AI Automated Review Becomes the Default: How a Sub-Agent Classifier Achieves 97% Accuracy
AI auto-review with a 97%-accurate classifier subagent is now the default safety mechanism for AI agents.
Auto-review is now enabled by default for all new AI agent users, powered by a context-aware classifier subagent that makes three-tier decisions — allow, block, or ask for approval — on every operation. Achieving 97% accuracy, with most errors at ambiguous edges, this mechanism represents a shift toward security-by-default design and the rise of subagent supervision in AI safety, though challenges like adversarial attacks and alert fatigue remain.
Core Development: Automated Review Goes Live by Default
The AI tooling landscape has received a significant safety mechanism update — auto-review is now the default setting for all new users. This means that when users employ AI agents to perform operations, the system automatically evaluates the safety of every action without requiring manual activation.
At the heart of this feature is a classifier subagent that reviews every operation an AI agent performs within context, then makes one of three decisions: allow execution, block execution, or request user approval. The classifier subagent is a nested AI architecture whose core idea is to insert an independent AI model dedicated to safety evaluation into the main AI agent's execution pipeline. This architecture draws on the "privilege separation" design philosophy from operating systems — the agent executing operations and the agent reviewing operations run independently, preventing a single model from being both player and referee. In terms of technical implementation, the classifier subagent typically receives the main agent's complete context window (including user instructions, conversation history, and the specific operation to be executed), then performs reasoning based on safety policies. Compared to traditional static rule engines (such as regex matching or blacklist/whitelist filtering), an LLM-based classifier can understand the semantics and intent of natural language, exhibiting greater robustness when facing variations in phrasing, implicit instructions, and other complex scenarios.
Technical Implementation: Context-Aware Three-Tier Decision Making
How the Classifier Subagent Works
Unlike simple rule-based filtering, this classifier subagent possesses contextual understanding. Rather than mechanically matching keywords or preset rules, it makes judgments after understanding the full context of the current operation. This design enables it to distinguish between operations that appear similar but have entirely different intents.
Context awareness is the key feature that differentiates modern AI safety mechanisms from traditional security filters. Conventional content filtering systems typically operate in a stateless manner — they check inputs or outputs one by one without considering surrounding context. For example, a simple keyword filter might block any instruction containing "delete all files" across the board, even though in context this might be a perfectly reasonable request from a user explicitly asking to clean up a temporary cache. A context-aware classifier, by contrast, considers multiple dimensions of information including the user's instruction history, current working directory, and the sensitivity of the target objects to make more precise judgments. This capability is especially important in AI agent scenarios, where agents often need to execute multi-step compound tasks. Examining a single step in isolation may make it impossible to assess its safety — only by placing it within the complete task chain can a reasonable evaluation be made.
The three-tier decision mechanism is elegantly designed:
- Allow: Clearly safe operations are passed through directly without interrupting the user's workflow
- Block: Clearly dangerous operations are intercepted immediately to prevent potential risks
- Ask for approval: Operations in the gray zone are escalated to the user for judgment
This layered approach ensures security while minimizing disruption to the user experience.
