AI Agent Loops in Practice: Four PRs Auto-Merged While I Slept
Build AI Agent loops that auto-create, review, and merge PRs while you sleep.
Theo (t3.gg founder) shares his shift from manual AI prompting to building Agent loops where AI prompts itself, reviews its own code, and merges PRs autonomously. In one real-world case, a single message triggered four stacked PRs that were auto-reviewed and merged overnight. The article covers practical methods to start building Agent loops, cost analysis showing 17:1 value on subscriptions, and why dynamic workflows that match problem shapes outperform fixed processes.
From Manual Prompting to Automated Loops: Another Paradigm Shift in Programming
If you're still writing prompts to your AI coding assistant one by one, then manually copying and pasting results into your codebase, you might already be behind. Well-known developer Theo (founder of t3.gg) shared his journey in a recent video — going from "manual prompting" to "building Agent loops" — letting AI Agents prompt themselves, review themselves, and drive entire workflows forward.
This isn't science fiction. It's how he works every day. And the results are surprisingly good.
What Are Agent Loops? Why Are They Better Than Manual Prompting?
The typical flow for AI-assisted programming used to look like this: have the model create a plan → read the plan → execute step by step → have another Agent review → bring feedback back to the first Agent. Throughout this entire process, the human is the one driving the loop. You're responsible for passing context between each step, making sure every Agent has enough information.
This approach is essentially still an extension of traditional Prompt Engineering — a multi-turn human-AI dialogue where the human always plays the role of "dispatcher." Agent loops (Agentic Loops), on the other hand, borrow from the concept of automated Orchestration, giving AI systems the ability to autonomously plan, execute, evaluate, and iterate. This concept shares a striking resemblance to CI/CD (Continuous Integration/Continuous Deployment) pipelines in software engineering — except each node in the pipeline is no longer a predefined script, but an AI Agent with reasoning capabilities.
Theo admitted he used to work the old way too. Although he'd seen automated loop solutions like Ralph Loop before, those approaches dramatically increased error rates — they looked cool but weren't practical enough.
What truly changed his mind was a tweet from Pete: "Tell Codex to maintain your repo. Wake it up every five minutes, distribute work across different threads." The key insight was — one Codex thread can spawn another thread. This means Agents can orchestrate parallel work on their own.
The Codex referenced here is OpenAI's cloud-based Agent product (not the earlier code completion model), which supports multi-threaded concurrent execution. Each thread is essentially an independent sandbox environment with its own filesystem snapshot and execution context. The critical technical breakthrough is inter-thread communication — one thread can launch another through API calls or tool use, passing along necessary context. This is similar to the process fork mechanism in operating systems, except instead of running deterministic programs, it's running AI Agents with reasoning capabilities. This architecture allows a "coordinator" Agent to break large tasks into subtasks, distribute them to different threads for parallel execution, and aggregate the results.
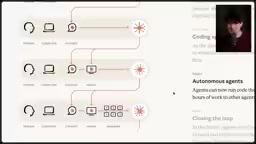
Theo specifically emphasized that the approach of predefining various "role personas" (security reviewer, adversarial reviewer, exploration Agent, etc.) is wrong. AI's core advantage lies in dynamism — Agents can build their own context and working methods as needed, without everything being hardcoded in advance. It's like being given a project template where all files are already created and you can only edit within existing files — that's dumb.
Real-World Case Study: One Message Triggers Four Auto-Merged PRs
Theo shared an impressive real-world example. While refactoring Lakebed's isolation layer, Claude 5.5 analyzed the codebase and identified significant optimization opportunities in the data architecture, including dependency-aware invalidation, mutation coalescing, and per-app invalidation batching.
A few of the technical concepts here are worth explaining. "Dependency-aware invalidation" is a core strategy for data caching layers — it ensures that when underlying data changes, all cache entries depending on that data are correctly invalidated, preventing stale data issues. "Mutation coalescing" combines multiple write operations into a single batch operation to reduce I/O overhead and database pressure. These are critical mechanisms that must be carefully designed when building high-performance data layers, typically requiring senior engineers to spend significant time planning and implementing.
This clearly wasn't something a single PR could handle. The model itself determined that at least three stacked PRs were needed, with some being parallelizable. Stacked PRs are an advanced code review strategy where a large change is split into multiple Pull Requests with dependency relationships, arranged in order as a "stack." Each PR contains only one logically independent change, but subsequent PRs depend on code from preceding PRs. This approach makes code review more focused and efficient — reviewers only need to understand one smaller change at a time.
Then Theo sent what he called "the most psychologically impactful message":
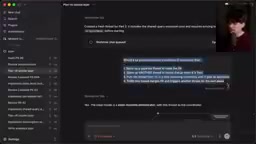
He asked the Agent: Can you create a workflow that —
- Spawns a new thread to create a PR
- After the PR is submitted, spawns another thread to review it
- Has the implementation thread loop through review comments until everything passes
- After merging the PR, automatically triggers the next one
The Agent not only understood this request but also designed a heartbeat mechanism: polling every 5-10 minutes, checking PR status, creating review threads, sending feedback, re-reviewing after fixes, and after merging, pulling the latest main branch before creating the next worktree.
The Heartbeat Mechanism is a classic design pattern in distributed systems, originally used to detect whether nodes in a cluster are alive. In the context of Agent loops, it's redefined as a polling strategy: the Agent proactively checks for external state changes at fixed time intervals — such as whether a PR has new review comments, whether the CI pipeline has passed, or whether code has been merged. Compared to event-driven Webhook approaches, polling is less real-time but simpler to implement and more fault-tolerant — even if an event notification is lost, the next poll will catch the state change. This "wake-check-act-sleep" cycle is essentially a simplified version of an Event Loop.
