A Practical Guide to Loop Engineering: Pain Points and Solutions in Automated AI Coding Workflows
A practical guide to Loop Engineering's pain points and Harness workflow solutions for AI coding automation.
Loop Engineering lets AI coding agents autonomously execute tasks through loop systems, but faces three critical challenges: reliability degradation in long chains, skyrocketing Token costs, and context window bloat. This guide explores how Harness workflows built on Archon solve these issues through deterministic process control, mixed model strategies, independent sessions, persistent storage, observability dashboards, and Human in the Loop mechanisms.
What Is Loop Engineering?
A new concept is rapidly gaining traction in the AI coding community — Loop Engineering. OpenCloud author Peter Steinberger and Claude Code lead Boris Cherney have both been actively promoting this idea. Boris even stated bluntly: "I no longer write Prompts for Claude — I write Loops, and let the Loops do the work."
In simple terms, the core idea behind Loop Engineering is: instead of manually writing each Prompt, you design a loop system that lets AI coding assistants autonomously and continuously complete tasks. The developer's role shifts from "the person writing instructions" to "the person designing loops."
The rise of this concept is closely tied to the evolution of AI coding assistants from single-turn conversations to multi-turn autonomous execution. Early AI coding tools (like GitHub Copilot) primarily handled code completion, with developers still guiding the process line by line. With the emergence of agentic coding tools like Claude Code, Cursor, and Windsurf, AI began to understand project context and execute multi-step operations. Loop Engineering was born in this context — it aims to upgrade AI coding assistants from "passive responders" to "active executors," using loop mechanisms to drive continuous, autonomous task progression.
In Claude Code, this system is built on several key features:
- slash loop: Sets a run interval for Prompts — for example, checking a GitHub repo for new Issues every 5 minutes and automatically handling them
- slash go: Defines completion criteria, letting the Coding Agent keep working until the criteria are met
- slash routines: Scheduled tasks — for example, waking up once an hour to read a Spec document and process the next task
Loop Engineering essentially combines these capabilities into a system that lets AI coding assistants take over larger scopes of work and push forward autonomously, step by step.
Core Architecture of Loop Engineering: Orchestrator + Workers
The core architecture of Loop Engineering centers on a master Orchestrator Agent. Developers only need to describe the goal at a high level, and the Orchestrator builds the loop system itself, breaks down tasks, and executes them round by round.
The Orchestrator-Workers pattern is a classic distributed systems architecture widely adopted in the AI Agent domain. The Orchestrator handles task decomposition, scheduling, and state management, while Workers handle concrete execution. This pattern is listed as one of the recommended multi-Agent collaboration patterns in Anthropic's Building Effective Agents guide. Similar patterns include MapReduce and Pipeline, but the Orchestrator pattern's advantage lies in its ability to dynamically adjust task allocation strategies, making it better suited for coding tasks with uncertain complexity.
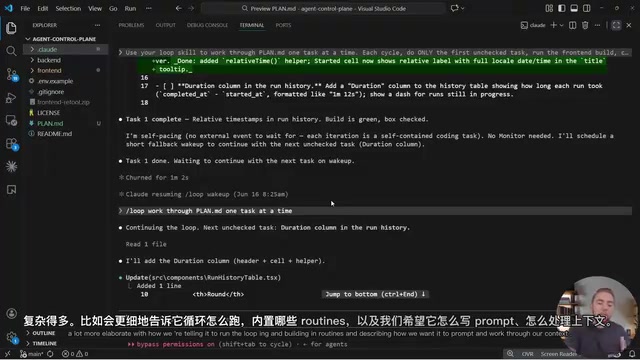
Using Claude Code as an example, you simply tell it to "use Loop Skill" and pass in a Spec document containing a task list. It will then:
- Load Loop Skills and understand how to schedule
- Process the first incomplete task in each round
- Verify completion, then move to the next round
- Repeat until all tasks are done
Interestingly, the Prompts within the loop are entirely generated by the AI itself, not hand-written by developers. For instance, it might automatically produce scheduling instructions like "slash loop to process one task from PlanMD per iteration." Boris's actual system incorporates more granular routines and context-handling strategies, but the underlying logic is exactly this.
