35 Lines of Prompts Let Codex Auto-Optimize Your Workflow — Reposted by OpenAI's President
35 Lines of Prompts Let Codex Auto-Opt…
35 lines of prompts let Codex auto-identify repetitive work and generate reusable automation Skills
An OpenAI employee shared an advanced technique: using 35 lines of prompts to have Codex review 30 days of work history, automatically identify repetitive tasks, and package them into reusable Skills. Combined with screen reading and long-term memory features, Codex can capture behavior patterns beyond the chat interface and intelligently determine which tasks are worth automating. The approach works for programmers, operations managers, planners, and more — with the core insight being the transformation of AI from a passive Q&A tool into an intelligent agent that proactively audits work habits.
An OpenAI employee recently shared an exciting technique: with just 35 lines of prompts, you can have Codex automatically analyze your past 30 days of work history, identify repetitive tasks, and package them into reusable automated Skills. The tweet even earned a personal repost and like from OpenAI's president.
Core Principle: Let AI Audit Your Work Habits
The core idea behind this technique is crystal clear — feed a carefully crafted prompt to Codex, have it look back through your past 30 days of conversation history and task data, and mine out the things you do repeatedly every day.
Things like repeatedly loading documents, fixing bugs, organizing materials, writing weekly reports… these seemingly trivial but daily time-consuming operations are all identified one by one by Codex.
Codex Technical Background: OpenAI Codex is a large language model fine-tuned specifically for code understanding and generation tasks based on the GPT architecture, originally released in 2021 as the underlying engine for GitHub Copilot. In 2025, OpenAI relaunched a cloud-based AI coding agent under the Codex name, upgrading its positioning from a simple code completion tool to an intelligent agent system capable of autonomous planning and multi-step task execution. The new Codex runs in a sandboxed environment, can read and write files, execute terminal commands, call external APIs, and accumulate contextual memory through continuous interaction with users — essentially combining LLM language understanding capabilities with OS-level execution abilities.

After identification, Codex categorizes and handles tasks by their nature:
- Reusable ones: Packaged directly into Skills (skill templates) for one-click invocation next time
- Ones requiring specialized roles: Dispatched to Sub-Agents for execution
- Scheduled check tasks: Set up as automated workflows that don't need human monitoring
Skill and Agent Architecture Explained: In AI agent system design paradigms, a Skill refers to the mechanism of encapsulating a reusable task logic into a standardized module, similar to functions or microservices in software engineering. When an agent identifies a highly repetitive task, it abstracts the execution steps, required parameters, and expected outputs into a callable Skill that can be directly invoked for similar future tasks without re-reasoning. Sub-Agents are a core concept in multi-agent architectures: the main agent (Orchestrator) handles task decomposition and scheduling, delegating specific subtasks to specialized sub-agents for parallel or sequential execution. This layered architecture borrows from the microservices philosophy in software engineering, significantly improving processing efficiency and maintainability for complex tasks. It's the mainstream design pattern in current AI Agent frameworks (such as AutoGPT, LangGraph, OpenAI Swarm).
Crucially, Codex doesn't blindly automate everything. It first makes a judgment: Has this task appeared at least twice? Will it continue to occur in the future? Is the process stable enough? Is it worth the automation investment? Only when all these conditions are met does it start taking action.
Screen Reading + Long-Term Memory: Breaking Beyond the Chat Box
Codex recently launched a screen reading feature, taking this entire technique to the next level.
With this capability enabled, Codex can not only analyze your operations within the chat interface but also "see" what you're doing in browsers, office software, email clients, and other applications. In other words, it can capture repetitive behavior patterns outside of Codex itself.
Screen Reading Technical Principles: Codex's screen reading feature is an extension of multimodal perception capabilities, with its underlying technology relying on computer vision models (such as GPT-4V/GPT-4o's visual understanding capabilities) to semantically parse screenshots or real-time screen content. Technically, the system periodically captures user screen content, extracts text information through OCR (Optical Character Recognition), while simultaneously using vision models to understand UI element layouts and states, then converts this information into structured behavior logs for language model analysis. This capability is highly similar to the technical approaches of Anthropic's Claude Computer Use and Google's Project Mariner, representing an important trend of AI penetrating from "language space" into "operational space." Its core value lies in breaking the limitation where AI can only perceive content actively input by users, enabling it to passively observe users' real workflows.

Combined with Codex's memory feature — the ability to long-term remember your personal preferences, project context, and historical corrections — Codex is increasingly resembling an AI colleague that observes your work habits and proactively helps streamline your workflow.
