Agent Harness: A New AI Agent Paradigm from Prompt Engineering to Execution Environment Orchestration
Agent Harness Engineering adds loop-based orchestration atop context engineering to overcome AI agent limitations.
Agent Harness Engineering represents the next evolution beyond Prompt and Context Engineering for AI agents. By introducing execution loops with fresh context isolation for each task, it solves the critical problem of information loss from context summarization in long-running tasks. This orchestration layer decomposes complex work into atomic tasks, executes them in clean contexts, and iterates until completion—enabling modern coding agents like Cursor to handle large-scale development autonomously.
From Prompt Engineering to Context Engineering, and now to Harness Engineering, the engineering paradigm of AI agents is undergoing a profound evolution. What exactly does this formally named concept mean? And how does it fundamentally differ from the prompt engineering and context engineering we're already familiar with?
The Evolutionary Path Starting from 4000 Tokens
The story begins with the release of ChatGPT in 2022. Back then, we were dealing with a context window of only 4000 tokens—an extremely limited "memory space" that severely constrained AI agent capabilities.
To understand how restrictive this limitation was, you first need to understand the concept of tokens. Tokens are the basic units that large language models use to process text. An English word is typically split into 1-3 tokens, while a Chinese character usually corresponds to 1-2 tokens. A 4096-token context window is roughly equivalent to 3,000 English words or 2,000 Chinese characters—just enough to hold a medium-length article. The context window is essentially the total amount of information a model can "see" and "remember" during a single inference pass, including system prompts, user inputs, conversation history, and model outputs. By 2025, mainstream models have expanded their context windows to 128K or even million-level tokens, but window expansion hasn't linearly improved task completion quality, because models suffer from attention degradation known as "Lost in the Middle" in ultra-long contexts.
Under these constraints, simple Prompt Engineering was far from sufficient, and a core question emerged: How do you do more with fewer resources?
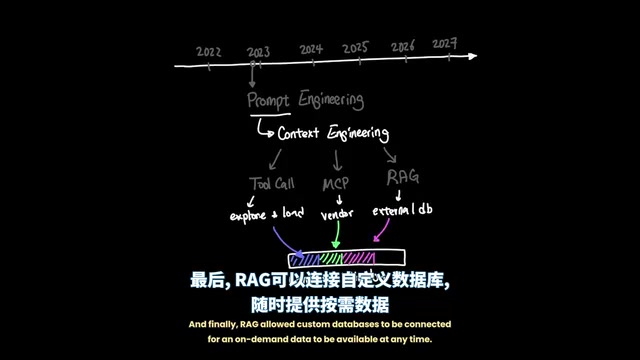
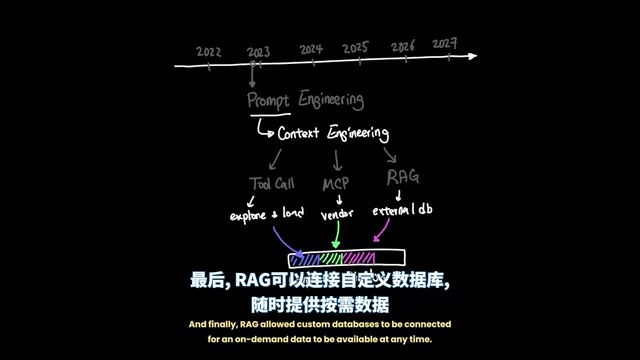
This gave rise to Context Engineering. Through Tool Calling, MCP protocol, and RAG (Retrieval-Augmented Generation), developers found more efficient ways to manage the context window:
- Tool Calling: Enables agents to explore code repositories, read only specific files relevant to the current task, and create operations externally. The core mechanism of Tool Calling allows the model to identify during inference when it needs to invoke external tools (such as code executors, search engines, database queries), generate structured invocation requests that are executed by the runtime environment, and return results to the model—thereby breaking through the boundaries of the model's own capabilities.
- MCP: Allows adding vendor-specific capabilities on top of the model. MCP (Model Context Protocol) is an open standard introduced by Anthropic in late 2024, designed to establish a unified communication protocol between AI models and external data sources/tools. Similar to a USB-C port for AI, it enables tools and services from different vendors to connect to any compatible AI model in a standardized way.
- RAG: Connects custom databases to the system, making on-demand data readily available. RAG (Retrieval-Augmented Generation) was proposed by Meta in 2020. Its core idea is to retrieve relevant document fragments from an external knowledge base before the model generates an answer, injecting them into the context as reference material, thereby compensating for the model's training data limitations in timeliness and domain expertise.
