AI Coding Tools Say Goodbye to Monthly Subscriptions: The Era of Usage-Based Billing Has Arrived
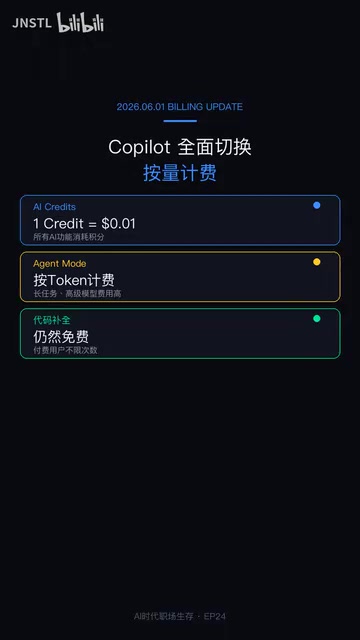
GitHub Copilot shifts to pay-per-use billing, signaling the end of flat-rate AI coding subscriptions.
GitHub Copilot's switch to usage-based billing marks the end of all-you-can-eat AI coding subscriptions. With Agent mode and advanced features now charged per Token, developer costs could surge 25x. As AI companies like Anthropic pursue IPOs, the industry faces a core tension: providers need revenue growth while customers lack cost management capabilities. Developers must now master AI Cost Engineering—model selection, context pruning, task decomposition, and budget controls—to maintain ROI.
GitHub Copilot's Billing Model Undergoes a Seismic Shift
2025年6月1日, a landmark event occurred: GitHub Copilot officially switched from monthly subscriptions to usage-based billing. This marks the formal end of the "all-you-can-eat" model that had persisted in AI coding for over two years.
Under the new rules, basic code completion remains free, but the features with real productivity value—Agent mode, complex task execution, advanced model calls—are all now charged per Token consumed. Once your AI credits run out, you either stop using it or pay to top up.
To understand this, you need to grasp the underlying logic of Token-based billing: Tokens are the basic units that large language models use to process text, and they don't simply correspond to a single word or character. In English, one Token roughly equals 4 characters or 0.75 words; in code, a function name or an operator might be split into multiple Tokens. Model billing is divided into input Tokens (content sent to the model by the user) and output Tokens (the model's generated response), with output Token pricing typically 3-5x that of input. When developers use Agent mode to execute complex tasks, the model needs multiple rounds of reasoning, tool calls, and file reads—Token consumption can be tens or even hundreds of times that of simple Q&A. This is the technical root cause of runaway costs.
When the news broke, the developer community reacted intensely. Some estimated their daily usage and found that monthly costs could skyrocket from the original $29 to $750—a 25x increase. GitHub's official discussion thread was flooded with thousands of comments within days, with "false advertising" and "pricing trap" becoming the most frequent phrases.
The AI Industry's Billing Crisis Is Spreading
This isn't an isolated incident from GitHub alone. On the same day, Anthropic—the company behind Claude—officially filed for an IPO, targeting a valuation of $4 trillion.
Anthropic was founded in 2021 by Dario Amodei, former VP of Research at OpenAI, with a "safety-first" AI development approach. Its flagship Claude model series excels at coding, analysis, and other tasks. As of 2025, Anthropic has raised over $15 billion in total funding, with investors including Amazon (over $8 billion) and Google. Filing for an IPO means the company needs to prove the sustainability of its revenue growth to public markets. Reportedly, Anthropic's 2024 annualized revenue was approximately $1 billion, but operating costs (primarily GPU compute) are equally staggering. This "high revenue, high burn" model forces AI companies to find balance between user growth and unit economics—and passing cost pressure onto users is a direct manifestation of this balancing act.
However, behind the glamorous valuation, enterprise customers are experiencing "AI bill shock."
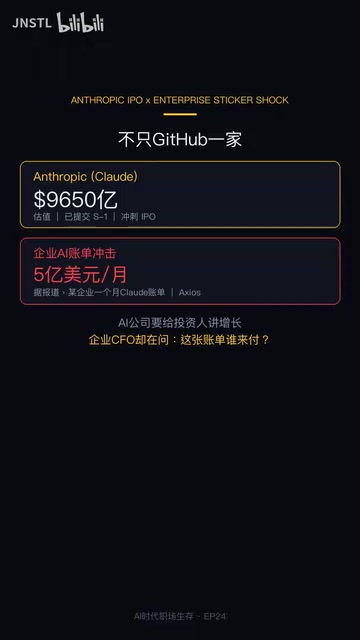
According to Axios, an industry consultant revealed that one enterprise spent as much as $500 million on Claude in a single month. AI companies need growth numbers to support their IPO valuations, but confusion on the customer side is also intensifying: how do you account for this rapidly ballooning AI expenditure? Where's the ROI?
