AI Hallucinations: Why Large Language Models Inevitably "Make Things Up" and How to Deal With It
Dissecting the root causes, classification, and mitigation strategies of AI hallucinations from first principles.
AI hallucination isn't a bug — it's an inherent feature of how large language models work. The three root causes are: training objectives optimizing for likelihood rather than truthfulness, exposure bias causing error accumulation, and the inherent randomness of probabilistic sampling. Hallucinations can be classified as factuality/faithfulness and omission/fabrication types, each requiring targeted approaches. Practical strategies include RAG retrieval augmentation, independent evaluation layers, hard boundaries, and user verification habits — with the core philosophy of coexisting with hallucinations while building interception mechanisms.
Introduction: AI's Confident Nonsense
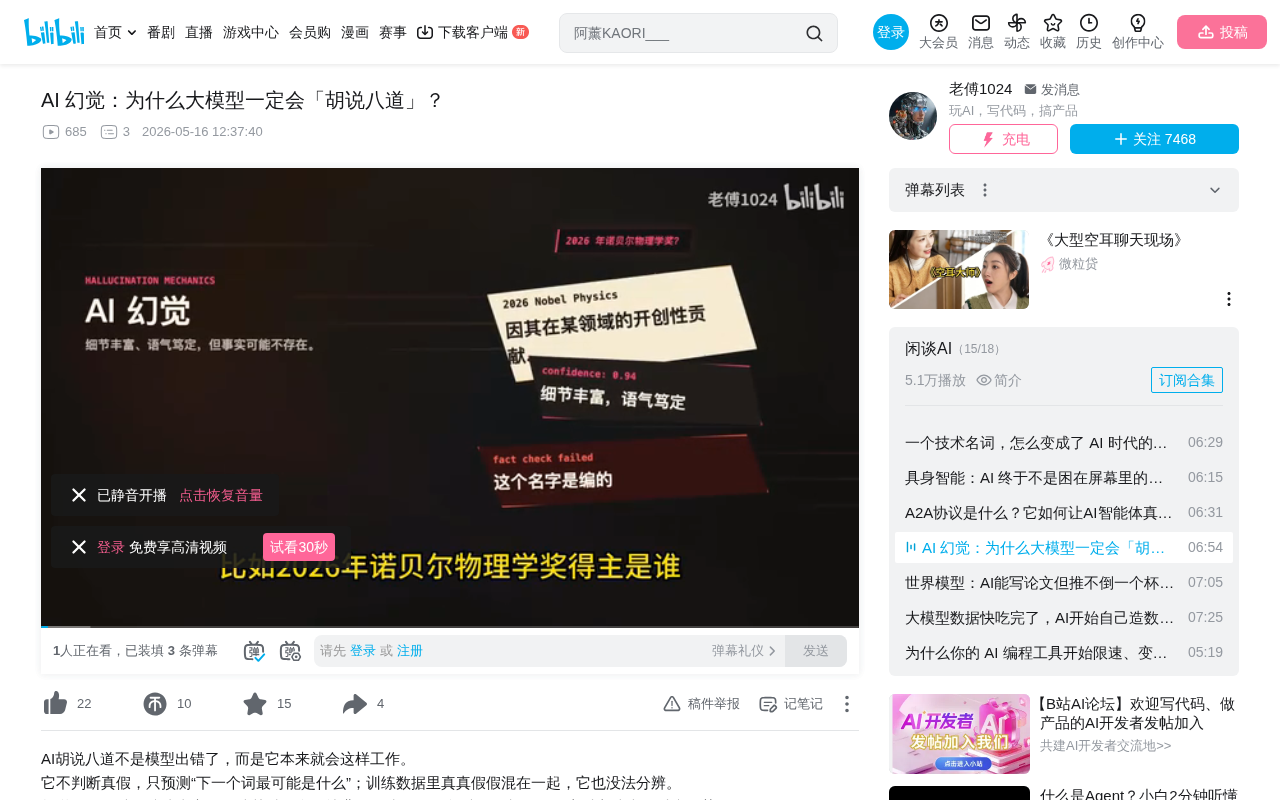
Have you ever encountered this situation: you ask an AI a question like "Who won the 2026 Nobel Prize in Physics," and it confidently gives you a name, complete with an award citation — "for their pioneering contributions in such-and-such field" — rich in detail, utterly assured in tone, and seemingly completely credible. The only problem? The name is fabricated, and so is the citation.
This is AI Hallucination. Many people's first reaction is "the model has a bug" or "the model isn't good enough," but in reality, hallucination isn't a bug — it's an inherent consequence of how large language models fundamentally work. This article will thoroughly dissect the causes, classification, and mitigation strategies for AI hallucinations from first principles.