The result: started at 2:29 AM, finished at 6:50 AM. Theo went to sleep and woke up to find four stacked PRs thoroughly reviewed and fully merged.
The craziest part — this wasn't a hardcoded fixed loop. It was a dynamically generated workflow where the Agent's loop created its own sub-loops, tailored to the specific needs of the problem.
Agent Loop Practices You Can Start Right Now
Theo offered an extremely practical piece of advice: Observe what you do after the Agent finishes a task, then hand those steps to the Agent too.
A typical development workflow looks like: Agent writes code → you run the dev server → check if it works → commit code → push and create a PR → wait for code review → address feedback → request team review → merge.
Every single step here can be delegated to the Agent:
- Tell the Agent to run the dev server and verify on its own after finishing
- Tell the Agent to auto-commit and create a PR after verification passes
- Tell the Agent to monitor PR comments and automatically address feedback
- Have the Agent spawn other threads for independent code reviews
An even sharper insight: We look at code too early. If you're reading the code yourself before another Agent has reviewed it, you're wasting time. The obvious mistakes? The Agent can find and fix those on its own. By the time a human steps in, all the low-level issues have been cleaned up, and you can focus on the hard parts that truly require human judgment.
Cost and Limitations of Agent Loops: Not as Expensive as You Think
Loops do consume more tokens. Theo mentioned an extreme case: one Agent spent less than 10 minutes leaving feedback, while an Opus workflow ran for 8 hours based on that feedback, consuming over 3 million tokens — just to address three minor comments.
To understand what that number means: tokens are the basic billing unit for large language models, roughly equivalent to 3/4 of an English word (for Chinese, approximately 1-2 characters per token). 3 million tokens is roughly equivalent to processing a 2,000-page technical book. At Anthropic's API pricing (Claude Opus at approximately $15/million input tokens, $75/million output tokens), the inference cost for 3 million tokens could reach hundreds of dollars. This is why the choice of billing model matters enormously.
But if you're on a subscription plan rather than API billing, the picture changes completely. On the $200/month Claude Code plan, Theo ran five such loops simultaneously along with all his other work, and only used 29% of his weekly quota.
He did the math: in June (only 17 days), inference usage across all machines was approximately $10,000, but he only paid $600 in subscription fees (three $200 plans). That means roughly $17 of inference value for every $1 of subscription cost.
This 17:1 value ratio reveals an important market dynamic: AI companies are likely operating at a loss on heavy subscription users, subsidizing usage to build habits and lock in market share. This mirrors the strategy of early cloud computing providers (like AWS) — acquire users at below-cost pricing, build ecosystem stickiness, then gradually adjust pricing. For developers, this means the current moment is the best window to take advantage of the subscription arbitrage.
If you're already paying for a subscription but nowhere near using your full quota, you're wasting money. Theo's advice: treat those limits as a challenge and try to max them out.
The Essence of Loops: Making the Workflow Shape Match the Problem Shape
Theo used a brilliant analogy. In traditional Agile development, teams follow a fixed sprint structure — pulling tasks from the backlog every week or two, estimating effort, prioritizing. Work is forced to fit this fixed shape. But the most effective teams are those that build unique workflows around specific problems.
Traditional Agile Development frameworks like Scrum prescribe fixed iteration cycles (Sprints, typically 1-4 weeks), fixed ceremonies (daily standups, Sprint retrospectives, review meetings), and fixed roles (Scrum Master, Product Owner, development team). This structured methodology has dramatically improved software development efficiency over the past two decades, but its core assumption is that human developers have limited cognitive bandwidth and need processes to manage complexity and reduce communication overhead. AI Agent loops break this assumption — when the executors are tireless, infinitely parallelizable AIs, fixed iteration structures become the bottleneck.
The true magic of AI Agent loops is this: the shape of the workflow can be dynamically generated based on the shape of the problem. You don't adapt to a fixed process — the process automatically adapts to your problem. A simple bug fix might only need a linear flow, while a complex architectural refactor might automatically generate a complex DAG (Directed Acyclic Graph) structure with parallel branches, review gates, and rollback mechanisms — all without requiring human pre-design.
This isn't limited to code. Theo even used similar loop thinking to monitor the best 5G hotspot plans, and his loop randomly pinged him on Discord about a new Verizon plan that had just launched — getting him the information earlier than most people.
Final Thoughts
Loops are powerful not because the technology itself is flashy, but because the idea of making Agents do more has enormous leverage. If you take away just one action item from this article, let it be this: next time an Agent finishes a task, don't rush to take over — first ask it, "Can you do the next step too?"
You might be as surprised by the results as Theo was.
Related articles
Vibe Coding in Practice: How a Product Manager Built a Study App from Pain Point to Launch Using AI Tools
A product manager used AI tools like Claude Code to independently build a quiz app from exam prep pain points to launch. A full walkthrough of Vibe Coding methodology, MVP definition, and testing.

PilotDeck: A Local Console That Tames Multi-Task Agent Chaos
PilotDeck is an open-source local Agent console from a Tsinghua-affiliated team that solves multi-task chaos with workspace isolation, white-box memory management, and smart model routing.
Fusion Startup Funding Landscape: A Deep Dive into the $7.1 Billion Flow and Industry Dynamics
Global fusion startups have raised $7.1B, heavily concentrated in top players. A deep analysis of funding patterns, tech pathways, commercialization challenges, and the investment logic behind this ultimate energy bet.