Kimi K2.5 Fully Open-Sourced: Deep Dive into 1T Parameter MoE Architecture + Agent Cluster Capabilities
Moonshot AI fully open-sources 1T-parameter Kimi K2.5, topping open-source rankings and challenging closed-source giants.
Moonshot AI fully open-sourced Kimi K2.5 on January 27th, featuring a 1T parameter MoE architecture that tops open-source leaderboards in AI programming and multimodal understanding, with some benchmarks surpassing GPT-4O and Claude 3.5 Sonnet. Core highlights include Vision-to-Code capability (generating high-fidelity code directly from screenshots and sketches) and an Agent cluster mechanism (up to 100 Agents processing complex tasks in parallel), dramatically lowering development barriers and revolutionizing workflows, marking open-source models breaking the closed-source monopoly.
Moonshot AI dropped a bombshell on January 27th — Kimi K2.5 is now fully open-sourced. This isn't a simple model release; it's a top-tier large model with a 1T parameter MoE architecture and Agent cluster capabilities, made freely available to developers worldwide. On core tracks like AI programming and multimodal understanding, K2.5 has claimed the top spot among open-source models, with some benchmarks even surpassing GPT-4O and Claude 3.5 Sonnet. What does this mean? The open-source community finally has a full-powered model that can go head-to-head with closed-source giants.
Kimi K2.5 Visual Programming: A Paradigm Shift from Screenshots to Code
One of Kimi K2.5's most remarkable capabilities is its breakthrough in Vision-to-Code. Traditional AI programming assistants require users to describe requirements in detail using natural language — page layouts, interaction logic, style specifics — each requiring precise articulation, resulting in extremely high communication costs.
K2.5 fundamentally changes this paradigm. You can directly feed it a webpage screenshot, a screen recording, or even a rough sketch drawn on a napkin, and it delivers a 1:1 high-fidelity reproduction from design to code. This isn't merely simple image recognition plus code generation — it's a comprehensive demonstration of multimodal understanding, UI layout analysis, front-end engineering, and more working in concert.
The visual programming capability relies on deep fusion of multimodal large models. Early multimodal models (like CLIP) primarily focused on image-text matching, while modern multimodal large models need to understand pixel-level spatial relationships, UI component hierarchies, CSS layout logic, and other complex information. This breakthrough is inseparable from training on large-scale UI datasets, including paired data of webpage screenshots with corresponding HTML/CSS code, and alignment data between design mockups and front-end implementations. Microsoft's Screenshot-to-Code project and Anthropic's Claude have both explored this direction, but K2.5 elevates it to the point of directly processing hand-drawn sketches, indicating the model possesses stronger abstract understanding and intent inference capabilities rather than simple pixel-level pattern matching.

The significance of this capability is that it lowers the barrier to software development from "knowing how to code" to "being able to sketch." For product managers, designers, and entrepreneurs, the distance from idea to prototype is compressed to just minutes. For professional developers, front-end page reproduction work can be dramatically accelerated. This represents a critical step in AI programming's evolution from "assisting with code writing" to "understanding intent and autonomous implementation."
Agent Cluster Parallel Processing: AI Starts "Working in Teams"
If visual programming represents K2.5's "hard power," then the Agent cluster mechanism is its true "killer feature."
Traditional AI assistants operate in single-threaded mode — you assign a task, it executes step by step, and when facing complex problems, it easily gets stuck or quality degrades. Kimi K2.5 adopts an entirely new architectural approach: when facing complex tasks, it automatically decomposes them and summons up to 100 Agent instances for parallel processing.
Multi-Agent parallel collaboration systems (Multi-Agent Systems) represent a frontier direction in AI engineering, with theoretical foundations traceable to Distributed Artificial Intelligence (DAI) research. In the era of large language models, frameworks like AutoGPT, LangChain, and CrewAI pioneered engineering implementations of multi-Agent collaboration, but early solutions commonly faced issues including high inter-Agent communication overhead, unstable task decomposition quality, and difficulty controlling error propagation. K2.5's Agent cluster mechanism features deep architectural optimization: an Orchestrator Agent handles task decomposition and result aggregation, Worker Agents focus on atomic task execution, and a parallel scheduling mechanism maximizes resource utilization. Supporting up to 100 concurrent Agents means the underlying system must solve engineering challenges like large-scale concurrent state management, context isolation, and result consistency — making this one of K2.5's core technical moats distinguishing it from similar products.