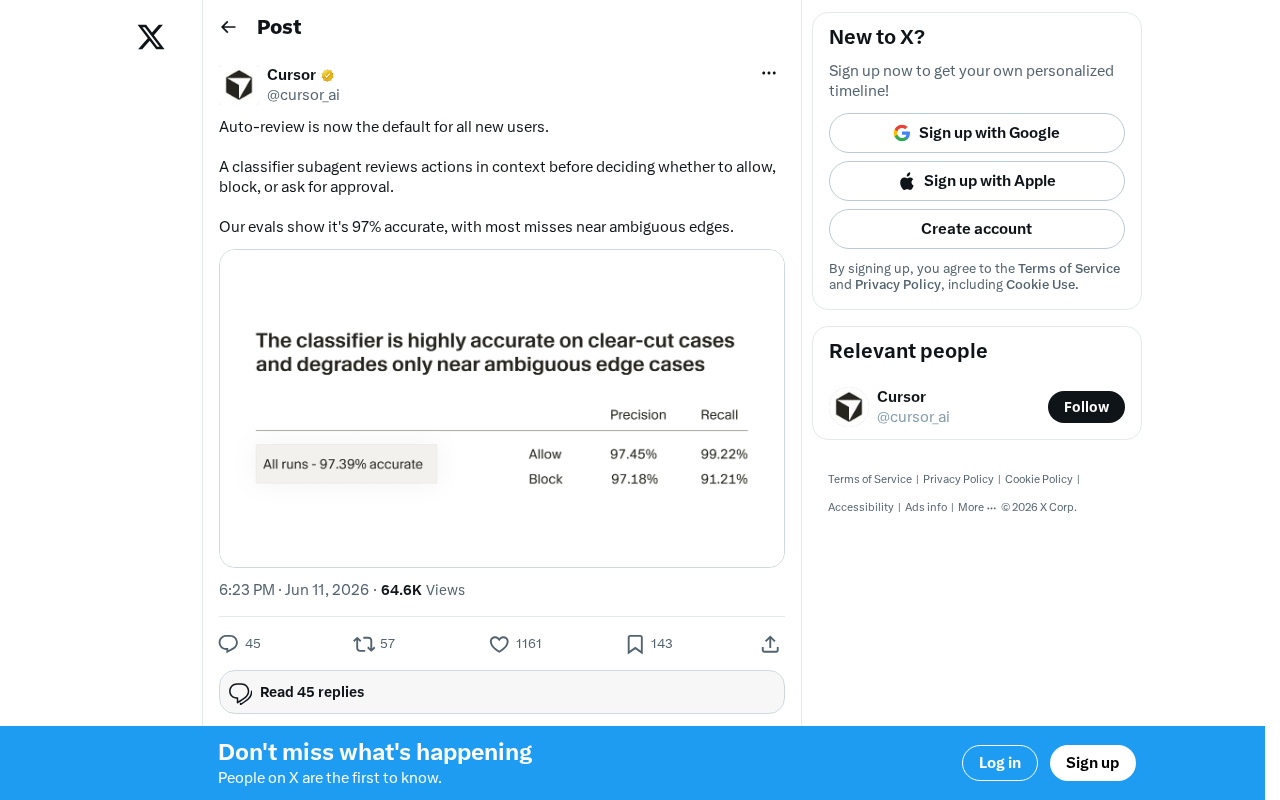
97% Accuracy and Ambiguous Boundary Analysis
According to official evaluation data, the classifier achieves an accuracy rate of 97%. The developers have also candidly acknowledged that most misclassifications occur near "ambiguous edges" — operations that are inherently difficult to categorize definitively as safe or dangerous.
In machine learning classification tasks, 97% accuracy needs to be evaluated in the context of the specific scenario. For safety classifiers, the more critical metrics are often the balance between Precision and Recall — that is, what proportion of errors are false positives (flagging safe operations as dangerous) versus false negatives (letting dangerous operations through). In the security domain, the cost of false negatives is typically far higher than that of false positives. For reference, mainstream email systems' spam filters typically achieve accuracy rates above 99%, but the classification task they face is relatively straightforward. The semantic space that AI agent operation review must navigate is far more complex than spam classification, making 97% accuracy quite impressive at the current state of the art. Notably, the fact that officials specifically mentioned misclassifications are concentrated at "ambiguous edges" suggests that the classifier's performance on clearly safe and clearly dangerous operations likely far exceeds 97%, while accuracy in uncertain zones is significantly lower than this figure.
A 97% accuracy rate means approximately 3 out of every 100 judgments may be off. Whether this error rate is acceptable for high-frequency use cases depends on the specific scenario and risk tolerance.
Industry Significance: A New Paradigm for AI Agent Safety
From Passive Defense to Proactive Review
The rollout of this mechanism reflects an important trend in AI agent security: safety mechanisms are shifting from user-initiated configuration to system-enabled defaults. Making auto-review the default option embodies a "security by default" design philosophy.
