A Three-Month Roadmap to LLM Development: A Deep Dive into the Learning Path from Zero to Freelancing

A realistic breakdown of the three-month path from zero to freelancing in LLM application development.
This article dissects a popular three-step learning path for LLM development: prompt engineering and API calls, RAG knowledge base construction and optimization, and AI Agent development with multi-agent collaboration. It provides in-depth technical explanations of each stage while offering realistic expectations—three months works for developers with Python experience, while complete beginners should plan for six months.
A recent video on Bilibili about a learning path for large language models sparked quite a bit of discussion, claiming that with three months and two hours a day, you can start making money with AI LLMs. Is this realistic? Setting aside the marketing hype, let's seriously break down the learning path it presents—examining which recommendations are worth following and which deserve a question mark.
The AI Agent Job Market: The Real Bar Behind High Salaries
The video mentions a key data point: searching for "AI Agent" on recruitment apps shows salary ranges jumping straight from 18K to 45K RMB, with freelance intelligent agent projects starting at five-figure quotes.

This data isn't exaggerated. Since the second half of 2024, AI Agent-related positions have indeed experienced explosive growth. Enterprise demand for talent who can deliver production-ready Agent solutions far exceeds supply, and there's a massive skill gap between "can use ChatGPT" and "can develop Agent systems."
It's worth explaining what AI Agents actually are. An AI Agent is an AI system capable of autonomously perceiving its environment, formulating plans, and executing actions to accomplish specific goals. Unlike traditional chatbots, Agents possess autonomous decision-making capabilities—they can decompose complex tasks into multiple sub-steps, invoke external tools to gather information, and dynamically adjust strategies based on intermediate results. 2024 has been dubbed the "Year of the Agent" by the industry, with leading companies like OpenAI, Google, and Anthropic all making Agent capabilities a core product direction. The explosion in enterprise demand stems from a straightforward logic: purely conversational AI can only answer questions, while Agents can actually replace humans in completing workflows—such as automated data analysis, customer follow-ups, and document reviews—delivering directly quantifiable cost reduction and efficiency gains.
However, we need to be realistic: 45K salaries typically correspond to mid-to-senior developers with solid engineering backgrounds, not beginners who completed a three-month crash course. The real market opportunity lies in this: many small and medium-sized businesses need AI implementation solutions but can't afford big-tech-level engineers, creating space for freelancers and side-hustlers with the right skills.

Deep Dive into the Three-Step Learning Path
The three-step learning method presented in the video is structurally sound, but each step needs more detail.
Step One: Building the Foundation — Prompt Engineering & API Calls
The video suggests "first get good at writing prompts and roughly understand API principles," then build a viral copywriting generator as practice.
The core logic of this advice is correct: don't jump straight into model training. For most application developers, you don't need to understand every attention layer in a Transformer, but you must master the following:
- Prompt Engineering: System prompt design, few-shot example construction, Chain of Thought (CoT) guidance
- API Calls: Understanding the request structure, token calculation, and streaming output of OpenAI/domestic LLM APIs
- Basic Python Skills: At minimum, being able to write scripts, call APIs, and process JSON data
Prompt engineering is far more than just "writing good questions"—it's a systematic methodology for interacting with large models. The System Prompt defines the AI's role, behavioral boundaries, and output format, serving as the "soul" of the entire application. Few-shot examples leverage the model's In-Context Learning capability by providing a small number of input-output samples in the prompt, helping the model quickly understand the task pattern. Chain of Thought (CoT) improves reasoning accuracy by guiding the model to "think step by step"—research shows that simply adding "Let's think step by step" to a prompt can significantly improve performance on math and logic tasks. Additionally, there are advanced techniques like Self-Consistency and Tree of Thoughts, which together form a toolbox for dramatically improving output quality without training the model.
Regarding API calls, the token mechanism is a core concept you must understand. A token is the basic unit by which LLMs process text—roughly understood as a "word fragment." In English, one token corresponds to approximately 4 characters or 0.75 words; in Chinese, one character typically maps to 1-2 tokens. Understanding the token mechanism is crucial because API calls are billed by token count, with input and output priced separately. Taking GPT-4o as an example, one million input tokens costs $2.50, while output costs $10. Streaming refers to the API returning results token by token rather than waiting for complete generation before responding all at once—this significantly improves user experience as users see text appearing gradually, dramatically reducing perceived wait time. In actual development, properly controlling context length, using caching mechanisms, and selecting appropriate model tiers are all key strategies for managing API costs.
Building a copywriting generator is indeed a solid beginner project—it helps you quickly understand the complete "input-process-output" pipeline. But to earn money from it, you also need some product thinking—clients want results, not technology.
Step Two: Learning to Deliver — RAG Knowledge Base Construction & Optimization
This step has the highest value in the entire learning path.

