际操作;终端命令执行负责运行测试和构建项目;上下文窗口管理则需要在有限的 token 预算内选择最相关的代码片段。当框架没有针对特定模型做适配优化时,即使模型能力足够,输出质量也会大打折扣。
今天要介绍的 Commander Code(Coder) 就是一个专为开源模型优化的编程框架,它的核心理念是:让 DeepSeek、Kimi 等模型发挥出更接近真实水平的编码能力。
主流AI编程框架的设计哲学差异
目前主流的 AI 编程工具各有侧重:
- Cursor 的云端代码围绕 Claude 构建
- Codex 围绕 GPT 系列构建
- OpenCode 提供广泛的模型访问权限
- Commander Code 则专门为开源模型优化
这种差异的根源在于,大语言模型的工具调用(Function Calling / Tool Use)并没有统一的行业标准。Claude 使用 Anthropic 定义的 tool_use 格式,GPT 系列使用 OpenAI 的 function_calling 协议,而 DeepSeek、Qwen 等开源模型各自有不同的工具调用实现方式。差异体现在参数的 JSON Schema 格式、多工具并行调用的处理方式、流式输出中工具调用的分块策略,以及错误状态的返回格式等多个层面。当你用 DeepSeek 在为 Claude 优化的框架中工作时,这些环节都可能出现不兼容的问题。Commander Code 的做法是从底层重新设计这些环节,让开源模型的输出能被正确解析和执行。
关键技术优化:缓存路由与工具调用修复
根据 Commander Code 的工程博客,他们在两个关键领域做了深度优化:
缓存路由优化
传统方案中,开源模型跨轮次对话时每次都需要重新加载上下文,首次延迟通常在 6-8 秒。这个延迟的根本原因与大语言模型推理中的 KV Cache(键值缓存)机制有关。在 Transformer 架构中,每次生成新 token 时都需要对之前所有 token 进行注意力计算,KV Cache 通过缓存已计算的键值对来避免重复计算。在多轮对话场景中,如果前几轮的对话内容(即"对话前缀")没有变化,理论上可以直接复用其 KV Cache。但在实际的 API 服务中,由于负载均衡和实例调度等原因,请求可能被路由到不同的 GPU 节点,导致缓存失效。
Commander Code 优化了缓存路由机制,确保同一会话的请求被路由到持有热缓存的同一推理节点,让模型能跨轮次保留"热对话前缀",将缓存轮次的首次延迟降到了 1 秒以内。对于需要频繁迭代的编程任务来说,这个体验提升非常明显——开发者在一次编码会话中可能进行数十轮对话,每轮节省 5-7 秒意味着整体效率的显著提升。
工具调用自动修复
当模型输出错误的工具调用时(比如参数格式不对、文件路径错误),Commander Code 不会让单个错误调用搞砸整个任务,而是加入了自动修复机制。模型权重没变,但框架不再浪费模型算力了——这才是关键。框架层的自动修复可能包括:对不完整的 JSON 输出进行容错解析、对文件路径进行模糊匹配和自动纠正、在工具调用失败时自动重试并附加错误上下文等策略。
根据其内部评测数据(注意:这是官方内部结果,非独立基准测试):
- DeepSeek V4 Pro 击败了 Claude Opus,在高难度工具依赖任务中 10 次有 6 次胜出,得分 4.7 vs 对手更低分
- Kimi K2 拿到了 10 分之 5 的胜率,几乎追平
实战演示:真实项目中的编程表现
视频作者没有用空的 Hello World 项目来测试,而是选择了一个包含组件、API 路由和测试的现成 Web 应用。
测试任务是一个真实的功能需求:在问题页面添加保存筛选功能,具体要求包括:
- 遵循现有的组件模式
- 将筛选条件本地持久化
- 在现有测试结构支持的地方加测试
- 运行相关检查
- 不引入新 UI 库,不改无关文件
使用 DeepSeek V4 Pro 作为核心模型,整个过程中模型持续循环工作——读取仓库、找到问题页面、制定计划、编辑文件、运行测试、修复失败的检查。最终输出的差异对比显示:模型复用了现有模式,改动范围准确,功能正常运行,测试通过。
这比基准测试截图更有说服力——一个实惠的开源模型在真实代码库里完成了实际工作。
Taste:基于持续强化学习的个性化编码系统
Commander Code 中一个值得关注的功能叫 Taste,它是一套持续强化学习系统:
- 从你每次的接受、拒绝和编辑信号中学习
- 逐渐理解你的编码偏好和惯例
- 下次会话自动沿用你的风格,无需编写规则或维护提示词
值得注意的是,Taste 的"持续强化学习"与大模型训练阶段的 RLHF(基于人类反馈的强化学习)有本质区别。RLHF 发生在模型训练阶段,通过大量标注数据训练奖励模型,再用 PPO 等算法优化模型权重,是一个离线的、全局的过程。而 Taste 的学习发生在推理阶段,它不修改模型权重,而是通过记录用户的行为信号,构建个性化的偏好配置文件,在后续请求中作为上下文注入到提示词中。这种方式更接近"上下文学习"(In-Context Learning)与"检索增强生成"(RAG)的结合——系统检索用户历史偏好,将其作为额外上下文提供给模型,从而在不改变模型参数的情况下实现个性化输出。
