Agent Middleware: Adding Interceptors to Model Calls
Use middleware to add logging, security checks, and other interceptors to AI Agent model calls.
This article explains the Agent Middleware mechanism — an AOP-inspired approach to inserting custom logic before and after model calls. Through two practical examples (logging middleware and security check middleware), it demonstrates two key design patterns: the Observer (returns None, non-intrusive) and the Guardian (returns Dict, intercepts flow). It also covers middleware composition using the Onion Model and production considerations.
When building AI Agents, we often need to insert custom logic before and after model calls — such as logging, security checks, or even intercepting dangerous requests outright. This is where the Middleware mechanism comes into play. It acts as an interceptor, allowing you to flexibly inject any logic you want into the lifecycle of an Agent's model calls.
This article walks you through two practical examples — a logging middleware and a security check middleware — to help you thoroughly understand how Middleware works and how to use it.
What Is Agent Middleware?
Middleware is essentially an application of Aspect-Oriented Programming (AOP) within the Agent framework. It allows you to insert custom logic at two key points — Before Model and After Model — without modifying the Agent's core code.
Aspect-Oriented Programming (AOP) was first proposed by Gregor Kiczales' team at Xerox PARC in 1997. Its core idea is to separate cross-cutting concerns from the main business logic. In traditional software development, features like logging, transaction management, and security validation tend to be scattered across various modules, leading to code duplication and increased coupling. AOP addresses this by defining pointcuts and advice, enabling these cross-cutting concerns to be centrally managed and uniformly woven in. In AI Agent frameworks, model calls serve as natural pointcuts — each LLM inference represents a clear execution boundary, making it ideal for inserting additional logic before and after. This shares the same design philosophy as interceptors in Java Spring, middleware in Python Django, and the middleware chain in Node.js Express — just different implementations of the same concept.
The benefits of this design are obvious:
- Decoupling: Cross-cutting concerns like logging and security checks are separated from business logic
- Composability: Multiple Middlewares can be stacked together without interfering with each other
- Flexible control: A Middleware can act as a mere "Observer" (logging) or as a "Guardian" (intercepting requests)
Example 1: Logging Middleware
The goal of the first Middleware is simple — record key information before and after model calls to facilitate debugging and tracking conversation progress.
Before Model: Logging Before the Call
Define a class that inherits from AgentMiddleware and implement the before_model method. Before the model call, print the length of the current message list so you can clearly see which round of conversation you're on.
There's a key detail here: the return type is None. Because the logging middleware is just an "Observer" — it doesn't need to intervene in any process. Returning None tells the framework: "I'm just watching. Carry on."
After Model: Logging After the Call
The after_model method executes after the model responds. We can grab the last message, truncate it to the first 50 characters, and print it for a quick preview of the model's response.
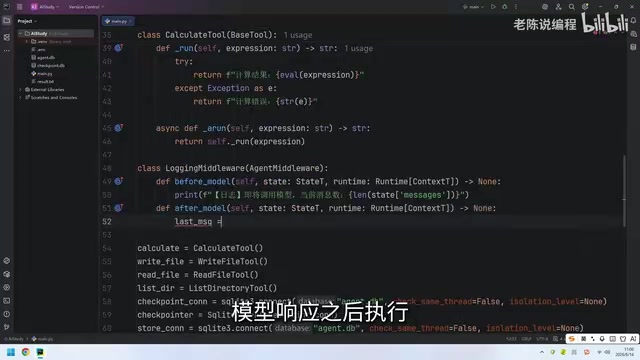
This approach is extremely useful during debugging, allowing you to quickly understand the model's behavior without opening full logs.
Example 2: Security Check Middleware
The second Middleware goes beyond just "watching" — it's a true Guardian, responsible for intercepting dangerous operations.
The Key Difference: Change in Return Type
It also inherits from AgentMiddleware, but the focus is on the before_model method implementation. The biggest difference from the logging middleware is: the return type is Dict | None, not just None.
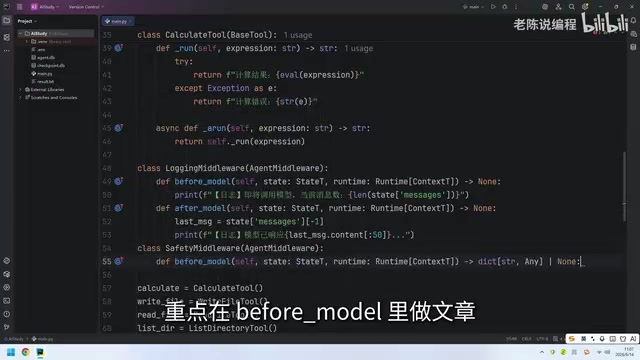
Why this design? Because the security check middleware may need to actively intervene in the process. When it detects a problem, it needs to return a dictionary to tell the framework what to do. This design pattern is known in computer science as "Short-Circuit Evaluation" or "Early Return." In the context of an Agent framework, this means the middleware can completely bypass the LLM inference process and directly inject a preset response. This capability is critically important in production environments: on one hand, it prevents sensitive content from being sent to external APIs (reducing data leak risks); on the other hand, it saves unnecessary API call costs (every LLM call incurs token fees). From an architectural perspective, this is similar to an HTTP middleware returning 403 Forbidden to reject a request outright, rather than letting it reach the backend service.