RAG (Retrieval-Augmented Generation) is currently the most mainstream technical approach for deploying LLM applications. To understand why RAG matters, you need to first understand the core problem it solves. Proposed by Meta in 2020, RAG's core idea is: rather than relying on the model to memorize all knowledge, retrieve relevant information from an external knowledge base before generating an answer, injecting the retrieved results as context into the prompt. This solves two fundamental problems with LLMs—outdated information due to knowledge cutoff dates, and model "hallucinations" (fabricating non-existent facts). The typical technical pipeline is: document preprocessing → text chunking → vectorization (embedding) → storage in a vector database → semantic retrieval when users ask questions → feeding retrieved results along with the question into the LLM to generate answers. Vector databases (such as Milvus, Chroma) convert text into high-dimensional vectors and calculate cosine similarity to achieve semantic-level retrieval, which is far more intelligent than traditional keyword matching.
The key skills mentioned in the video are all practical:
- Data Cleaning: Enterprise data is often messy—PDFs, Word documents, and web content need structured processing
- Vector Databases: Selection and usage of tools like Milvus, Chroma, Pinecone
- Knowledge Graph Basics: Understanding how entity relationships enhance retrieval effectiveness
Building a "knowledge base Q&A assistant" is an excellent hands-on project. Feeding industry reports and company manuals to AI so it can accurately answer professional questions—this is precisely the scenario enterprises are most willing to pay for. Many SMBs' customer service, internal knowledge management, and compliance queries can all be solved with this approach.
What needs to be added is that the difficulty of RAG isn't in building it, but in optimizing performance. Retrieval recall rate, answer accuracy, and hallucination control—these are what separate beginners from experts. During your learning process, focus especially on:
- Chunking Strategy Selection: Chunking strategy directly impacts retrieval quality. Common methods include fixed-size chunking, semantic paragraph chunking, and recursive character splitting. Different document types suit different strategies—technical documentation works well with section-based chunking, while conversation logs suit turn-based chunking.
- Hybrid Retrieval (Keyword + Vector) Implementation: Hybrid retrieval combines the strengths of traditional BM25 keyword retrieval and vector semantic retrieval. The former excels at exact matching of proper nouns, while the latter excels at understanding semantic similarity—their complementary nature significantly improves retrieval effectiveness.
- Introducing Rerank Models: Rerank (re-ranking) models perform fine-grained sorting of candidate results after initial retrieval. Commonly used ones include Cohere Rerank and bge-reranker, which can significantly improve the quality of context ultimately fed to the LLM.
- Establishing an Evaluation Framework: Industry-standard metrics include retrieval Recall, answer Faithfulness, and answer Relevance. The open-source framework RAGAS provides automated evaluation solutions, and establishing a systematic evaluation process is the foundation for continuous optimization.
Step Three: Real Combat — Agent Development & Multi-Agent Collaboration

