Moonshot K2.7 Code发布:推理token减少30%,编码性能全面提升
概述
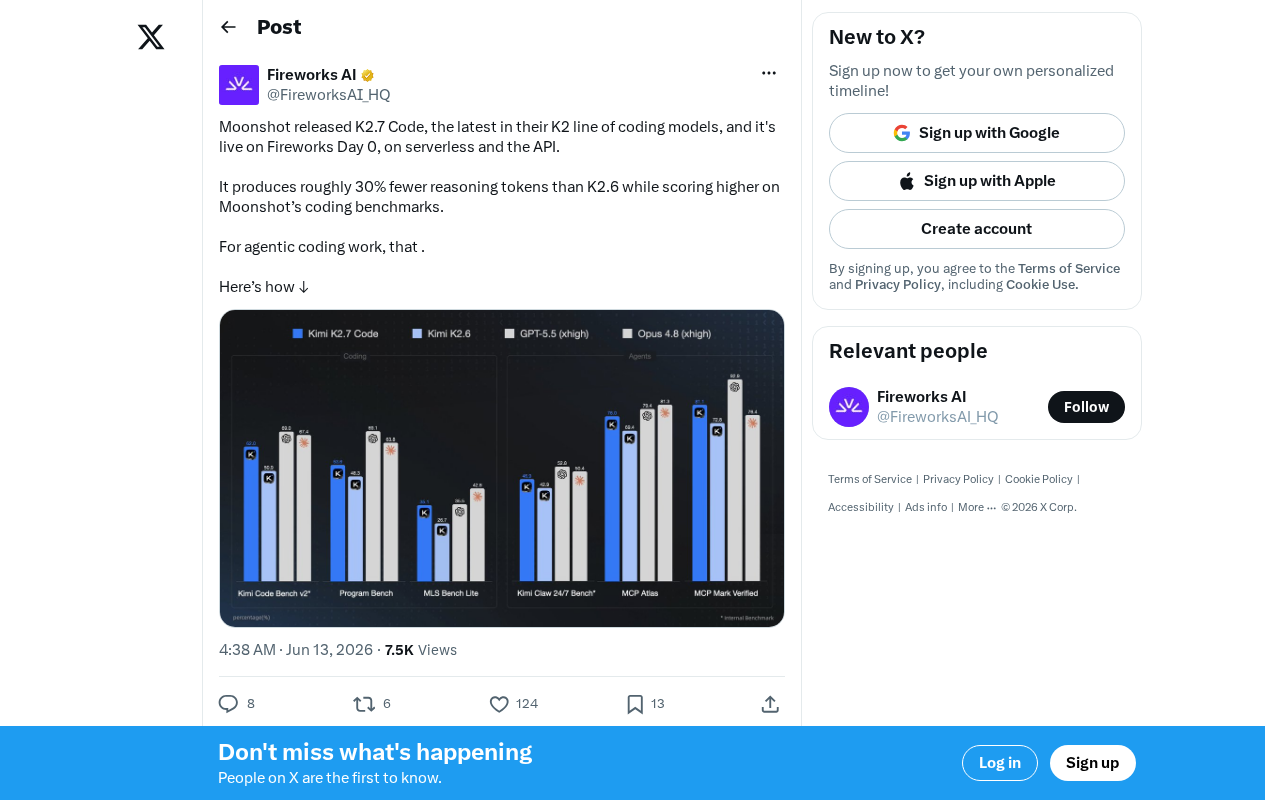
Moonshot近日发布了其K2系列编码模型的最新版本——K2.7 Code,该模型已在Fireworks平台上线,支持无服务器部署和API调用。相比前代K2.6,K2.7 Code在减少约30%推理token消耗的同时,在编码基准测试中取得了更高分数,这对于智能体编码(Agentic Coding)工作流来说意义重大。
Moonshot(月之暗面)是由清华大学校友杨植麟于2023年创立的AI公司,以其长上下文处理能力闻名,旗下消费级产品Kimi在中国市场拥有广泛用户基础。K2系列是Moonshot面向专业开发者和企业市场推出的编码专用模型线,定位与Anthropic的Claude Code、OpenAI的Codex等产品直接竞争。K2系列的迭代速度较快,从K2.6到K2.7的升级周期较短,反映了编码模型领域激烈的竞争态势。选择在Fireworks等海外推理平台上线,也体现了Moonshot拓展全球开发者市场的战略意图。
核心升级:更少token,更高性能
推理效率大幅提升
K2.7 Code最引人注目的改进在于推理效率的显著提升。与K2.6相比,新模型产生的推理token数量减少了约30%。这意味着在完成相同编码任务时,模型需要的"思考步骤"更少,响应速度更快,计算成本也相应降低。
要理解这一改进的技术含义,需要了解推理token的本质。推理token是指模型在生成最终答案之前,内部进行逐步推理所产生的中间token。这一机制源自"链式思维"(Chain-of-Thought, CoT)技术,最早由Google Brain团队在2022年的研究中系统性提出。在CoT范式下,模型不再直接输出答案,而是先生成一系列中间推理步骤,再得出结论。这种方式显著提升了复杂任务的准确率,但代价是token消耗量大幅增加。OpenAI的o1系列模型将这一思路推向极致,引入了专门的"思考token"概念——这些token对用户不可见,但会被计入API调用的token消耗中,在复杂数学或编码任务中,思考token的数量可能是最终输出token的数倍甚至数十倍。因此,K2.7 Code减少30%推理token而不损失性能,本质上意味着模型学会了更高效的推理路径压缩——跳过冗余的中间步骤,直达关键推理节点。
从技术实现角度看,推理路径压缩目前业界主要有几条技术路线:一是强化学习奖励塑形,在训练阶段对冗余推理步骤施加惩罚信号,引导模型学习更紧凑的推理链;二是蒸馏技术,将大型推理模型的高效推理模式迁移到目标模型中;三是推理时计算动态分配,让模型根据问题难度自适应调整思考深度——对简单问题快速作答,对复杂问题保留完整推理链。DeepSeek在其R1模型的技术报告中曾详细讨论过如何通过强化学习控制推理长度,而Anthropic也在多篇研究中探索了推理效率优化的方法。K2.7 Code的30%推理token缩减很可能综合运用了上述多种技术,在模型训练和推理阶段同时进行了优化。
对于大规模使用编码模型的团队和企业来说,30%的token节省直接转化为可观的成本降低和延迟优化。在按token计费的API调用模式下,这一改进的经济价值不容忽视。以一个中等规模的开发团队为例,如果每天通过API进行数千次编码任务调用,每次调用涉及数千到数万推理token,30%的节省意味着每月可能减少数千美元的API支出——这还不包括因延迟降低而带来的开发者生产力提升。
