Qwen3.7 Max深度解读:1T参数MoE架构与智能体全框架兼容

阿里Qwen3.7 Max以1T参数MoE架构打造全面兼容主流智能体框架的"大一统"模型
阿里发布的Qwen3.7 Max采用约1T参数MoE架构和256K上下文窗口,在智能体编程、通用智能体、高难度推理和多语言支持四大维度表现突出。其核心卖点是对LangChain、Claude Code、Hermes等主流智能体框架的全面兼容,体现"好司机不挑车"的底层能力泛化。该模型还引发了关于强基座模型能否降低对Harness工具链依赖的行业争论,阿里通过环境驱动的工具训练方法为"模型优先"观点提供了证据。
阿里千问的「大一统」模型:Qwen3.7 Max到底强在哪
阿里最新发布的Qwen3.7 Max模型,不仅在参数规模和性能指标上刷新了记录,更展现了一种全新的产品理念——做一个「全球大一统」的模型。从官方宣传图中巧妙植入的LangChain、Hermes、Claude Code等智能体框架元素就能看出,这款模型的核心卖点不仅是单项能力的突破,更是对主流智能体生态的全面兼容。
值得注意的是,这三类元素代表了当前智能体技术栈的不同层次:LangChain是目前最主流的LLM应用开发框架,由Harrison Chase于2022年创立,提供链式调用、记忆管理、工具集成等标准化组件;Claude Code是Anthropic推出的面向软件工程场景的垂直智能体产品;Hermes则是专注于工具调用(Function Calling)能力优化的模型微调系列。同时兼容这三类产品,意味着Qwen3.7 Max的兼容性覆盖了整个智能体技术栈的纵深。
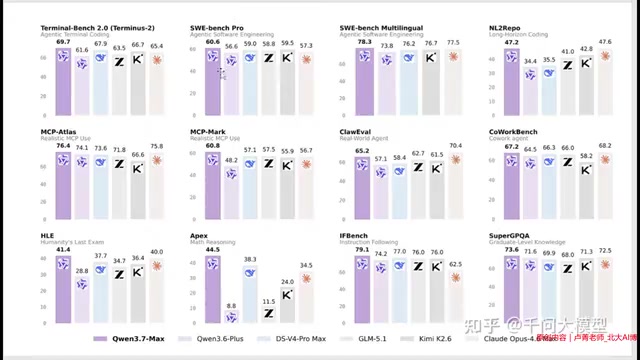
从基础参数来看,Qwen3.7 Max采用了约1T参数的MoE(混合专家)架构,上下文窗口达到256K token。MoE(Mixture of Experts)是一种稀疏激活的神经网络设计,其核心思想是将模型参数分组为多个「专家」子网络,每次推理时只激活其中一小部分——通常仅为总参数的10%-20%。这与传统密集模型(Dense Model)每次推理激活全部参数的方式形成鲜明对比。MoE架构最早由Jacobs等人在1991年提出,但真正在大语言模型领域大放异彩是在2022年后,Google的Switch Transformer和Mistral的Mixtral 8x7B等模型验证了其工业规模可行性。因此,1T参数的MoE模型实际推理计算成本远低于同等规模的密集模型,在「模型能力天花板」和「推理经济性」之间找到了出色的平衡点。虽然256K的上下文长度在当前模型中并非最顶尖,但这种架构组合本身已构成显著的竞争优势。
四大核心能力:Qwen3.7 Max的全方位性能表现
从官方公布的评测数据来看,Qwen3.7 Max在四个关键维度上均展现出明显的竞争力。
智能体编程:开发者最关注的能力高地
智能体编程是当前AI应用最火热的方向,也是开发者最关注的能力。Qwen3.7 Max在这一领域的表现被官方描述为「战绩非常强悍」。在代码生成、工具调用、长流程任务执行等场景中,该模型能够胜任复杂的编程智能体任务,对标Claude Code等主流方案毫不逊色。
通用智能体与桌面自动化能力
在通用智能体场景中,包括桌面应用操控、网页交互、工具调用等任务,Qwen3.7 Max同样展现出小幅但明显的领先优势。这种「通用性」正是阿里所追求的——不是在某个特定场景下做到最好,而是在所有场景下都保持高水准。