The video mentions ReAct patterns, tool calling, and multi-Agent collaboration—these are indeed the core concepts in current Agent development.
ReAct (Reasoning + Acting) enables AI to execute tasks through a "think-act-observe" loop rather than giving one-shot answers. Proposed by Google and Princeton University in 2022, this pattern is the theoretical cornerstone of current Agent architectures. It simulates how humans solve problems: first think (Thought) about the current situation and next steps, then execute an action (Action), then observe (Observation) the results—cycling until the task is complete. Combined with Function Calling, AI can autonomously invoke external tools like search engines, database queries, and code execution. Function Calling is a capability introduced by OpenAI in 2023 that allows LLMs to output function call requests in structured JSON format rather than natural language. Developers pre-define available tool functions, and the model autonomously determines which function to call and what parameters to pass based on user intent. This mechanism upgrades LLMs from "can only talk" to "can take action," forming the technical foundation for Agents to interact with the real world.
For tech stack selection, LangChain is currently the most popular framework, but it's also recommended to explore:
- LangGraph: Better suited for complex multi-step Agent workflows. While LangChain is the most mainstream LLM application development framework, offering core abstractions like Chains, Agents, and Memory, its linear chain structure struggles with branches, loops, parallelism, and other complex workflows as application complexity increases. LangGraph uses directed graph-based orchestration, supporting state management and conditional branching, making it more suitable for production-grade applications.
- CrewAI: A lightweight framework for multi-Agent collaboration. It borrows the "team collaboration" metaphor, allowing multiple Agents with different roles and skills to cooperatively complete complex tasks—for example, one Agent handles research, another handles writing, and another handles review.
- Dify/Coze: Low-code Agent building platforms suitable for quickly validating ideas. Dify is an open-source LLMOps platform, and Coze is a ByteDance product. Both allow building Agent applications through visual drag-and-drop, suitable for non-technical users to quickly validate business ideas, and also for developers to prototype before converting to code implementations.
After completing this step, you'll indeed have the foundational ability to provide AI solutions for enterprises. But "building a chatbot" is just the starting point—what truly has commercial value is an Agent system that solves specific industry pain points.
Is Three Months Enough? A More Realistic Learning Expectation
Returning to the original question: is three months at two hours a day enough?
If you have a programming background (at least familiar with Python), three months can indeed get you through all three steps above, reaching a level where you can handle simple projects. But there's still a gap between "able to take on freelance work" and "completed the basics"—you'll need:
- At least 2-3 complete project implementations under your belt
- Some understanding of a specific vertical industry (education, finance, e-commerce, etc.)
- Basic project communication and delivery skills
If you're starting from absolute zero, I'd suggest extending the timeline to 6 months, spending the first two months building Python fundamentals.
Overall, the direction of this learning path is correct: Prompt Engineering → RAG Applications → Agent Development. This is a market-validated skill progression. The key lies in execution—don't just bookmark and watch. For every concept you learn, write code and build projects. In the AI era, the density of your practice determines the speed of your growth.
Related articles
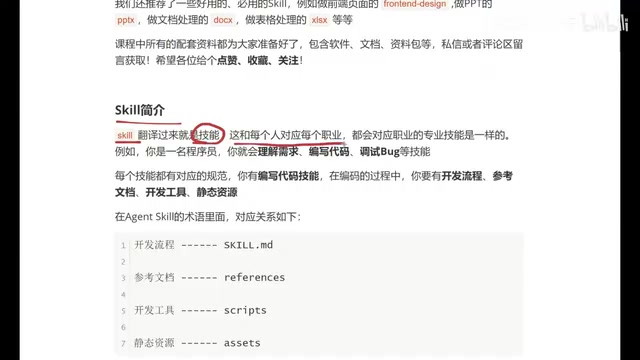
Beginner's Guide to Agent Skills: Structure Breakdown & Custom AI Skill Development
A deep dive into Agent Skill's core concepts and internal structure, covering skill.md, references, scripts, and assets with a restaurant poster Skill example.
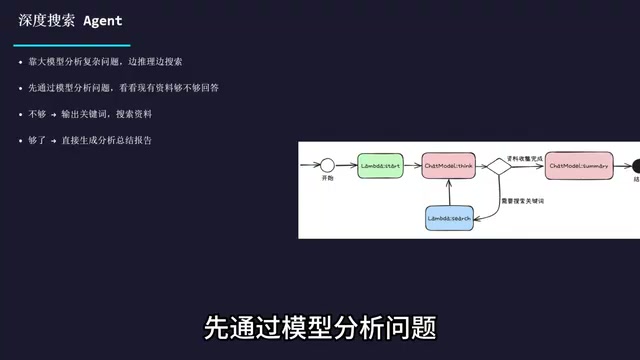
Complete Guide to Commercial AI Agent Development: From Requirements Analysis to Production Deployment
Complete guide to commercial AI agent development from scratch, covering requirements analysis, architecture design (ReAct framework, deep search, intent recognition), hands-on Coze platform implementation, workflow creation, and production deployment.
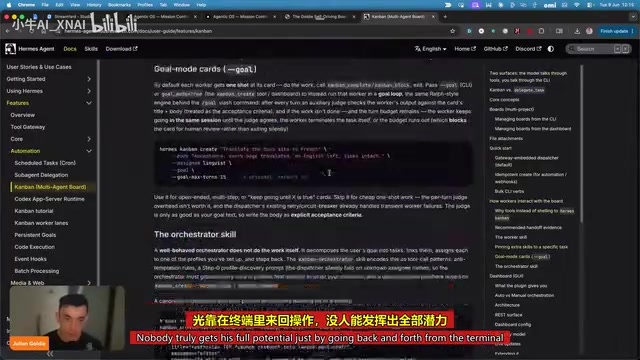
Hermes AI Kanban: A Five-Layer Autonomous Architecture for Fully Automated Delivery from Idea to Finished Product
Deep dive into Hermes Kanban 2.0's five-layer autonomous architecture covering intelligent planning, human approval gates, multi-agent execution, and Obsidian integration for fully automated delivery.