Three Major Pain Points of Loop Engineering
Loop Engineering is no silver bullet. In practice, three core issues deserve attention:
Pain Point 1: Reliability Is Hard to Guarantee
Boris claims he sometimes manages thousands of AI Agents simultaneously. But is this realistic? The reality is that Loop Engineering works well for Proof of Concept or rapid idea exploration, but isn't suitable for driving all AI coding work. Many teams set up the system and let it run unsupervised, only to return a day later and find the output quality is poor. The core contradiction here is: while current LLMs have very high single-step accuracy (exceeding 90% on certain benchmarks), errors accumulate exponentially in multi-step loop scenarios — if each step has 95% accuracy, after 20 loop iterations the overall accuracy drops to roughly 36%. This is why purely relying on autonomous AI loops tends to spiral out of control in long-chain tasks.
Pain Point 2: Token Costs Skyrocket
The Orchestrator needs to understand the Spec, determine how many Workers to launch, and decide how many rounds to loop — each step consuming massive amounts of Tokens. For a relatively simple application, the Orchestrator alone consumed over one million Tokens across all its loop iterations. The overhead from extensive context passing and reasoning is virtually unavoidable.
To understand what this number means: Tokens are the basic unit of measurement for LLM text processing. One English word typically corresponds to 1-2 Tokens, and one Chinese character typically corresponds to 1-2 Tokens. Current mainstream models like Claude 3.5 Sonnet have a context window of 200K Tokens, while GPT-4o has 128K Tokens. In Loop Engineering, each iteration requires feeding task descriptions, code context, and decision history into the model, and this information accumulates rapidly. Using Claude's API as an example, input Tokens cost approximately $3 per million and output approximately $15 per million — one million Tokens translates to tens of dollars in direct costs, and that's just for a single Orchestrator.
Pain Point 3: Context Window Bloat
Many loop configurations are essentially running loops within the same Coding Agent session. As runtime extends, the LLM's context fills up until it eventually overwhelms the model. When context approaches the window limit, the model's attention mechanism exhibits the "Lost in the Middle" phenomenon — where the model's attention to information in the middle of the context drops significantly, leading to missed critical information or contradictory outputs. The real solution requires distributing work across separate, independent coding sessions that can communicate with each other.
The Solution: Making Loops Controllable with Harness Workflows
To address these issues, a Harness (workflow framework) solution based on Archon has emerged. The core idea is to take decision-making power back from the AI and only invoke the LLM's reasoning capabilities when truly needed.
Archon is an open-source workflow framework designed specifically for AI Agent orchestration. Its core philosophy is combining deterministic process control with AI reasoning capabilities. Unlike Agent frameworks such as LangGraph and CrewAI, Archon emphasizes "engineering controllability" — developers can precisely define each node's behavior, model selection, and failure-handling strategy. This design philosophy draws from traditional software engineering workflow engines (like Airflow and Temporal) but is adapted for the unique needs of AI Agents, particularly in session isolation, model routing, and human-machine collaboration.
Deterministic Workflows Replace Pure AI Scheduling
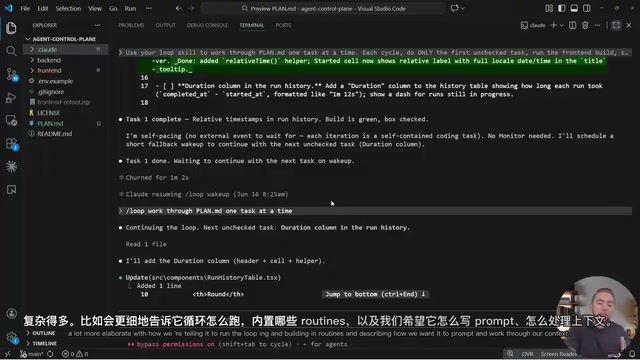
Unlike pure Loop Engineering, Archon workflows are pre-designed deterministic processes. Taking a GitHub Issue fix as an example, the workflow includes:
- Extract Issue number and context
- Use an LLM to classify (bug fix or new feature)
- Route to different paths based on classification
- Investigate Issue → Implement → Verify → Create PR
Each step runs in an independent Coding Agent session, avoiding context bloat. Workflow progression is controlled by the workflow engine, not left entirely to AI judgment. The key advantage of this design is that deterministic nodes (such as conditional branches, loop control, and error handling) consume zero Tokens — only nodes that genuinely require AI reasoning invoke the LLM, dramatically reducing costs and uncertainty while maintaining flexibility.
