DeepSeek V4 Flash Free Usage Guide: Configuration for Cherry Studio and CC Switch
Complete guide to using DeepSeek V4 Flash for free via OpenModel in Cherry Studio and CC Switch.
OpenModel is offering DeepSeek V4 Flash completely free with no token charges. This guide covers registration, API key creation, and step-by-step configuration in Cherry Studio (using Anthropic protocol) and CC Switch (with model mapping). The model supports 1M context, deep thinking, and tool calling, making it ideal as a backup for document processing and information retrieval tasks.
Introduction
The OpenModel platform recently launched an attractive promotion: DeepSeek V4 Flash is completely free to use, with zero charges for both input and output tokens, and no deductions from your account balance. For developers who regularly use AI coding tools, this means access to a high-quality backup model at zero cost. This article covers the details of this promotion and how to configure it in Cherry Studio and CC Switch.
Promotion Details and Model Features
Free Policy Overview
The OpenModel platform currently offers DeepSeek V4 Flash at no cost:
- Input tokens: Free
- Output tokens: Free
- Rate limits: 10 requests per minute (10 RPM), 100K tokens per minute (TPM)
- End date: Not officially specified; users will be notified when it ends
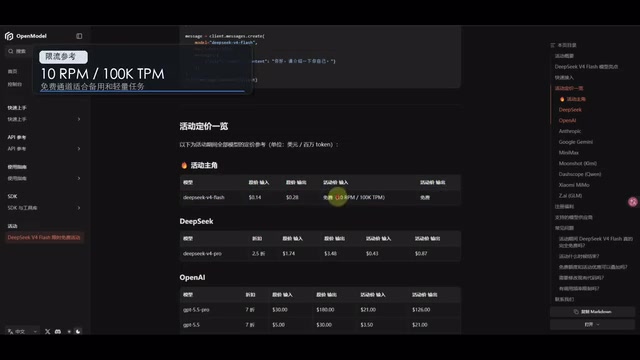
Overall, the 10 RPM and 100K TPM limits are reasonable and more than sufficient for personal daily use. Here's what these metrics mean: RPM (Requests Per Minute) limits the number of requests within a time window, regardless of how many tokens each request consumes; TPM (Tokens Per Minute) limits the total tokens processed per minute, including both input and output tokens combined. 10 RPM means you can make at most one request every 6 seconds, and 100K TPM means approximately 100,000 tokens can be processed per minute. For reference, OpenAI's free tier typically offers 3 RPM, and Anthropic's free tier is around 5 RPM, so OpenModel's 10 RPM is quite generous among free services. For non-real-time batch processing scenarios, developers can optimize throughput under rate limits using request queues and exponential backoff strategies. No top-up or card binding is required — just register and start using it.
Model Positioning: A Cost-Effective Backup Model
While DeepSeek V4 Flash doesn't match top-tier models like Claude Opus 4 or GPT-5.5 in core coding capabilities, it has several key advantages:
- 1M (one million) context window: Consistent with the DeepSeek V4 Pro series, capable of handling extremely long texts
- Deep thinking support: Equipped with chain-of-thought reasoning capabilities
- Tool calling support: Compatible with tools like MCP
Regarding the technical significance of the 1M context window: a context window refers to the maximum number of tokens a large language model can process in a single inference. A 1M (approximately 1 million) token context window represents the current industry pinnacle. For intuitive reference, 1M tokens is roughly equivalent to 7.5 million English words or about 50-70 average books; for Chinese, it's approximately 3-5 million characters. Achieving this capability typically relies on sparse attention mechanisms, RoPE positional encoding extrapolation, and hierarchical caching techniques. In practice, ultra-long context enables the model to analyze an entire code repository, complete technical documentation sets, or perform cross-file code refactoring in a single pass without splitting content across multiple conversations. However, it's worth noting that larger context windows generally increase inference latency and cost, and the model's information retrieval accuracy in the middle portions of very long texts (the "needle in a haystack" capability) may decrease.
