NoteGen MCP配置教程:三步搞定AI工具连接
什么是MCP?先别急着导入服务器
MCP(Model Context Protocol)近来成为AI应用生态中的热门概念,但很多人一上来就急着导入一堆服务器,结果环境没配好、工具没选对,反而把自己搞晕了。
MCP本质上是AI调用外部工具的一套连接协议。 它并不会让模型本身变得更聪明,而是赋予模型一组可以被授权使用的外部工具——比如文件操作、数据查询、自动化脚本等。理解了这一点,配置思路就清晰了:先确认环境,再添加服务器,最后选择要给对话使用的工具。
MCP由Anthropic于2024年底正式开源发布,其设计灵感来源于编程领域的LSP(Language Server Protocol)。LSP通过标准化编辑器与语言服务之间的通信,让任何编辑器都能支持任何编程语言的智能补全。MCP借鉴了这一思路,将AI模型与外部数据源、工具之间的交互标准化。在MCP出现之前,每个AI应用想要调用外部工具,都需要自己实现一套集成逻辑,导致生态碎片化严重。MCP通过定义统一的Client-Server架构,让工具提供方只需实现一次MCP Server,就能被所有支持MCP的AI客户端调用。这种标准化带来的网络效应非常显著——随着支持MCP的客户端越来越多(如Claude Desktop、Cursor、NoteGen等),工具开发者的投入产出比大幅提升;反过来,丰富的工具生态又吸引更多客户端接入MCP,形成正向循环。从协议层面看,MCP定义了三种核心原语:Tools(工具,模型可主动调用的函数)、Resources(资源,模型可读取的数据源)和Prompts(提示模板,预定义的交互模式),这三者共同构成了AI与外部世界交互的完整能力集。
NoteGen作为一款笔记与AI结合的工具,其MCP配置流程设计得相当规范。本文以NoteGen为例,拆解MCP配置的三个关键步骤。
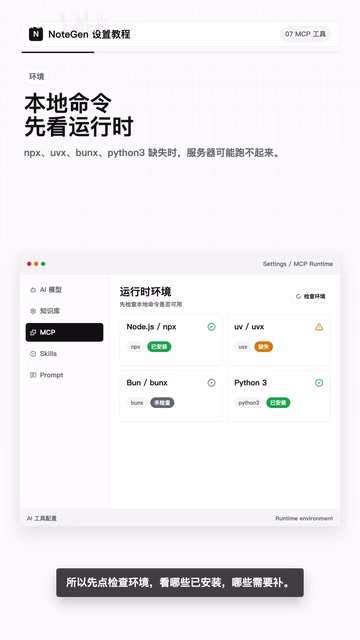
第一步:运行时环境检查
这是最容易被忽略、却最常导致问题的环节。
NoteGen桌面端会检查本地是否安装了以下命令行工具:
- NPX(Node.js包执行器)
- UVX(Python包管理工具)
- BUNX(Bun运行时)
- Python3
这些工具各自承担不同的角色:NPX是Node.js自带的包执行器(随npm 5.2+版本自动安装),允许直接运行npm包中的命令行工具而无需全局安装,其核心价值在于避免全局依赖污染,每次执行时都能确保使用最新版本的包;UVX是Astral公司推出的Python工具执行器,属于uv生态的一部分,uv本身是用Rust编写的超高速Python包管理器(比传统pip快10-100倍),UVX能在毫秒级时间内创建隔离的虚拟环境来运行Python编写的MCP服务器,解决了Python生态中长期存在的依赖冲突问题;BUNX则是Bun运行时的包执行器,Bun是一个基于JavaScriptCore引擎(Safari浏览器使用的同款引擎)的高性能JavaScript运行时,其冷启动速度比Node.js快约4倍,在需要频繁启停MCP服务器的场景下优势明显。这些工具本质上都在做同一件事:为MCP服务器提供运行环境。不同的MCP服务器可能用不同语言编写,因此需要对应的运行时来执行它们。目前MCP生态中,大约60%的服务器使用TypeScript/JavaScript编写(通过NPX或BUNX运行),30%使用Python编写(通过UVX运行),其余使用Go、Rust等语言编写为独立二进制文件。