Mixed Model Strategy to Compress Costs
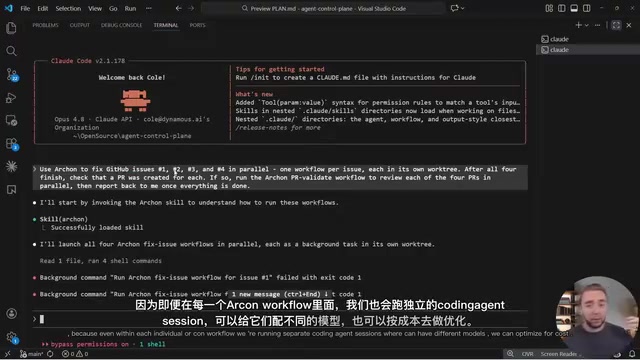
Each node in the workflow can independently select its model, allocating compute on demand:
- Classification steps: Use lightweight models (Haiku, Kimi K2.7)
- Implementation phase: Use Claude Code
- Code review: Use Codex
- Context exploration: Use even smaller models
This directly solves the cost problem caused by "using the same expensive model for every step." Mixed model strategy (Model Routing) is one of the core techniques for AI application cost optimization today. Different models vary by orders of magnitude in both capability and price: Claude 3.5 Haiku costs roughly 1/10 of Sonnet, and open-source models like Kimi K2.7 have even lower API costs. The key insight is that not all tasks require the most powerful model — simple tasks like classification and summarization can be handled by lightweight models, while only complex code generation and architectural decisions need top-tier models. Model routing services like OpenRouter are also driving this trend, allowing developers to dynamically switch models based on task complexity.
Human in the Loop for Quality Assurance
Any node in the workflow can include a human confirmation step — pause, review, then continue. This is precisely what pure Loop Engineering lacks most: a mechanism for humans to intervene at critical junctures.
Human in the Loop (HITL) is an important principle in AI system design, referring to the ability to retain human review and intervention at critical decision points in automated processes. In AI coding scenarios, HITL is especially important because code errors have cascading effects — an early architectural decision error can require all subsequent implementations to be scrapped and redone. HITL implementation approaches include synchronous approval (the process pauses waiting for human confirmation) and asynchronous review (AI continues executing but flags nodes requiring human review). Research shows that adding human review at critical nodes can reduce AI coding error rates by over 60%, making HITL a crucial bridge from prototype exploration to production-grade applications.
Persistent Storage and Recoverability
All logs and run records are stored in a Neon (Postgres) database. Even if a machine crashes or a task is cancelled midway, execution can resume from the interrupted step. State no longer depends on a particular Coding Agent's session memory.
Neon is a serverless database service built on PostgreSQL, supporting auto-scaling and branch management. In AI workflow scenarios, persistent storage solves the core problem of "state externalization" — moving task state, decision history, and intermediate results that originally lived in an AI Agent's session memory to an external database. This way, even if an individual Agent session crashes or times out, the entire workflow's state remains intact and recoverable. This design borrows from the Saga pattern and Event Sourcing pattern in microservices architecture, ensuring fault tolerance for long-running distributed tasks. For large coding tasks that need to run for hours or even days, this recoverability is indispensable infrastructure.
In Practice: An Observability Dashboard
To address observability challenges in Loop Engineering, the community has open-sourced a Dashboard specifically designed for Loop Engineering.