"Security by default" is not a new concept in AI — it has deep historical roots in software engineering and cybersecurity. The idea can be traced back to Saltzer and Schroeder's 1975 principle of "fail-safe defaults" — a system's default state should deny access rather than grant it. In practice, Microsoft's "Trustworthy Computing" initiative launched in 2002 was a landmark event for this philosophy, after which practices like enabling firewalls by default in Windows and activating security sandboxes by default in browsers gradually became industry standards. Adopting this principle in the AI agent domain means that safety mechanisms no longer depend on users' proactive configuration awareness — instead, protection is built in as the product's factory state. This is critically important for reducing security incidents caused by user oversight.
The Rise of Subagent Supervision
Using one AI to supervise another AI's behavior — this "subagent supervision" pattern is becoming an important direction in AI safety. Compared to traditional rule engines, AI-based review systems offer stronger generalization capabilities and contextual understanding, enabling them to handle more complex scenarios.
This approach is closely related to several cutting-edge directions in AI Alignment research. OpenAI's "Scalable Oversight" framework argues that as AI systems grow more capable, direct human supervision of every AI decision will become infeasible, necessitating AI-assisted oversight to achieve supervision at scale. Anthropic has proposed the "Constitutional AI" method, which uses one AI model to evaluate and correct another AI model's outputs based on preset principles. Additionally, the "Debate" mechanism has two AI models challenge each other's reasoning processes to expose potential errors or risks. The classifier subagent in auto-review can be seen as a practical engineering implementation of these theoretical frameworks — it translates abstract alignment goals into concrete, deployable safety review workflows.
Potential Challenges Facing Automated Review
This approach also faces several noteworthy challenges:
- Performance overhead: Every operation must pass through classifier review, potentially increasing response latency
- Alert fatigue: A 3% error rate in high-frequency scenarios could lead to users being frequently interrupted
- Adversarial attacks: Could the classifier itself be bypassed or deceived by carefully crafted inputs?
- Decision transparency: Can users clearly understand the specific reasons why an operation was blocked?
Among these, the threat of adversarial attacks deserves particularly close attention. In the context of AI safety classifiers, such attacks can take multiple forms: Prompt Injection manipulates the classifier's judgment by embedding special instructions in user input; Indirect Prompt Injection injects malicious instructions through external data sources (such as web content or documents), and the classifier may fail to identify them because these instructions appear to come from legitimate data sources. Furthermore, there is the risk of "Gradual Jailbreaking" — where attackers guide an AI agent toward executing dangerous operations through a series of seemingly harmless small steps, each of which might pass the classifier's review individually, but collectively constitute a security threat. These challenges make AI safety review an ongoing adversarial process rather than a once-and-for-all solution.
Conclusion: Balancing Safety Guardrails and User Experience
Making automated review the default is one of the hallmarks of AI agents reaching maturity. While 97% accuracy isn't perfect, the candid acknowledgment of challenges at "ambiguous edges" is commendable. As AI agent capabilities continue to grow, the importance of such safety guardrails will only increase. The key going forward lies in finding the optimal balance between security and user experience — this is not merely a technical problem, but a systemic endeavor that requires coordinated progress across product design, user education, and industry standard-setting.
Related articles
Mistral Le Chat Image Generation Review: Can It Replace Fable?
Mistral AI launches image generation in Le Chat, dubbed Le Chaton Fat. We analyze its capabilities, compare it with Fable, and explore the trend of AI chat platforms integrating image generation.
Testing DeepSeek's Safety Mechanisms: Multiple Jailbreak Attempts Successfully Blocked
An overseas security blogger systematically tested DeepSeek's jailbreak resistance using direct requests, rephrased prompts, and varied strategies. Results show robust intent recognition, consistent blocking, and context-aware safety mechanisms.
A Middle Schooler with Zero Coding Skills Built a Story-Driven Game with AI: Creativity Unshackled from Technical Barriers
A middle schooler with no coding experience used AI to build an interactive story game with branching choices and surreal alien adventures. We explore what this means for creative democratization.