Three Root Causes: Why Large Models Will Always Hallucinate
Root Cause 1: Inherent Flaws in the Training Objective
To understand hallucinations, you first need to forget the intuition that "AI understands the world" and return to what it's actually doing: given a preceding sequence of text, predict the next most likely token.
A "token" here is the basic unit that language models use to process text. It's not simply "one character" or "one word," but rather sub-word segments created by tokenization algorithms (like BPE, Byte Pair Encoding). For example, "understanding" might be split into "under," "stand," and "ing" — three tokens. The model's working method is called Autoregressive Generation: it predicts one token at a time, appends that token to the context, then predicts the next one, repeating this cycle until a complete response is generated. This means the model never "thinks through the entire answer before speaking" — it produces words one by one, with each step being an independent probabilistic decision.
Note the key word — "likelihood" rather than "truthfulness." The model's training objective isn't "knowing what's correct" but "guessing the next word in the training text correctly." The training data is content crawled from the entire internet: Wikipedia alongside forum spam, authoritative papers alongside deliberate fabrications, breaking news alongside articles that haven't been updated in a decade. During training, all text is treated as "correct" by the model — it has no way to distinguish real information from false information.
OpenAI stated bluntly in a research paper: "Standard training and evaluation procedures encourage models to guess rather than acknowledge uncertainty." During pre-training, the model only encounters positive examples; during post-training (RLHF), while attempts are made to teach the model not to fabricate, the evaluation mechanism still centers on accuracy.
It's worth explaining how RLHF (Reinforcement Learning from Human Feedback) works: after pre-training is complete, research teams have the model generate multiple responses to the same question, then human annotators rank these responses — which is better, which is worse. This ranking data is used to train a "reward model," which in turn guides the language model's optimization direction. The problem is that human annotators, when evaluating, are often attracted to responses that "look correct and detailed" without necessarily being able to verify the accuracy of every factual detail. This creates a paradox: RLHF is intended to align the model with human preferences, but human preferences themselves tend to reward "confident and detailed" responses.
The lesson the model learns repeatedly is: it's better to guess a plausible-looking answer than to say "I don't know" — because "I don't know" gets judged as failing to complete the response.
Human language has a characteristic: confident, fluent, detail-rich content inherently looks more reasonable than "I don't know." The tone of high-quality text on the internet is naturally assertive — expressions like "I'm not sure" appear far less frequently in training data than "according to research."
Root Cause 2: Exposure Bias — The Asymmetry Between Training and Inference
The second root cause is more subtle, known academically as Exposure Bias.
To understand this concept, you first need to know about the Teacher Forcing technique used during model training. During training, when the model predicts each token, the preceding context it sees is always the real text from the training data (i.e., the "ground truth"), not the model's own previous predictions. It's like a student practicing sentence construction where the teacher always writes the first half, and the student only needs to complete the second half. But during the exam (i.e., inference), there's no teacher — the first half is also written by the student — and if the first half is wrong, the second half will only be more wrong.
During training, the model sees perfect context — everything preceding is correct. But during inference, the model sees text it just generated itself. If what came before drifted off course, what follows will only drift further.
Here's an example: have the model write a long article, and somewhere in the middle a paragraph drifts slightly, fabricating a non-existent citation. That erroneous citation immediately becomes context for everything that follows, and subsequent content continues generating based on a false reference — one drift, and everything goes sideways.
This is why AI hallucinations are manageable in short answers but noticeably worsen in long-form text: the further along you go, the more accumulated drift from earlier, with errors snowballing. Research data shows that when generated text exceeds 2,000 tokens, the hallucination rate can be 2-3 times higher than in short answers.
Root Cause 3: Inherent Randomness of Probabilistic Generation
Every time the model generates a word, it's actually sampling from a probability distribution — not selecting the highest-probability option, but randomly choosing according to the distribution.
Specifically, the model outputs a probability distribution covering the entire vocabulary (typically containing 30,000 to 100,000 tokens), then controls the randomness of sampling through a parameter called Temperature. Higher temperature means lower-probability words have a greater chance of being selected, making output more creative but less controllable; lower temperature means the model tends to pick the highest-probability word, making output more conservative but also more boring.
For example, ask "Who won the men's 100m at the 1996 Atlanta Olympics?" The correct answer is Donovan Bailey. But Carl Lewis also ranks fairly high in the probability distribution (he did win gold in 1984 and 1988, and his name is highly associated with "Olympics 100m"), so the model has a certain probability of giving the wrong answer. This probability is never zero.
Set temperature to zero, forcing only the highest-probability word? The generated content becomes mechanical and uncreative, and in many scenarios the highest-probability word itself is wrong — because if incorrect information appears frequently enough in training data, its probability can exceed that of correct information.
The fundamental logic is: probabilistic generation mechanism + imperfect training data + a mandatory output objective function — with all three factors present simultaneously, hallucinations cannot be eliminated.