很多人遇到MCP服务器跑不起来的情况,第一反应是去检查服务器配置,但实际上问题往往出在运行时环境缺失。比如一个基于Node.js的MCP服务器,如果本地没有安装NPX,自然无法启动。常见的环境问题还包括:PATH环境变量未正确配置导致命令找不到、Node.js版本过低不支持某些ES模块语法、Python虚拟环境权限不足等。
操作建议: 在NoteGen中点击"检查环境"按钮,确认哪些运行时已安装、哪些需要补装。把环境问题在最开始就解决掉,后续配置会顺畅很多。
移动端的特殊限制
需要特别注意的是,移动端不支持本地命令型MCP服务器。这很好理解——手机上没有完整的命令行环境。iOS和Android的应用沙箱机制严格限制了应用启动子进程的能力,且移动操作系统通常不预装Node.js、Python等开发运行时。因此在移动端使用MCP时,只保留HTTP类型的服务器即可。这也意味着,如果你需要在移动端使用某些原本只有本地命令型实现的MCP服务器,需要寻找其对应的云端托管版本,或者自行将其部署为HTTP服务。
第二步:MCP服务器列表管理
环境就绪后,就可以开始添加MCP服务器了。一个MCP服务器可以提供一组工具和资源,不同功能可以分成不同服务器来管理,比如文件操作类、数据处理类、自动化类各自独立。
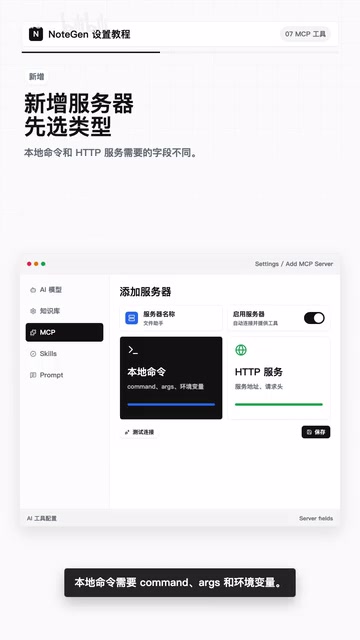
新增服务器的配置要素
新增MCP服务器时需要关注以下几点:
- 名称:给服务器起一个一眼能看懂的名称,方便后续管理
- 类型选择:本地命令型或HTTP服务型
- 本地命令型:需要配置Command(执行命令)、Args(参数)和环境变量
- HTTP服务型:需要配置服务地址和请求头
- JSON导入:如果你拿到的是现成的JSON配置文件,可以直接通过导入入口导入。系统会自动识别常见的服务器配置格式,已有同名项会自动跳过,避免重复。
从架构层面来看,这两种类型存在本质差异。本地命令型MCP服务器通过stdio(标准输入输出)与客户端通信,客户端会启动一个子进程来运行服务器程序,数据通过进程间的stdin/stdout管道传递。具体来说,客户端将JSON-RPC格式的请求写入子进程的stdin,服务器处理后将响应写入stdout,整个过程基于行分隔的JSON消息流。这种方式的优势是完全本地化,数据不出设备,延迟极低(通常在毫秒级),且不需要网络连接。HTTP服务型则通过SSE(Server-Sent Events)或更新的Streamable HTTP传输与远程服务器通信。SSE是一种基于HTTP的单向推送协议,服务器可以持续向客户端发送事件流,非常适合MCP中服务器主动推送工具执行进度的场景。2025年初,MCP协议进一步引入了Streamable HTTP传输方式,它在单个HTTP端点上同时支持请求-响应和服务器推送两种模式,简化了部署复杂度。HTTP服务型适用于需要访问云端资源(如数据库、第三方API)或在移动端等受限环境中使用的场景。两种类型在MCP协议层面的功能完全一致,区别仅在于传输层的实现方式——这正是MCP协议分层设计的优雅之处。
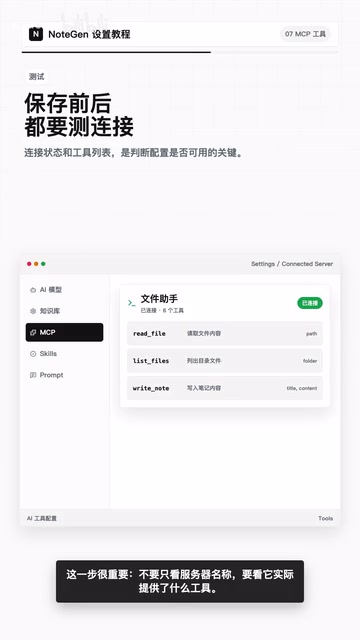
测试连接:不要跳过这一步
配置完成后,保存前务必先测试连接。连接成功后,列表中会显示"已连接"状态。更重要的是,如果服务器暴露了工具,你可以展开查看具体的工具数量、工具名称和参数信息。