Regarding the technical background of the DeepSeek V4 series: DeepSeek V4 is the next-generation large language model series released by DeepSeek in 2025. DeepSeek is known for architectural innovation — its predecessor DeepSeek V3 employed a Mixture of Experts (MoE) architecture with 671B total parameters but only activating approximately 37B parameters per inference, achieving a balance between performance and efficiency. The V4 series continues this technical approach with further optimizations. V4 Flash is positioned as a lightweight, high-efficiency fast inference version emphasizing response speed and cost-effectiveness, while V4 Pro targets complex tasks with higher performance. DeepSeek has also introduced important training innovations including Multi-head Latent Attention (MLA) and fine-grained expert allocation strategies in DeepSeekMoE, enabling superior performance under equivalent computational resources. The Flash version typically undergoes additional optimization through model distillation, quantization, or architectural streamlining to achieve faster inference speeds and lower deployment costs.
The recommended usage strategy is: Assign core coding tasks to your primary model (such as Claude Opus 4 or GPT-5.5), while delegating "miscellaneous work" like processing spreadsheets, organizing documents, and retrieving information to DeepSeek V4 Flash. This ensures quality for critical tasks while saving on API costs.
Important Limitation: Anthropic Protocol Only
Currently, DeepSeek V4 Flash on the OpenModel platform only supports the Anthropic (Claude Code) compatible SDK mode and does not support OpenAI's standard Chat Completions format. This means you must select the Anthropic protocol type during configuration, or the API calls will fail.
It's worth explaining the differences between these two mainstream API protocols. OpenAI's Chat Completions API uses the /v1/chat/completions endpoint, passing conversation history via a messages array with roles divided into system, user, and assistant. Anthropic's Messages API uses the /v1/messages endpoint, where the system prompt is passed as a separate top-level parameter, and supports a richer content blocks structure including text, image, tool_use, tool_result, and other types. Authentication also differs: OpenAI uses the Authorization: Bearer header, while Anthropic uses the x-api-key header. This protocol difference means client tools must explicitly select the corresponding protocol type for correct communication.
The API Base URL is: https://api.openmodel.ai/v1
Registration and API Key Setup
Step 1: Register an OpenModel Account
- Visit the OpenModel website
- Click "Quick Start" to enter the console
- Sign in with your Google account to complete registration
Step 2: Create an API Key
After logging into the console, navigate to the API key management page:
- Click "Create Key"
- Enter any name (other fields can be left blank)
- Click create to obtain your API Key
Make sure to save the generated Key — you'll need it for all subsequent configurations. In the console's usage statistics, you'll see request counts increasing while spending remains at zero.
Configuring in Cherry Studio
Add an Anthropic-Type Provider
- Open Cherry Studio and go to the settings page
- Click "Add Provider Type"
- Critical step: The type must be set to Anthropic model type (because OpenModel is compatible with Claude Code's API protocol)
Enter API Configuration
- API Request URL:
https://api.openmodel.ai/v1 - Key: Enter the API Key you created in the console
- Click "Fetch Model List" to pull all available models
Select the DeepSeek V4 Flash Model
Search for and select deepseek-v4-flash in the model list:
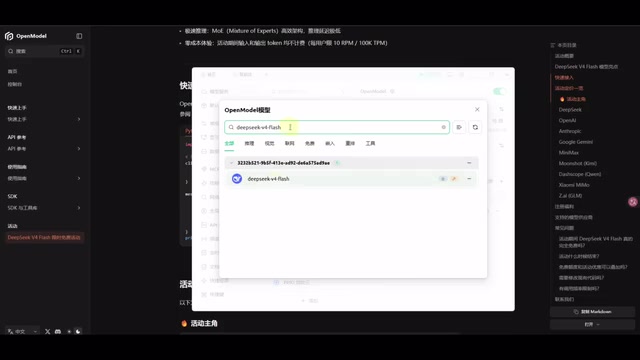
Once configured, return to the Cherry Studio home page and select OpenModel's DeepSeek V4 Flash model when starting a new chat. Testing confirms it supports thinking capabilities and tool calling (such as EXA's MCP web search), performing impressively as a backup model.