This exposes the core contradiction in current AI commercialization: the supply side needs revenue to prove the business model works, while the demand side hasn't yet developed the cost management capabilities to match.
The Essence: From Tool Subscriptions to Compute Consumption

The essence of this shift needs to be clearly understood: AI coding tools are transforming from "subscription memberships" into "cloud computing bills."
You used to think that paying $10 or $20 bought you the right to use a tool. But what you're actually consuming is:
- Inference compute: Every time the model thinks, it requires GPU computation
- Context window: The longer the input, the greater the consumption
- Agent runtime: Every second of autonomous task execution burns money
Regarding context windows, it's worth understanding their technical and cost implications in depth. The Context Window refers to the maximum number of Tokens a model can receive in a single processing session. Early GPT-3.5 had a context window of 4K Tokens, while mainstream models in 2025 have expanded to 128K or even 200K Tokens. A larger context window means developers can input more code files for the model to analyze at once, but the trade-off is: the computational complexity of the Transformer architecture's attention mechanism scales quadratically with sequence length (despite various optimization techniques like FlashAttention), meaning longer inputs directly translate to more GPU computation and higher costs. In practice, a mid-sized project's codebase might have hundreds of thousands of lines of code—if you indiscriminately feed it all as context, a single API call could cost several dollars.
Agent mode's compute consumption is even more staggering. Agent mode is no longer simple "ask and answer"—it lets AI autonomously plan tasks and execute multi-step operations. For example, when you tell Copilot Agent to "refactor this module and write test cases," it needs to: read relevant code files (consuming input Tokens), formulate a refactoring plan (reasoning consumption), modify code step by step (multiple rounds of output), and run tests and adjust based on results (tool-calling loops). A seemingly simple instruction might trigger 10-50 model calls behind the scenes, each involving thousands to tens of thousands of Tokens. This is why costs grow exponentially in Agent mode, and it's the technical explanation for the jump from $29 to $750.
The more powerful the model and the longer the task chain, the more uncontrollable the bill becomes. This creates a massive gap from the traditional SaaS mindset of "pay once, use freely"—and it's the root of the community's anger.
A New Skill Tree: AI Cost Engineering

The AI industry is transitioning from the "technical showmanship phase" to the "financial discipline phase." For developers, this means cultivating an entirely new capability—AI Cost Engineering.
This encompasses several dimensions:
Model selection strategy: Not every task requires the most powerful model. Use lightweight models for daily code completion (such as GPT-4o mini or Claude Haiku, costing less than one-tenth per million Tokens compared to flagship models), and reserve flagship models for architecture design. Tiered usage can dramatically reduce costs. In fact, many benchmarks show that for 80% of everyday coding tasks, lightweight models perform within 5% of flagship models, but costs can differ by 20-50x.
Context pruning: Precisely control the amount of information fed to the model—avoid dumping your entire codebase in as context. Practical tips include: only providing files directly relevant to the current task, using summaries instead of complete code, and leveraging RAG (Retrieval-Augmented Generation) to extract relevant snippets on demand.
Task decomposition: Break complex Agent tasks into multiple controllable steps rather than asking AI to "do everything from start to finish" in one go. Set clear input/output boundaries for each step—this controls Token consumption per call and avoids wasted computation if an intermediate step fails.
Budget cap settings: Manage AI usage with hard limits and alert mechanisms, just like managing cloud server budgets. GitHub Copilot already offers monthly credit cap settings, while more mature enterprise solutions include cost allocation by team and project, plus real-time monitoring dashboards.
The True Dividing Line of Future Competition
Competition among AI coding tools is shifting from "who writes better code" to "who can help users keep AI costs within ROI."
For individual developers, this means learning to be financially savvy and choosing the most cost-effective usage patterns. For enterprise teams, it means establishing AI usage governance systems—just as companies had to learn FinOps when migrating from on-premise servers to cloud computing.