编码基准测试得分提升
说个细节,token数量的减少并非以牺牲性能为代价。根据Moonshot官方的编码基准测试结果,K2.7 Code的评分反而高于K2.6。这表明模型在推理质量上实现了质的飞跃——用更精炼的推理路径达到了更好的编码效果。
值得补充的是,当前编码模型的评测体系已经形成了多层次的基准测试框架。最基础的层面是HumanEval和MBPP等函数级代码生成测试,评估模型根据自然语言描述生成单个函数的能力。更高层面的是SWE-bench(Software Engineering Benchmark),由普林斯顿大学团队于2023年推出,它从真实的GitHub开源项目中提取实际的Issue和对应的Pull Request,要求模型在完整的代码仓库上下文中定位问题并生成修复补丁。SWE-bench已成为评估智能体编码能力的事实标准,其变体SWE-bench Verified进一步经过人工验证以确保评测质量。此外,还有Aider Polyglot(评估多语言编码能力)、LiveCodeBench(使用竞赛编程题目的动态评测集)等补充性基准。K2.7 Code在这些基准上的具体表现细节尚待Moonshot披露完整的评测报告,但"编码基准测试得分提升"这一表述通常意味着在上述多个维度上均有改善。
K2.7 Code对智能体编码的影响
为什么token效率对Agentic Coding至关重要
在智能体编码(Agentic Coding)场景中,AI模型需要执行多轮迭代操作:分析代码库、制定计划、编写代码、调试修复、运行测试等。每一轮交互都会消耗大量token,而一个完整的编码任务可能涉及数十甚至上百轮这样的交互。
智能体编码是2024年以来AI辅助开发领域最重要的范式转变之一。与传统的代码补全(如GitHub Copilot早期模式)不同,Agentic Coding赋予AI模型自主规划和执行能力:模型可以自行读取文件、执行终端命令、运行测试、根据错误信息迭代修复代码。代表性产品包括Cursor的Agent模式、Claude Code、Devin以及OpenAI的Codex。
从技术架构上看,智能体编码系统通常运行在一个Agent Loop(智能体循环)中:接收用户指令→分析当前代码库状态→选择并调用工具(如文件读写、终端命令执行、代码搜索、浏览器操作等)→观察工具返回结果→更新内部状态→决定下一步行动。这个循环的核心依赖于大模型的工具调用(Tool Use / Function Calling)能力——模型需要在每一步准确判断应该调用哪个工具、传入什么参数,并正确解析返回结果。关键在于,每一轮循环都需要将完整的对话历史、系统提示词、工具定义和之前所有工具的返回结果作为上下文输入给模型,这意味着随着循环次数增加,每轮的输入token量也在持续增长。在一个涉及50轮工具调用的复杂任务中,后期每轮的上下文输入可能达到数万token,加上模型自身的推理token和输出token,总消耗量极为可观。
在这种场景下,每轮交互节省30%的推理token,累积效应是惊人的。假设一个复杂的编码任务需要50轮交互,token节省量将呈线性累加,最终可能节省数万甚至数十万token。这不仅降低了成本,还加快了整体任务完成速度。更重要的是,推理token的减少还可能带来间接的效率收益:更短的推理链意味着模型在每一轮中更快地做出决策,减少了整个Agent Loop的端到端延迟,这对于需要实时交互的开发场景(如开发者在IDE中等待AI完成任务)尤为关键。