MCP (Model Context Protocol) mentioned here is an open standard protocol introduced by Anthropic in late 2024, designed to provide large language models with a unified way to connect to external tools and data sources. In the MCP architecture, AI applications act as MCP Clients, while various tools and services act as MCP Servers, communicating through standardized JSON-RPC protocol. MCP's core value lies in solving the M×N integration problem where every AI application previously needed custom integrations for each external service, simplifying it to an M+N standardized approach. The EXA MCP web search mentioned in this article is a typical MCP Server implementation that allows models to call EXA's search engine for real-time web information retrieval through a standard interface. The MCP ecosystem currently covers hundreds of tool services including file system operations, database queries, browser control, and code execution.
Configuring in CC Switch
If you regularly use Claude Code or Claude Desktop, you can configure this with one click using the CC Switch tool.
CC Switch is a community-developed Claude Code configuration management tool whose core function is enabling users to quickly switch between multiple API service endpoints without manually modifying environment variables or configuration files each time. Claude Code is Anthropic's command-line AI programming assistant that runs directly in the terminal, capable of reading/writing files, executing commands, and performing code search and refactoring. Claude Desktop is its desktop client version with a graphical interface. Both tools connect to Anthropic's official API by default, but can be pointed to any Anthropic-protocol-compatible third-party endpoint through environment variable configuration. CC Switch leverages this mechanism — through its model mapping feature, users can route a model name displayed in the Claude interface to a completely different backend model, enabling flexible model resource scheduling without changing usage habits.
Here are the specific configuration steps:
- Open CC Switch
- Click the plus button and select "Custom Configuration"
- Service endpoint type: Select "Claude-compatible API service endpoint"
- API Key: Enter your OpenModel key
- Name can be anything; website link can be left blank
Model Mapping Setup
Since DeepSeek V4 Flash is not a native Claude model, you need to set up model mapping:
- You can map lower-capability models like Claude Haiku to DeepSeek V4 Flash
- You can also map models like Claude 4.6 to it
This way, when you select the corresponding model in Claude Code or Claude Desktop, it actually calls the free DeepSeek V4 Flash.
Usage Recommendations and Summary
Recommended Use Cases
| Scenario | Recommended Model |
|---|---|
| Core coding tasks | Claude Opus 4 / GPT-5.5 |
| Document organization, spreadsheet processing | DeepSeek V4 Flash (free) |
| Information retrieval, web queries | DeepSeek V4 Flash + MCP |
| Long text analysis (ultra-long context) | DeepSeek V4 Flash (1M context) |
Important Notes
- The promotion end date is undetermined — follow OpenModel's official announcements
- Only Anthropic-compatible protocol is supported; OpenAI standard format is not supported
- The free tier has rate limits (10 RPM / 100K TPM); be mindful during high-frequency usage
- Coding capabilities are limited; core development tasks should still use your primary model
Overall, the limited-time free promotion for DeepSeek V4 Flash provides developers with a zero-cost, high-quality backup model option. The 1M context window, deep thinking, and tool calling support make it excellent for handling everyday miscellaneous tasks. While the promotion is still active, get it configured now.
Related articles

DeepSeek Researcher Summarizes 10 Rules for Using AI Agents
A DeepSeek researcher shares 10 universal rules for using AI agents, covering the shift from execution to judgment, memory file systems, human-AI collaboration boundaries, and more.
Agent Harness: A New AI Agent Paradigm from Prompt Engineering to Execution Environment Orchestration
Deep dive into Agent Harness Engineering: how loop execution and context isolation overcome the bottlenecks of prompt and context engineering in modern AI coding agents like Cursor.

1FlowBase in Practice: Adding Vision Tools to DeepSeek V4 for Multimodal Capabilities
Learn how to use 1FlowBase to mount MIMO 2.5 as a vision tool on DeepSeek V4, creating a Fusion multimodal endpoint with step-by-step orchestration guide.