Classification System for AI Hallucinations
Different types of hallucinations have different sources and require different mitigation approaches. Academia typically classifies them along two dimensions:
Dimension 1: Factuality Hallucinations vs. Faithfulness Hallucinations
- Factuality Hallucinations: Generated answers don't match external real-world facts. For example, when asked how tall Mount Everest is, the model answers 9,100 meters.
- Faithfulness Hallucinations: Generated answers don't match user-given constraints or context. For example, you tell it to write only three points and it writes five; you say don't mention pricing and it leads with pricing.
The solution paths for these two types are completely different: factuality issues are addressed through better knowledge injection (RAG, retrieval, fact-checking); faithfulness issues are addressed through stronger instruction-following capabilities and constraint encoding.
Dimension 2: Omission Hallucinations vs. Fabrication Hallucinations
- Omission Hallucinations: The model clearly saw correct information but omitted it in the output. For example, given an entire contract with a liability disclaimer clause, it simply doesn't mention it in the summary. The root cause is more often an attention mechanism issue — the model assigned weights to the wrong positions in long text. The Self-Attention mechanism in the Transformer architecture is responsible for deciding which positions in the preceding context each position should "attend to." When input text is very long, attention weights get diluted, and certain key pieces of information may receive extremely low attention weights, causing the model to "turn a blind eye" during output generation. This is also why even as context windows grow larger (from 4K to 128K and beyond), models still miss information in the middle of long documents — researchers call this the "Lost in the Middle" phenomenon.
- Fabrication Hallucinations: The model didn't see something but added it to the output anyway. For example, asked to analyze a stock, it invents a non-existent news story as supporting evidence. The root cause is more often spurious correlations in training data — certain words frequently co-occur with others, and the model assumes they have a causal relationship.
A Pragmatic Mitigation Framework: How to Reduce AI Hallucination Risk
From a theoretical standpoint, completely eliminating hallucinations is impossible. But we can establish a pragmatic set of countermeasures:
Strategy 1: Add RAG (Retrieval-Augmented Generation) for Fact-Sensitive Tasks
Don't let the model answer from memory. Instead, first retrieve authoritative materials, feed them to the model along with the question, and let it answer in an "open-book environment." This is currently the most effective means of suppressing factuality hallucinations.
RAG (Retrieval-Augmented Generation) works in three steps: First, convert the user's question into a vector representation and perform semantic search in an external knowledge base to find the most relevant document fragments. Second, assemble the retrieved document fragments as context together with the original question into a prompt. Third, the model generates an answer based on these "evidence materials." This way, the model no longer needs to rely entirely on "memories" stored in its parameters and can instead reference real-time, authoritative external information. Typical RAG systems use vector databases (such as Pinecone, Milvus, Weaviate) to store document embeddings, paired with embedding models (such as OpenAI's text-embedding series) for semantic matching. It's important to note that RAG isn't a silver bullet — if the retrieved documents themselves contain errors, or if retrieval fails to hit the correct documents, hallucinations can still occur.
Strategy 2: Add an Independent Evaluation Layer for Multi-Step Tasks
Don't let an Agent judge its own performance. Use an independent Evaluator to verify critical outputs. In multi-step tasks, set checkpoints at each stage to prevent error accumulation.
Strategy 3: Set Hard Boundaries for High-Risk Outputs
In healthcare, legal, financial, and similar scenarios, use System Prompts or output filtering rules to force the model to say "I'm not sure" when uncertain, rather than guessing an answer. Better to under-answer than to answer nonsense.
Strategy 4: Cultivate Verification Habits on the User Side
This is the most easily overlooked point. Many real-world losses caused by AI hallucinations aren't because the model lied, but because people believed it without question. For critical information, always perform secondary verification: check with a search engine, look through internal documents, cross-reference authoritative sources.
Conclusion: A Mature Attitude Toward Coexisting with AI Hallucinations
One final point that might make some people uncomfortable: Hallucination isn't a defect of the model — it's an innate characteristic of the language model technology paradigm. Just as internal combustion engines will always have heat loss and batteries will always have self-discharge — you can optimize it, suppress it, manage it, but you cannot eliminate it.
A truly mature attitude toward AI usage isn't hoping the model never makes mistakes, but assuming it will make mistakes and then building mechanisms to catch errors before they cause real damage.
Three closing statements:
- Hallucinations occur not because the model is deliberately deceiving you, but because it's trained to always provide an answer — when it doesn't know the answer, it can only guess based on probability.
- Hallucinations come in different types: omission and fabrication have different root causes, and Agent-based versus pure text generation have different root causes too. You can't summarize everything with a single term.
- The best way to address hallucinations isn't pursuing a 0% hallucination rate (that's impossible), but designing a system where even when hallucinations occur, they don't become the last line of defense — because the final judgment should always rest with humans.
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.