实际应用场景
对于使用AI编码助手进行以下工作的开发者,K2.7 Code的效率提升尤为明显:
- 大型代码重构:需要模型理解整体架构并逐步修改多个文件。在大型重构任务中,模型可能需要先遍历数十个文件以理解项目结构,然后制定重构计划,再逐文件进行修改并确保各文件间的接口一致性,整个过程可能涉及上百轮工具调用。
- 自动化测试生成:需要多轮迭代确保测试覆盖率。模型需要分析被测代码的逻辑分支、边界条件和异常路径,生成测试用例后还需运行测试、分析失败原因并迭代修复,直到达到目标覆盖率。
- Bug修复流程:从定位问题到验证修复的完整链路。这通常包括复现问题、阅读相关代码、定位根因、编写修复代码、运行回归测试等多个步骤,每一步都需要模型与代码库和终端进行交互。
- 多文件协同开发:需要在不同文件间保持上下文一致性。例如在前后端联调场景中,模型需要同时理解API定义、后端实现和前端调用代码,确保数据结构和接口协议的一致性。
Fireworks平台即时可用
K2.7 Code已在Fireworks平台的Day 0计划中上线,开发者可以通过无服务器(Serverless)方式和标准API立即使用。这种快速部署模式意味着开发者无需等待,即可将最新模型集成到现有工作流中。
Fireworks AI是一家专注于大模型推理基础设施的公司,由前Meta PyTorch团队核心成员创立。其核心竞争力在于高性能的模型推理引擎FireAttention,能够在保持低延迟的同时实现高吞吐量。无服务器(Serverless)部署模式意味着开发者无需自行管理GPU实例、处理扩缩容和负载均衡等运维工作,只需通过API调用即可使用模型,按实际消耗的token量付费。Fireworks的Day 0计划则是其与模型厂商合作的快速上线机制,确保新模型发布当天即可在平台上被开发者调用,这种模式大幅缩短了从模型发布到生产可用之间的时间差。
值得关注的是,Fireworks所处的推理基础设施赛道本身也正处于激烈竞争之中。Together AI提供类似的模型推理托管服务,并在开源模型微调领域有独特优势;Groq凭借其自研的LPU(Language Processing Unit)芯片实现了极低延迟的推理体验,在实时交互场景中表现突出;Cerebras则以其晶圆级芯片WSE(Wafer Scale Engine)提供超高吞吐量的推理服务。此外,云计算巨头如AWS(通过Bedrock)、Google Cloud(通过Vertex AI)和Azure也在积极布局模型推理服务。推理平台的竞争对模型厂商而言是利好——更多的分发渠道意味着更广泛的开发者触达,而对开发者而言,多平台可用性也提供了更灵活的选择和更有竞争力的定价。Moonshot选择Fireworks作为K2.7 Code的首发推理平台之一,既看中了其在开发者社区中的影响力,也受益于Fireworks在推理性能优化方面的技术积累。
行业趋势观察
K2.7 Code的发布反映了当前AI编码模型发展的一个重要趋势:在保持或提升性能的前提下,大幅优化推理效率。随着智能体编码成为主流开发范式,模型的token效率将成为与准确性同等重要的竞争维度。