这一步非常关键——不要只看服务器名称,要看它实际提供了什么工具。 一个名为"文件助手"的服务器,可能提供的是读取、写入、删除等多个具体工具,也可能只提供了读取功能。只有了解清楚,才能在后续对话中做出正确选择。测试连接的过程实际上触发了MCP协议中的初始化握手(Initialize Handshake):客户端发送initialize请求,服务器返回其支持的协议版本、能力声明(capabilities)以及所有可用工具的完整定义(包括名称、描述、输入参数的JSON Schema)。这个握手过程确保了客户端和服务器之间的兼容性,也让用户能在使用前完整了解服务器的能力边界。
第三步:工具启用与精准选择
这是NoteGen在MCP设计上最值得称道的地方——两级控制机制。
启用 ≠ 使用
启用一个服务器,意味着它可以自动连接并提供工具。但真正在一次聊天中使用它,还需要在聊天输入区手动选择对应的服务器。
这样设计的逻辑很清晰:工具越多,AI的选择成本越高,误用风险也越高。 如果每次对话都把所有工具一股脑交给AI,模型可能会在不必要的场景下调用不相关的工具,既浪费token,又可能产生意料之外的操作。
从技术实现角度来说,当AI模型被授权使用MCP工具时,所有可用工具的名称、描述和参数定义都会作为系统提示的一部分被注入到上下文中。这些工具定义遵循OpenAI提出的Function Calling格式(现已成为行业事实标准),每个工具被描述为一个包含name、description和parameters字段的JSON对象,其中parameters使用JSON Schema规范来定义输入参数的类型、约束和说明。以GPT-4级别的模型为例,每个工具定义大约消耗200-500个token(取决于参数复杂度和描述详细程度)。如果同时暴露20个工具,仅工具描述就可能占用4000-10000个token,这直接压缩了用户对话的可用上下文窗口。以Claude 3.5 Sonnet的200K上下文窗口为例,10000个token的工具描述占比看似不大,但在多轮长对话中,这部分开销会在每一轮都重复计入,累积效应不容忽视。更关键的是,工具数量越多,模型在推理时的决策分支越复杂,误调用的概率也会相应上升。研究表明,当可用工具超过15个时,模型选择正确工具的准确率会出现明显下降,尤其是当多个工具的功能描述存在语义重叠时。
按需分配的实践原则
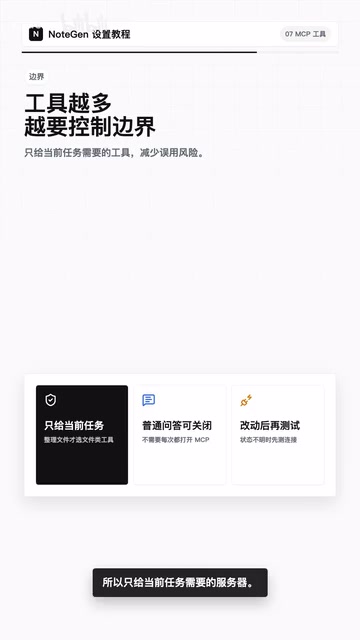
具体操作建议:
- 整理本地文件时,只选择文件类服务器
- 普通问答场景,不一定要打开任何MCP服务器
- 不用的服务器先停用,不必急着删除配置,改天可能还会用到
- 修改配置后,记得重新测试一次连接
这种"最小权限"的思路,和软件工程中的安全设计原则一脉相承。最小权限原则(Principle of Least Privilege)是信息安全领域的核心原则之一,最早由Jerome Saltzer和Michael Schroeder在1975年的论文《The Protection of Information in Computer Systems》中系统阐述。其核心含义是:任何实体(用户、程序、系统)在任何时刻都只应拥有完成当前任务所必需的最小权限集合。这一原则在操作系统设计(如Unix的用户权限模型)、数据库访问控制(如SQL的GRANT/REVOKE机制)、云计算(如AWS的IAM策略)中都有广泛应用。