比如,如果你习惯调用现有的辅助工具、只用特定的测试框架、避开不必要的组件,Taste 会从这些信号中学习。按 Ctrl+T 可以查看偏好设置,这些设置会写入到本地的 Taste 文件夹。
更有趣的是,Taste 支持发布和共享:
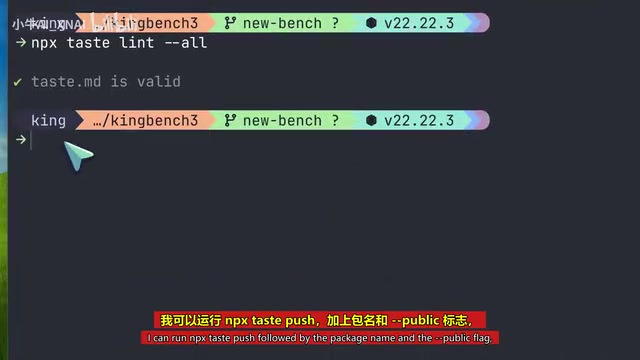
- 运行
npx taste-lint验证 Taste 包 - 运行
npx taste-push加包名和 Public 标志发布 - 其他人可以通过
npx taste-pull拉取你的偏好配置
这意味着团队可以共享编码规范,新成员可以快速对齐项目风格。这种机制本质上是将隐性的编码知识(个人习惯、团队惯例)显性化为可分发的配置包,解决了传统代码规范文档难以覆盖的"风格一致性"问题。
其他核心功能速览
Commander Code 还提供了一系列实用功能:
- Model 指令:在 DeepSeek、Kimi、Gemini、Qwen、MiniMax、Claude、GPT 之间自由切换,同一工作流中对比不同模型
- CM 模式:智能体在编辑前先检查并提出修改建议,适合高风险重构
- Atlas 模式:通过 CMD+P 运行单次终端请求
- 检查点与回滚:CMD+K 创建检查点,双击 S 或运行 Rewind 恢复代码和对话
- PR 审查:将评审上下文拉入会话,模型检查差异、处理反馈、补全缺失测试
- MCP 集成:连接外部工具和文档。MCP(Model Context Protocol,模型上下文协议)是由 Anthropic 于 2024 年底提出的开放协议标准,旨在为 AI 模型与外部工具、数据源之间建立统一的通信接口。在 MCP 出现之前,每个 AI 应用都需要为每个外部工具单独编写集成代码,形成 M×N 的复杂度。MCP 通过定义标准化的客户端-服务器架构,将这一复杂度降为 M+N,使得开发者可以轻松连接数据库查询、API 文档检索、项目管理工具等外部服务
- IDE 集成:共享 VS Code 文件和选中内容
关于隐私,Commander Code 表示不会用代码进行训练或存储代码片段,还可以通过命令行强制开启零数据留存路由。
定价与快速入门
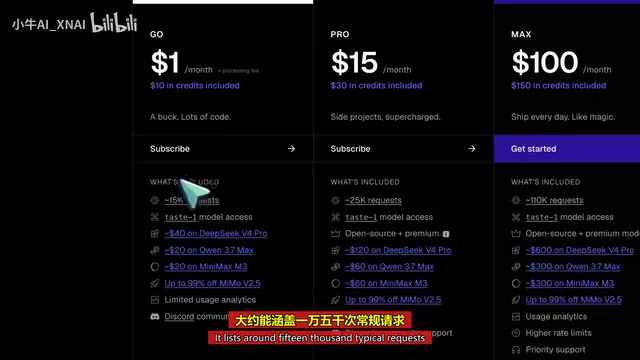
入门门槛很低:每月 1 美元外加处理费,提供 10 美元的开源模型额度,大约能涵盖 15000 次常规请求。更高级的计划包括 15 美元(含 30 美元额度)、100 美元(含 150 美元额度)和 200 美元(含 300 美元额度)。
安装也很简单:确保已安装 Node,然后运行 npm install -g coder,用 coder version 验证,coder login 授权,进入项目文件夹运行 coder 即可开始。
总结:模型重要,框架同样重要
当 DeepSeek、Kimi、Gemini、Qwen 已经足够强大时,为每个小功能和 bug 修复去付高昂的闭源模型费用可能就没有必要了。但前提是,你需要一个能让这些模型真正发挥实力的框架。
Commander Code 吸引人的地方不是因为它支持更多模型,而是因为它正在成为一个真正让开源模型胜任软件开发工作的编程智能体框架。 围绕模型设计的整个闭环——缓存路由、工具修复、持续学习、检查点恢复——才是让开源模型从"能用"变成"好用"的关键。
从更宏观的视角来看,这反映了 AI 工程领域的一个重要趋势:当基础模型的能力趋于同质化时,竞争的焦点正在从"谁的模型更强"转向"谁的系统工程做得更好"。模型是引擎,但框架是整辆车——引擎再强,底盘、变速箱和悬挂系统跟不上,驾驶体验也不会好。Commander Code 的实践证明,通过精心设计的框架层优化,开源模型完全有可能在实际编程任务中达到甚至超越闭源模型的表现。
如果你对开源模型的编程能力持怀疑态度,不妨花 1 美元试试:选个真实项目,用开源模型跑个真实任务,检查差异,运行测试,看看成本——然后自己做决定。
相关推荐
GML 5.2多模态升级实测:DeepSeek V4全面跑通验证
基于OneBlockBase平台实测GML 5.2与DeepSeek V4多模态升级,详解视觉识别与文本协同工作流搭建、前置拦截安全机制、界面生成效果及部署配置要点,验证纯文本模型通过工作流编排升级多模态的可行方案。
DeepSeek+Cline配置教程:10元替代月费20美金的AI编程方案
详解DeepSeek API搭配VS Code插件Cline的完整配置流程,包括API Key获取、Plan/Act双模型策略、项目管理文件体系等进阶技巧,10元充值即可获得接近顶尖水平的AI编程体验。
5步让Codex接入DeepSeek,无需GPT账号也能用
详细图文教程:通过CC Switch中转工具,5步将Codex接入DeepSeek API,无需GPT账号即可使用AI编程助手的全部功能,包括代码补全、技能插件等,成本更低体验无损。