未来,我们可以预期更多模型厂商将在"推理密度"——即单位token产出的有效信息量——这一指标上展开竞争。推理密度这一概念正在成为评估推理模型的新维度。传统上,模型竞争主要围绕基准测试分数展开,但随着推理模型的普及,业界逐渐意识到"以多少计算代价达到某一性能水平"同样重要。DeepSeek-R1的成功部分归因于其在较低计算成本下实现了接近顶尖模型的推理能力。类似地,Anthropic在Claude 3.5 Sonnet中也展示了通过模型架构优化而非单纯扩大规模来提升效率的路线。这一趋势的底层逻辑是:当模型能力趋于同质化时,效率和成本将成为差异化竞争的核心战场,尤其在企业级大规模部署场景中。
这一趋势还与更宏观的行业动态相互呼应。2024年下半年以来,"Scaling Law是否触顶"的讨论在业界持续发酵。越来越多的证据表明,单纯通过增加预训练数据和模型参数来提升性能的边际收益正在递减。作为回应,业界的关注点正在从训练时计算(Train-time Compute)向推理时计算(Test-time Compute / Inference-time Compute)转移——即通过在推理阶段投入更多计算资源(如更长的思考链、多次采样后投票等)来提升模型表现。但这一路线的可持续性同样取决于推理效率的优化。如果每次推理都需要消耗海量token,那么推理时计算扩展的经济性将受到严重制约。因此,K2.7 Code所代表的"用更少token实现更好性能"的方向,实际上是推理时计算范式能否大规模落地的关键技术支撑之一。
核心要点
- K2.7 Code实现了效率与性能的双重突破:推理token减少约30%的同时,编码基准测试得分超越前代K2.6,证明了推理路径压缩技术的成熟度。
- 智能体编码场景是最大受益者:在需要数十轮工具调用的Agentic Coding工作流中,单轮30%的token节省会产生显著的累积效应,大幅降低成本并缩短任务完成时间。
- 推理密度正在成为模型竞争的新维度:随着模型基准性能趋于同质化,"以多少计算代价达到某一性能水平"将成为企业选型的关键考量因素。
- 推理基础设施生态日趋成熟:Fireworks等平台的Day 0上线机制使新模型能够快速触达全球开发者,缩短了从发布到生产部署的时间差。
- 中国AI公司的全球化布局加速:Moonshot选择在海外推理平台首发K2.7 Code,反映了中国头部AI公司在编码模型领域参与全球竞争的战略决心。
相关推荐
GML 5.2多模态升级实测:DeepSeek V4全面跑通验证
基于OneBlockBase平台实测GML 5.2与DeepSeek V4多模态升级,详解视觉识别与文本协同工作流搭建、前置拦截安全机制、界面生成效果及部署配置要点,验证纯文本模型通过工作流编排升级多模态的可行方案。
DeepSeek+Cline配置教程:10元替代月费20美金的AI编程方案
详解DeepSeek API搭配VS Code插件Cline的完整配置流程,包括API Key获取、Plan/Act双模型策略、项目管理文件体系等进阶技巧,10元充值即可获得接近顶尖水平的AI编程体验。
5步让Codex接入DeepSeek,无需GPT账号也能用
详细图文教程:通过CC Switch中转工具,5步将Codex接入DeepSeek API,无需GPT账号即可使用AI编程助手的全部功能,包括代码补全、技能插件等,成本更低体验无损。