Technical Implementation of Long-Term Memory: Large language models are inherently stateless — after each conversation ends, the model doesn't automatically retain any information. AI systems typically implement "long-term memory" through external storage mechanisms: serializing important information (user preferences, project context, historical decisions) into vector databases (such as Pinecone, Weaviate) or structured databases, then injecting relevant memories into the context window via RAG (Retrieval-Augmented Generation) technology when new conversations begin. The memory features OpenAI has implemented in ChatGPT and Codex are precisely the productization of this architecture. The quality of the memory system directly determines the degree of "personalization" of an AI agent — the more precise the memory, the better the agent understands users' work habits and implicit preferences, thereby reducing repetitive communication costs. This is also the technical prerequisite enabling Codex to "proactively audit work habits."
Moreover, this approach is far from limited to programmers. Writers, operations managers, planners — anyone whose work involves repetitive labor can benefit from it.
Community Response and Token Cost Considerations
Once shared, the community response was extremely enthusiastic. Many users immediately reported "this is insane" after trying it, calling for it to be made into an official plugin. OpenAI's president personally reposted and liked it after seeing it, demonstrating the level of recognition.
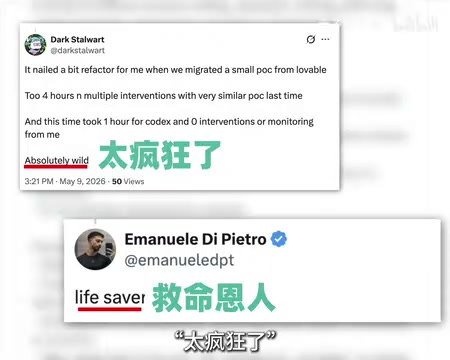
Of course, some raised practical concerns: reviewing 30 days of history — how many tokens and credits does that consume? For regular users, is this expense worthwhile?
Quantifying Token Costs: Tokens are the basic unit of measurement for text processing in large language models — roughly, each English word corresponds to about 1-1.5 tokens, and each Chinese character corresponds to about 1-2 tokens. Looking back through 30 days of conversation history, if each day averages 500-1,000 tokens of interaction content, the 30-day cumulative total is approximately 15,000-30,000 input tokens. Adding Codex's analysis and Skill generation output tokens, a single audit's total consumption could be in the 50,000-100,000 token range. Based on GPT-4o's current pricing (approximately $2.5/million input tokens, $10/million output tokens), a single complete audit would cost roughly $0.5-$2 USD, which is acceptable for heavy users. However, if executed frequently or with larger historical data volumes, costs scale linearly — this is the fundamental reason community users raised the practical question of "whether the token expense is worthwhile."
However, the person who shared this didn't directly address the question — as an OpenAI internal employee, token consumption probably isn't something they need to worry about.
Other Advanced Codex Techniques from This Employee
This OpenAI employee regularly experiments and frequently shares advanced Codex usage tips on social media. For example:
- Using Codex to configure a Raspberry Pi: Ensuring the device can be remotely accessed after connecting to home WiFi
- Loop command mode: Defining a completion state for Codex, telling it "what success looks like," then having it loop execution until the goal is achieved
Loop Command Mode and Goal-Oriented Execution: Loop command mode (also called "goal-oriented loop execution") is an important task execution paradigm in AI agent systems, with its core concept derived from feedback loops in cybernetics. Traditional AI usage follows a single request-response pattern, while Loop mode has the agent continuously execute a "perceive → plan → act → evaluate" cycle until preset termination conditions (i.e., "what success looks like") are met. This is highly similar to policy optimization in reinforcement learning: the agent evaluates the gap between the current state and the goal state after each iteration, adjusting its next action accordingly. In engineering practice, this pattern is widely applied in automated testing, CI/CD (Continuous Integration/Continuous Deployment) pipelines, and complex multi-step data processing tasks. Codex's Loop mode brings this engineering concept to the natural language interaction layer, enabling non-technical users to define and drive complex automated workflows.
The common thread across these techniques: they don't treat Codex as a simple Q&A tool, but as an intelligent agent with autonomous judgment and continuous execution capabilities.
Implications for Regular Users: Redefining AI's Role
The biggest takeaway from this case is: The upper limit of an AI tool's value depends on how you define its role.
Most people still use AI in a "question and answer" fashion, but this employee's approach lets AI proactively audit your behavior patterns and tell you which work can be optimized. This "meta-level" usage mindset is the real key to unlocking AI productivity.
If you're also using Codex, try this approach: instead of manually submitting requests each time, first let AI understand the full picture of your work, then have it propose optimization suggestions. Behind those 35 lines of prompts lies an entirely new paradigm of human-AI collaboration.
Key Takeaways
- An OpenAI employee used 35 lines of prompts to have Codex automatically analyze 30 days of historical data, identify repetitive work, and package it into reusable automated Skills
- Codex intelligently judges whether tasks are worth automating, requiring conditions like repeated occurrence and process stability before execution
- Combined with screen reading and long-term memory, Codex can capture users' repetitive behavior patterns beyond the chat interface
- The approach isn't limited to programmers — operations, planning, writing, and other roles can all benefit
- The core insight is transforming AI from a passive Q&A tool into an intelligent agent that proactively audits work habits
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.