Coding agents like Cursor, Windsurf, Kline, Roo, and Aider were early players in this phase, employing tool calling to implement context engineering and accomplishing quite a bit of work. These tools represent different approaches in the current AI coding agent landscape: Cursor and Windsurf are standalone IDE forks based on VS Code that deeply integrate AI capabilities into the editor experience; Kline (formerly Cline) and Roo are VS Code plugins driven by open-source communities with rapid iteration; and Aider is a command-line tool targeting developers who prefer terminal operations.
Why Context Engineering Hit a Ceiling
As underlying models evolved and context windows grew larger, coding agents began handling longer-running tasks. People started asking these agents to complete increasingly broad feature development and bug fixes. However, even context engineering has its clear limits.
Take a large task like "clone a complete website" as an example: simple prompt engineering can only produce a rough one-shot result; context engineering is somewhat better, but the results are still unsatisfying—the website might only be half-finished, some buttons don't work, and features haven't been adequately tested.
The root of the problem lies in the context summarization mechanism. When a task takes 12 hours to complete, as the context window gradually fills up, the agent compresses context through summarization to continue working. This means the agent's capability is bounded by the quality of its own summaries.
Context Summarization is a mechanism where the system automatically compresses earlier content into brief summaries when the accumulated token count during a conversation or task execution approaches the context window limit. This process is typically performed by the model itself—the system sends existing conversation history to the model and asks it to generate a condensed version that retains key information. However, summarization is inherently lossy compression: each compression inevitably loses details. In scenarios with multiple stacked summaries (summarizing summaries), information loss grows exponentially. More critically, the model lacks the ability to predict "which information will be crucial in future steps" when generating summaries, potentially marking incomplete subtask states as finished or omitting critical constraints and dependencies.
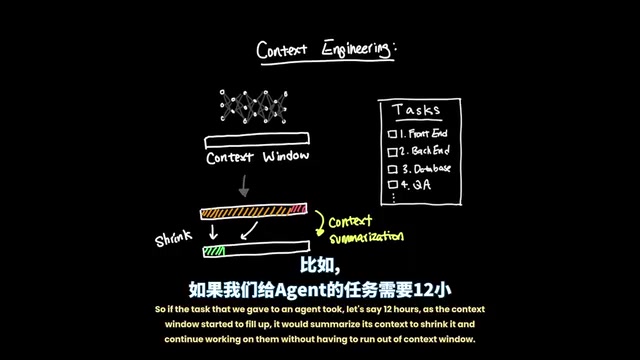
Worse still, when context is summarized mid-task, the agent may incorrectly believe certain tasks are already complete, or oversimplify tasks by assuming certain features have been verified. This is why we frequently see AI agents completing only half their tasks, or not even attempting certain parts at all.
This elastic, self-managed context window approach, while superficially granting agents the ability to handle long-running tasks, delivers results far below expectations in practice.
The Core Philosophy of Harness Engineering: Loops and Isolation
While context engineering was hitting its ceiling, developers were already experimenting with various solutions—hierarchical context management with sub-agents, multi-agent Swarms, and more.
The concept of multi-agent Swarms originates from distributed systems and swarm intelligence theory. In the AI agent domain, Swarms refer to architectural patterns where multiple independent agents collaborate to complete complex tasks. Early multi-agent frameworks like AutoGen (Microsoft), CrewAI, and LangGraph explored different collaboration paradigms: some adopted hierarchical structures (one master agent assigns tasks to sub-agents), some used peer collaboration (agents discuss as equals to reach consensus), and others employed pipeline patterns (tasks pass sequentially between agents). These explorations revealed a core challenge: how to balance context sharing and isolation between agents. Too much sharing leads to context pollution and token waste; too much isolation leads to information gaps and redundant work.
All these explorations were converging in the same direction: better orchestration and management of underlying agents.
The formal introduction of the Agent Harness concept marks a new phase in AI agent engineering. While some may consider it just a buzzword, it genuinely captures the essence of the transformation happening in the AI industry.
The most critical innovation of Harness Engineering is the introduction of Loops. It adds an orchestration layer on top of context engineering, placing agents in a loop environment:
- Generate a requirements document: First create a detailed Product Requirements Document (PRD), structured as a JSON file. In traditional software engineering, a PRD is the core document product managers use to define product features, user stories, and acceptance criteria. In Harness Engineering, the PRD takes on a new role—it's not just a human-readable requirements description, but a machine-parseable task graph. Structuring the PRD as JSON means every feature point is decomposed into atomic tasks with clear inputs, outputs, dependencies, and acceptance conditions.