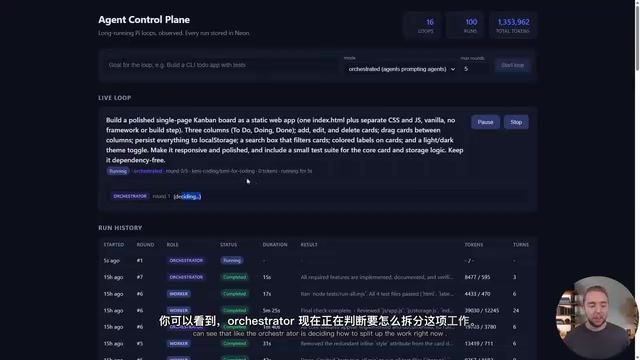
Observability is a concept borrowed from the DevOps domain, originally popularized by distributed system tracing tools (like Jaeger and Zipkin). In AI Agent scenarios, observability faces unique challenges: beyond tracking traditional metrics like latency and error rates, it also needs to record the reasoning process, Token consumption, and decision rationale at each step. This is critical for debugging anomalous AI Agent behavior — when a loop produces incorrect results, developers need to trace back to exactly which round and which decision node went wrong.
The Dashboard's core capabilities include:
- Fully API-driven: Uses your own API keys (e.g., Kimi K2.7), not dependent on a single expensive model
- Run history tracking: Every loop iteration's decisions, Worker dispatches, and Token consumption are traceable
- Cost monitoring: Built-in Cost Tracking clearly displays the expense of each run
- Human in the Loop: Before the Orchestrator proceeds to the next round, humans can review the previous round's results
Using a "build a single-page Kanban Web App" task as an example, the Orchestrator's initial planning plus writing prompts for three Workers consumed only about 6,000 Tokens — a dramatic cost improvement compared to pure Claude Code loops. This number means less than one cent was needed to complete task planning and distribution, whereas in pure Loop Engineering mode, the same planning phase might consume tens or even hundreds of thousands of Tokens.
Conclusion: From Loop Engineering to Harness Engineering
The final takeaway is: rather than calling it Loop Engineering, we should call it Harness Engineering. The concept behind Loop Engineering has value — making Coding Agents more autonomous and capable of handling larger scopes of work. But the prerequisite is having a proper system to harness it:
- Deterministic processes control task progression, rather than relying entirely on AI decisions
- Mixed model strategies control Token costs
- Independent sessions prevent context window bloat
- Persistent storage ensures recoverability
- Observability Dashboards let you see what's happening at every step
- Human in the Loop preserves human judgment at critical nodes
This evolutionary path is strikingly similar to the history of software engineering. Early CI/CD also went through a transition from "full automation" to "controlled automation" — Jenkins was initially designed as a fully automated build pipeline, but teams quickly discovered in practice that they needed manual Approval Gates at critical junctures. Similarly, AI coding automation is moving from "letting AI take full control" toward "controllable human-machine collaborative processes."
Loop Engineering doesn't need a new buzzword, but the engineering practices behind it — how to design, monitor, and optimize automated AI coding workflows — are genuinely worth deep study for every AI developer. As model capabilities continue to improve and toolchains mature, developers who master this methodology will hold a significant advantage in the new era of AI-assisted programming.
Related articles

ChatGPT Schedule Planning Feature Explained: How AI Helps Teams Organize Work Efficiently
A deep dive into ChatGPT's schedule planning feature: coordinate team schedules and assign tasks through natural language. Learn AI planning strategies and practical tips to boost collaboration.

Vibe Coding in Practice: Three Strategies for Building an English Learning Game with Dramatically Different Results
Three controlled experiments compare pure Prompt, pre-prepared assets, and Godot engine strategies for Vibe Coding an English learning game — revealing dramatic differences in quality and Token cost.
Build an App in 30 Minutes with Zero Code: A Complete Hands-On Walkthrough Using the AI Tool Tusi
Build a fully installable mobile app in 30 minutes with zero code using AI tool Tusi. A complete walkthrough from requirements to finished product, showing how AI shifts app development from coding skills to clear communication.