高难度推理与多语言支持背后的商业逻辑
在数学推理、逻辑分析等高智力强度任务上,Qwen3.7 Max同样保持了领先地位。而多语言能力的强化则暴露了阿里更深层的商业考量:在Token经济时代,通过API服务向海外输出算力,本质上是一种「用Token卖中国电力」的新型出口经济模式。
所谓「Token经济」,是指以API调用中的Token消耗为计费单位的商业模式——每个Token大约对应0.75个英文单词或0.5个中文字符。从宏观经济视角看,大模型推理本质上是高度密集的算力消耗,而中国在电力成本和数据中心建设上具有相对优势。当海外用户通过API调用中国大模型时,实际上是在购买中国的算力资源,这与传统制造业出口商品的逻辑高度相似,只是出口的「商品」从实物变成了计算服务。全球非英语用户的规模远超英语用户,多语言能力越强,海外用户的付费意愿就越高——这正是阿里强化多语言能力的核心商业驱动力。
框架兼容性测试:为什么说「好司机不挑车」
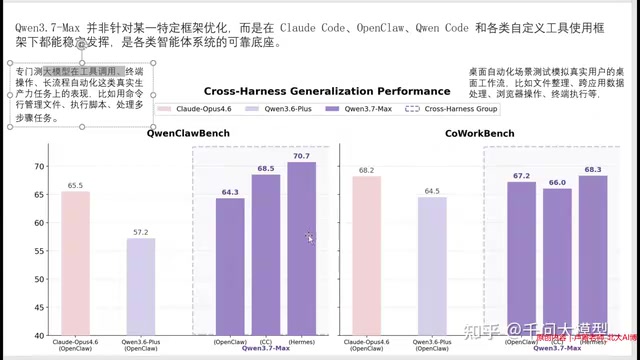
Qwen3.7 Max最值得关注的特性之一,是其对不同智能体框架的广泛兼容性。官方分别在Claude Code、LangChain等多个主流智能体框架上进行了测试,结果显示在工具调用、终端操作、长流程任务等评测指标上,Qwen3.7 Max均表现优异。
这传递了一个明确的信号:模型的强大不应依赖于特定框架的适配,而应该是一种底层能力的体现。 用一个形象的比喻来说,就是「好司机不挑车」——无论你使用什么智能体框架,Qwen3.7 Max都能发挥出稳定的性能。
在桌面自动化场景中,该模型同样超越了Claude系列模型以及自家的Qwen3.6,进一步验证了这种框架无关的泛化能力。
模型能力与Harness依赖:行业尚未定论的核心争论
Qwen3.7 Max的表现引发了一个业界持续争论的话题:当基座模型足够强大时,对Harness(工具链/框架层)的依赖是否可以降低?
「Harness」在AI工程语境中泛指围绕基座模型构建的工具链和框架层,包括提示词工程(Prompt Engineering)、检索增强生成(RAG)、工具调用编排、错误重试机制、输出格式校验等。早期大模型能力有限时,精心设计的Harness往往能将模型实际表现提升数倍,催生了大量专注于「模型包装」的创业公司和开源项目。然而随着GPT-4、Claude 3等强大基座模型的出现,部分原本需要Harness解决的问题(如格式遵循、多步推理、工具调用)已被模型内化,导致「Harness税」的边际价值下降。这场争论的本质是:AI应用的核心竞争力究竟在于模型层还是工程层?
目前存在两种对立的观点:
-
Harness优先派认为,模型天然存在缺陷,必须通过强大的Harness来打各种「补丁」,弥补模型的不足。精心设计的提示词工程、工具编排、错误恢复机制等都是不可或缺的。
-
模型优先派则认为,只要基座模型足够强大,对Harness的依赖就可以显著降低。Harness仍然需要,但不再是决定性因素。
阿里通过Qwen3.7 Max似乎在为后一种观点提供证据。从训练数据来看,模型采用了环境驱动的工具训练方法——这是强化学习在大模型训练中的一种具体应用形式。与传统监督微调(SFT)不同,这种方法让模型在真实或模拟环境中执行工具调用任务,并根据执行结果(成功/失败/部分成功)获得奖励信号,通过强化学习迭代优化工
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。