- Task decomposition and loop execution: Select only one task at a time from the document to complete. This approach borrows the classic "Divide and Conquer" strategy from software engineering, and aligns with the agile development philosophy of breaking Epics into User Stories and then into Tasks. The key difference is that this task decomposition isn't designed for human developers—it's tailored to the cognitive characteristics of AI agents, with each task granular enough to be completed within a clean context window.
- Fresh context: Give the agent fresh prompts and context for each iteration
- Test and document: Test and document each step
- Continue iterating: The loop continues until all tasks are complete
The elegance of this architecture lies in the fact that agents no longer need to struggle within a constantly expanding and compressing context. Instead, they have a clean, focused working environment in each iteration, while following strict start and completion rules.
Practical Cases: From Ralph to Modern Coding Agents
Ralph is one of the most representative practical cases of Harness Engineering, generating widespread attention on the internet—not only because of its excellent results, but because its underlying architecture is extremely concise. Its workflow perfectly embodies the core Harness philosophy: first create a PRD, then loop through implementing features one by one until completion.
Similarly, Anthropic has provided concise Harness demonstrations—lightweight, simple environment designs. When you look at these projects' code repositories, you'll be surprised that such powerful architecture is built on such minimal code.
It's particularly important to emphasize that Harness Engineering does not obsolete previous engineering paradigms. If you dig into the internals of open-source coding agents like Kline, you'll find their system prompts are still driven by carefully crafted prompts. The relationship between the three is progressive and layered:
- Prompt Engineering (bottom layer): Defines the agent's identity and role
- Context Engineering (middle layer): Manages context and tool calling
- Harness Engineering (top layer): Orchestrates the entire execution environment and loop process
This layered relationship is similar to the protocol stack in computer networking—each layer depends on capabilities provided by the layer below while providing higher-level abstractions to the layer above. Prompt Engineering is like defining the basic syntax of communication, Context Engineering manages information routing and retrieval, and Harness Engineering handles session management and process control for the entire system.
Harness Practices in Modern Coding Agents
Using Cursor as an example, we can see the concrete application of Harness thinking in modern tools. Developers can launch Cursor locally to handle tasks while concurrently fixing different features, with each agent having its own independent context.
Going further, through Cloud Agents, entire tasks can run in the cloud—tasks continue even after developers close Cursor, automatically creating Pull Requests upon completion. Combined with Slack integration, developers can even send feature requests via messages, with agents completing them automatically and sending notifications. The ultimate form is fully autonomous operation—setting automation rules that let agents check for new information daily and update autonomously.
In 2025, competition in this space has intensified further: GitHub Copilot launched Agent mode, Google released the Jules coding agent, and Amazon's CodeWhisperer is also evolving toward an agentic direction. The competitive focus has shifted from "whose code completion is more accurate" to "whose task orchestration is smarter"—this is precisely why Harness Engineering has become an industry hotspot.
This is the ultimate vision of Harness Engineering: not making individual agents smarter, but making the agent system as a whole more powerful through better environment design and process orchestration.
Summary and Outlook
Today, many coding agent companies have integrated the Harness layer directly within their applications, though implementations vary across companies. This also explains why so many companies have been discussing Agent Harness recently—because it genuinely delivers significant performance improvements.
Agent Harness represents not just a new term, but a paradigm shift in AI agent engineering from "optimizing single interactions" to "designing execution environments." The deeper logic behind this shift is that as AI models' foundational capabilities become increasingly homogeneous, the battlefield for differentiated competition is moving up from the model layer to the engineering layer. Just as competition in the cloud computing era shifted from hardware to orchestration (Kubernetes, Docker), competition in the AI agent era is shifting from model capabilities to agent orchestration.
For developers, understanding and mastering this paradigm will be a key capability for building the next generation of AI applications.
Related articles

DeepSeek Researcher Summarizes 10 Rules for Using AI Agents
A DeepSeek researcher shares 10 universal rules for using AI agents, covering the shift from execution to judgment, memory file systems, human-AI collaboration boundaries, and more.
DeepSeek V4 Flash Free Usage Guide: Configuration for Cherry Studio and CC Switch
DeepSeek V4 Flash is free for a limited time with zero token charges. Learn how to register on OpenModel and configure it in Cherry Studio and CC Switch.

1FlowBase in Practice: Adding Vision Tools to DeepSeek V4 for Multimodal Capabilities
Learn how to use 1FlowBase to mount MIMO 2.5 as a vision tool on DeepSeek V4, creating a Fusion multimodal endpoint with step-by-step orchestration guide.