在MCP场景中,这意味着不应让AI在讨论天气时拥有删除文件的能力——即使模型"知道"不该删除文件,但从系统安全的角度看,不授予不必要的权限永远比依赖模型的"自觉"更可靠。NoteGen的两级控制机制正是这一原则的具象化实践——服务器启用是能力声明(capability declaration),聊天中选择是权限授予(permission granting)。这种设计在AI Agent安全领域被称为"Human-in-the-Loop"模式的轻量化实现,它在自动化效率和安全可控之间取得了良好的平衡。
MCP的安全感来自于可控——你清楚地知道连的是谁、提供哪些工具、什么时候给AI用。
初学者的MCP配置路径
如果你是第一次接触MCP,建议遵循以下渐进路径:
- 从一个服务器开始,不要贪多
- 跑通完整流程:环境检查 → 添加服务器 → 测试连接 → 查看工具列表 → 在聊天中选择使用
- 确认理解每个环节后,再逐步增加更多服务器
对于第一个MCP服务器的选择,建议从官方维护的参考实现开始。Anthropic在GitHub上维护了一系列官方MCP服务器,包括文件系统(filesystem)、Git操作、SQLite数据库等,这些服务器经过充分测试,文档完善,非常适合作为学习MCP的起点。社区也维护了一个名为"Awesome MCP Servers"的列表,收录了数百个第三方MCP服务器,涵盖从Notion、Slack等SaaS工具集成到本地浏览器控制、图像生成等各种场景。
配置MCP的关键不是数量,而是边界清楚。 知道每个服务器能做什么、不能做什么,比拥有一长串服务器列表重要得多。
总结
MCP为AI应用打开了连接外部工具的大门,但这扇门需要有序地打开。NoteGen的三步配置流程——环境检查、服务器管理、精准选择——提供了一个清晰的操作框架。核心理念始终是:可控优先,按需使用,逐步扩展。 掌握了这个思路,无论是NoteGen还是其他支持MCP的应用,配置起来都会得心应手。
从更宏观的视角来看,MCP正在成为AI应用生态的基础设施层。正如HTTP协议统一了Web世界的通信方式,MCP有望统一AI与工具世界的交互方式。随着协议的持续演进(如2025年引入的OAuth 2.1认证支持、Elicitation交互机制等),MCP的能力边界还在不断扩展。对于普通用户而言,现在正是学习和实践MCP的最佳时机——生态足够成熟可以实际使用,又足够早期可以建立先发优势。
核心要点
相关推荐
GML 5.2多模态升级实测:DeepSeek V4全面跑通验证
基于OneBlockBase平台实测GML 5.2与DeepSeek V4多模态升级,详解视觉识别与文本协同工作流搭建、前置拦截安全机制、界面生成效果及部署配置要点,验证纯文本模型通过工作流编排升级多模态的可行方案。
DeepSeek+Cline配置教程:10元替代月费20美金的AI编程方案
详解DeepSeek API搭配VS Code插件Cline的完整配置流程,包括API Key获取、Plan/Act双模型策略、项目管理文件体系等进阶技巧,10元充值即可获得接近顶尖水平的AI编程体验。
5步让Codex接入DeepSeek,无需GPT账号也能用
详细图文教程:通过CC Switch中转工具,5步将Codex接入DeepSeek API,无需GPT账号即可使用AI编程助手的全部功能,包括代码补全、技能插件等,成本更低体验无损。