Implementation of the Interception Logic
The specific check logic works as follows:
- Get the content of the last user message
- Check whether it contains sensitive keywords like "delete" or "danger"
- If a match is found, return a dictionary containing control directives
The returned dictionary contains two key fields:
jump_to: "end": Tells the framework to skip the model call and end the current flow immediately- An AI Message: Injects a preset reply message informing the user that the operation has been terminated
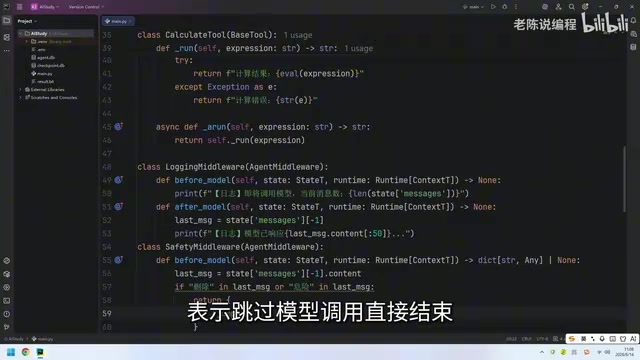
The meaning of this return value is crystal clear: Don't call the model. End immediately. And add this safety notice to the conversation. If the check passes without issues, it returns None, meaning "No objections from me — proceed as normal."
Combining Middlewares: Giving Your Agent Multiple Capabilities
The final step is to combine both Middlewares and pass them to create_agent:
agent = create_agent(
model=model,
middleware=[LoggingMiddleware(), SecurityMiddleware()]
)
This way, the Agent simultaneously has both logging and security interception capabilities. On each model call, the request passes through every Middleware's before_model in sequence, and the response passes through every Middleware's after_model in sequence.
When multiple Middlewares are combined, their execution follows an order similar to the Onion Model. During the request phase (before_model), they execute in registration order; during the response phase (after_model), they execute in reverse order, forming a symmetric call stack. This pattern is very common in web frameworks — for example, Koa.js's middleware mechanism. In the example above, the before_model execution order is Logging → Security, while the after_model execution order is Security → Logging. This means that if the security check middleware intercepts a request during the before_model phase, the subsequent model call and all after_model logic will not execute. Understanding this execution order is crucial for correctly designing the registration order of your middlewares.
Two Roles of Middleware: Observer and Guardian
Through these two examples, we can summarize two typical roles for Middleware:
| Role | Return Value | Typical Scenarios |
|---|---|---|
| Observer | Always returns None | Logging, performance monitoring, data analytics |
| Guardian | Conditionally returns Dict | Security checks, permission validation, content filtering |
The elegance of this design pattern lies in: distinguishing middleware responsibilities through different return value types. Returning None means "let it pass"; returning Dict means "I'm taking control." This allows the framework to support vastly different use cases through a unified interface.
In real-world projects, you can extend this to create many more types of Middleware, such as:
- Token counting middleware: Track the number of tokens consumed per call
- Caching middleware: Return cached results directly for identical queries
- Rate limiting middleware: Control model call frequency
- Content moderation middleware: Perform compliance checks on model output
When deploying these middlewares in production, several key engineering concerns need to be addressed. First, performance overhead: each middleware adds call latency, and middlewares involving I/O operations (such as writing to log databases or calling external moderation APIs) should use asynchronous execution. Second, error handling: exceptions within a middleware itself should not crash the entire Agent — robust try-catch mechanisms and fallback strategies are essential. Third, observability: the execution state of middlewares themselves also needs to be monitored, forming meta-monitoring. Additionally, in multi-Agent collaboration scenarios (such as frameworks like CrewAI and AutoGen), middlewares also need to handle interception of inter-Agent message passing, further increasing complexity. Currently, mainstream Agent frameworks like LangChain's Callbacks and OpenAI Agents SDK's Hooks mechanism are essentially different implementation forms of the middleware concept.
The Middleware mechanism makes Agent capability extension modular and pluggable — it's an indispensable piece of infrastructure for building production-grade AI Agents.
Key Takeaways
- Middleware is an implementation of AOP in Agent frameworks, inserting custom logic before and after model calls through before_model and after_model hooks
- The Observer pattern (returning None) is suited for non-intrusive scenarios like logging and monitoring
- The Guardian pattern (returning Dict) is suited for scenarios requiring flow interception, such as security checks and permission validation
- Multiple middlewares execute in Onion Model order, where registration order determines execution priority
- In production environments, attention must be paid to middleware performance overhead, error isolation, and observability
Related articles
Mistral Le Chat Image Generation Review: Can It Replace Fable?
Mistral AI launches image generation in Le Chat, dubbed Le Chaton Fat. We analyze its capabilities, compare it with Fable, and explore the trend of AI chat platforms integrating image generation.
Testing DeepSeek's Safety Mechanisms: Multiple Jailbreak Attempts Successfully Blocked
An overseas security blogger systematically tested DeepSeek's jailbreak resistance using direct requests, rephrased prompts, and varied strategies. Results show robust intent recognition, consistent blocking, and context-aware safety mechanisms.
A Middle Schooler with Zero Coding Skills Built a Story-Driven Game with AI: Creativity Unshackled from Technical Barriers
A middle schooler with no coding experience used AI to build an interactive story game with branching choices and surreal alien adventures. We explore what this means for creative democratization.