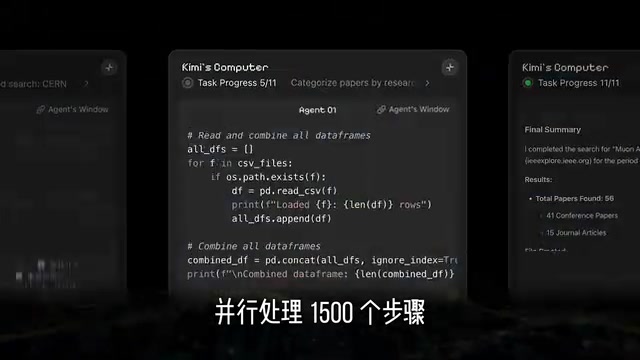
How powerful is this "call for backup" mode? Here are several practical application scenarios:
- Batch Research: Simultaneously researching financial data and business dynamics of 100 listed companies — parallel crawling, analysis, and summarization
- Literature Reviews: Batch downloading hundreds of academic papers, extracting key information, and generating structured literature reviews
- Data Processing: Complex data processing workflows with 1,500 steps, completed collaboratively by multiple Agents
Work that previously required a research team an entire week can be handled by K2.5's Agent cluster in ten to twenty minutes. This isn't a simple efficiency improvement — it's a fundamental transformation of work patterns, shifting from "humans directing AI to work" to "AI autonomously forming teams and collaborating."
MoE Architecture and the Strategic Significance of Open-Sourcing: Breaking the Closed-Source Monopoly
Kimi K2.5's decision to fully open-source carries strategic significance far beyond the technology itself.

For a long time, there has been a clear capability gap between open-source and closed-source commercial large models. Developers and enterprises faced an awkward choice: either pay to use GPT-4-level closed-source models, or settle for capability-compromised open-source alternatives. K2.5's emergence breaks this dynamic — it proves that open-source models can absolutely reach or even surpass the level of top closed-source models.
The evolution of the open-source large model ecosystem has passed through several key milestones: Meta released the LLaMA series in 2023, first bringing high-quality foundation models to the open-source community; Mistral subsequently proved the viability of the open-source route with small-parameter, high-performance models; the DeepSeek series achieved partial superiority over closed-source models in code and mathematical reasoning. However, in comprehensive capabilities (especially multimodal and Agent capabilities), a perceptible gap has persisted between open-source models and GPT-4o or Claude 3.5 Sonnet. The root cause of this gap lies in: hundreds of millions of dollars invested in RLHF (Reinforcement Learning from Human Feedback) data annotation behind top closed-source models, along with proprietary post-training alignment techniques. K2.5's open-sourcing isn't merely the release of parameter weights — more importantly, it brings a model of this capability level into the realm where the open-source community can study and improve upon it, with profound implications for both academia and industry.
From a technical architecture perspective, K2.5 employs a 1T parameter MoE (Mixture of Experts) architecture. The core idea of MoE originates from the mixture of experts system proposed by Jacobs et al. in 1991, but has been revitalized in the large language model era by organizations like Google and DeepMind. MoE's key mechanism is "sparse activation": the model consists of dozens or even hundreds of "expert" sub-networks, and during each inference, a lightweight "Router" dynamically selects 2-8 of the most relevant experts to participate in computation based on input content, while the remaining experts stay dormant. This means that although K2.5 has 1T total parameters, the actually activated parameters per inference may be only 1/8 or even less, dramatically reducing computational resource consumption. Google's Gemini 1.5, Mistral's Mixtral series, and DeepSeek-V2 all employ similar architectures, validating MoE's enormous potential in balancing model capability with inference efficiency. This gives K2.5 favorable cost-effectiveness in actual deployment, making local deployment feasible for SMEs and individual developers.
Hands-On Experience with Kimi K2.5 and Future Outlook
Currently, users can experience K2.5's capabilities through two entry points: the Kimi official website and Kimi Code. For developers, full open-sourcing means they can build upon K2.5 for secondary development, fine-tuning, and customized deployment, providing solid infrastructure for AI application implementation across industries.
From a broader perspective, K2.5's open-sourcing marks a new phase for China's large model ecosystem. It's no longer simply "catching up" — it's achieving "leading" positions on specific tracks. The Agent cluster's parallel processing capability pushes "digital employees" from the conceptual stage to a practical stage accessible to everyone.
Of course, the true value of an open-source model needs time to validate — community adoption rates, stability in production environments, and the maturity of the ecosystem toolchain are all critical factors determining whether K2.5 can truly become an open-source benchmark. But regardless, Moonshot AI's move here is both bold and solid.
Key Takeaways
- Kimi K2.5 is fully open-sourced with a 1T parameter MoE architecture, topping open-source leaderboards in AI programming and multimodal understanding, with some benchmarks surpassing GPT-4O and Claude 3.5
- Visual programming capability achieves breakthroughs, supporting high-fidelity code generation directly from screenshots, screen recordings, and even hand-drawn sketches, dramatically lowering the software development barrier
- Agent cluster mechanism supports up to 100 Agents processing complex tasks in parallel, compressing a team's week-long workload into roughly ten minutes
- Full open-sourcing breaks the closed-source model monopoly, providing developers and enterprises with free top-tier large model infrastructure
- Marks China's large model ecosystem shifting from catching up to leading, pushing digital employees from concept to universally accessible practice
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.