The concept of FinOps (Financial Operations) originated during the 2012-2015 period of mass enterprise cloud migration. When companies shifted from purchasing fixed servers to using on-demand services like AWS and Azure, IT spending transformed from predictable capital expenditure (CapEx) to highly volatile operational expenditure (OpEx). Many enterprises experienced "bill shock" in their early cloud days—monthly cloud costs far exceeding expectations. The FinOps Foundation was established in 2019, promoting a standard framework encompassing cost visibility, optimization, and governance. Today, AI-era cost management is replaying this history, only with greater complexity: cloud computing costs are roughly linear with usage, while AI inference costs are influenced by multiple factors including model selection, context length, and task complexity, making them more volatile and harder to predict. It's foreseeable that "AI FinOps" will become a core topic in enterprise IT management over the next two years.
This billing model transition looks like a price hike in the short term, but in the long run, it's an inevitable step toward AI tools adopting mature business models. The free lunch is over, but AI applications that truly create value are still worth investing in—the key is whether you have the ability to manage that investment.
Key Takeaways
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
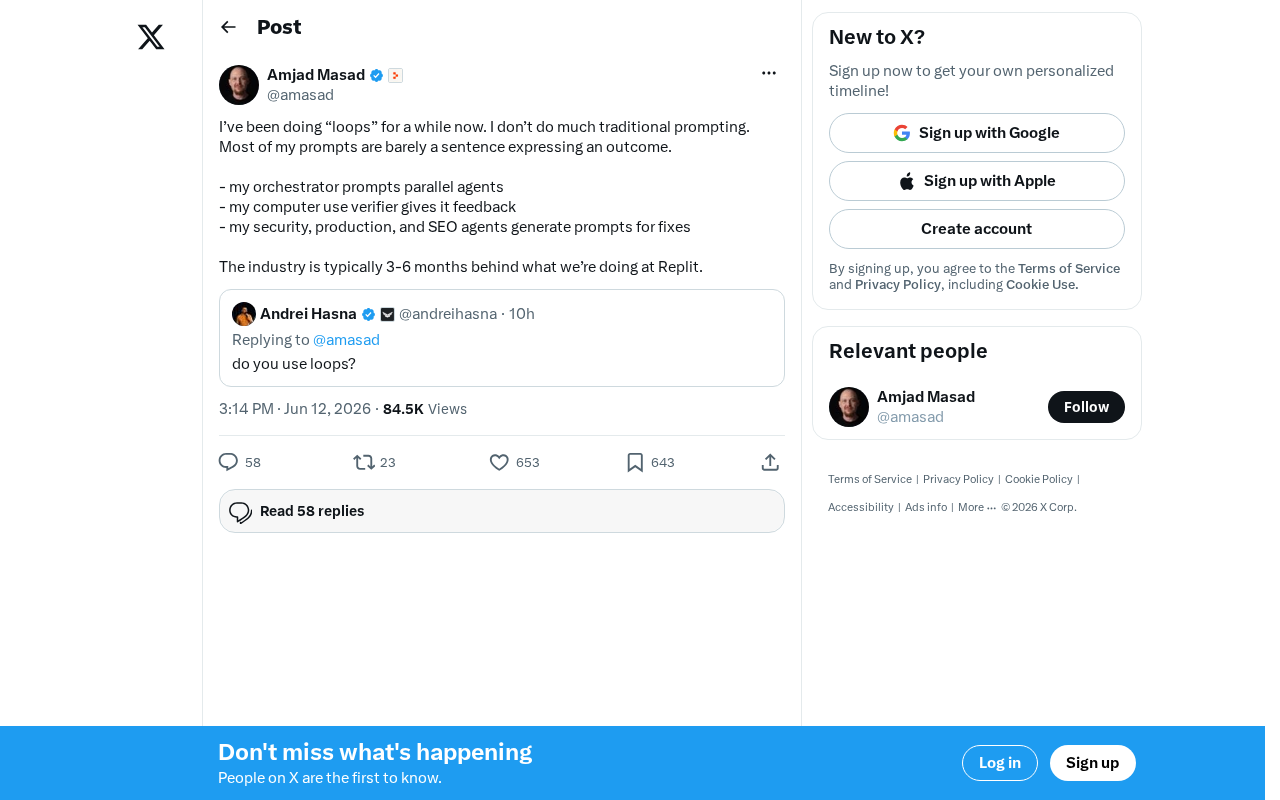
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.