Demystifying Transformer: A Word-Continuation Function, Deconstructed

Transformer is essentially a complex word-continuation function decomposed into three efficient modules
Transformer's core purpose is implementing a "word continuation" function — input a text sequence, predict the next word. Since directly training such a complex function is infeasible, it's decomposed into three modules: Embedding (words to high-dimensional vectors with positional encoding), Transformer Block (fusing inter-word information via multi-head attention), and Probabilities (outputting next-word probability distributions). Transformer's key advantage is its Scaling Law property — the larger the scale, the stronger the capability.
The Core Idea of Transformer: A Word Continuation Game
The essential purpose of Transformer is remarkably simple — find a function that takes a sequence of text as input and outputs the next word. Once you have this function, feed the output back as input, repeat, and you can continuously generate text. This generation method is called Autoregressive generation, and it's the paradigm used by all GPT-series models.
But here's the problem: language has virtually infinite combinations, making this function extraordinarily complex. Just brute-force train a massive neural network? With current human data and compute, that's not feasible.
The answer is decomposition.
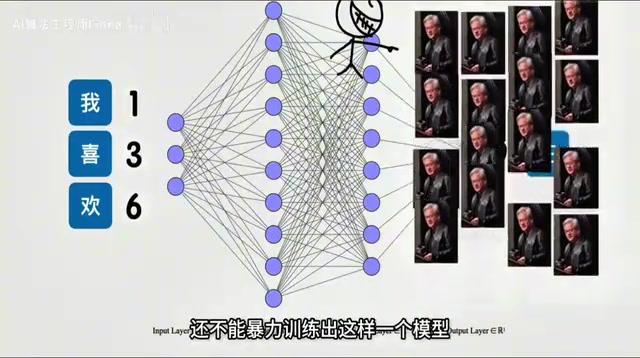
The Three Major Modules of Transformer Architecture
Through continuous exploration, researchers discovered that decomposing this "word continuation function" into the Transformer architecture yields excellent training results. It breaks down into three major components:
Embedding: Converting Words to Vectors
Convert each word from a number (an index) into a vector (a group of numbers), increasing the information dimensionality.
Specifically, input text first goes through a tokenizer to be split into a token sequence, where each token corresponds to an integer index in the vocabulary. Then, through a trainable embedding matrix, each index is mapped to a high-dimensional vector (e.g., GPT-3 uses 12,288 dimensions). Since Transformer doesn't process sequences step-by-step like RNN and thus lacks inherent awareness of order, Positional Encoding must be added to inject position information for each word, letting the model know "who comes before whom."
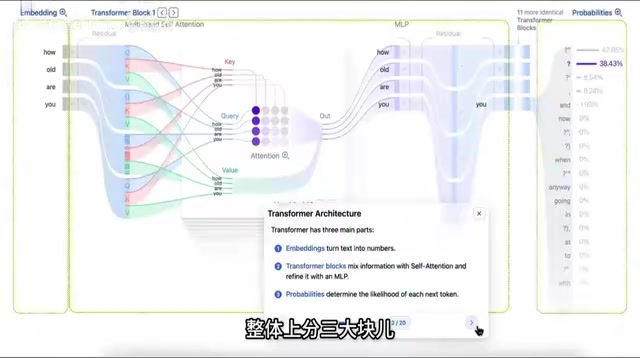
Transformer Block: Fusing Information Through Attention
Through the attention mechanism, each word vector incorporates information from other word vectors, achieving "mutual information sharing." The output remains word vectors with the same structure.
The core of attention is the Query-Key-Value structure: each word generates three vectors — Query (Q), Key (K), and Value (V). The dot product of Q and K computes relevance weights between words, which are then used to take a weighted sum of V. Multi-Head Attention runs this process in parallel multiple times, allowing the model to simultaneously attend to different types of semantic relationships (such as syntactic relationships, semantic similarity, etc.). Transformer Blocks are typically stacked dozens or even hundreds of layers deep, extracting increasingly abstract features layer by layer.
Probabilities: Outputting Next-Word Probabilities
The model produces scores (logits) matching the vocabulary size, then converts them into probabilities based on temperature, top-k, and other parameters to determine the next word.
Logits are the raw output of the final linear transformation, with dimensions equal to the vocabulary size (e.g., GPT-3's vocabulary is about 50,000 tokens). The Temperature parameter controls how sharp the probability distribution is: temperature near 0 means the model almost always picks the highest-scoring word, while higher temperatures lead to more random, "creative" choices. Top-k sampling restricts selection to only the k highest-probability words, preventing absurd outputs. These are all inference-time decoding strategies that don't affect training.
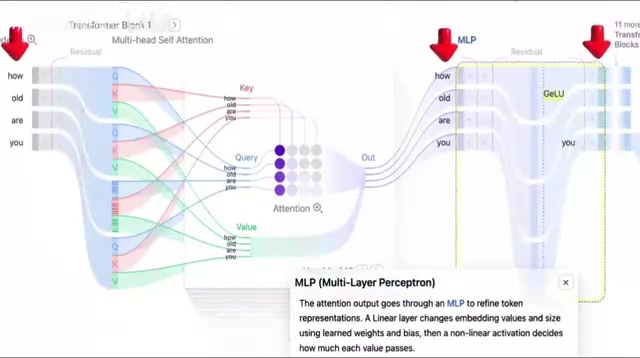
Additionally, training techniques like residual connections, layer normalization, and Dropout are distributed throughout. Residual Connections add each layer's input directly to its output, solving the vanishing gradient problem in deep networks; Layer Normalization stabilizes the numerical range across layers during training; Dropout randomly deactivates some neurons during training to prevent overfitting.
Why Transformer Specifically?
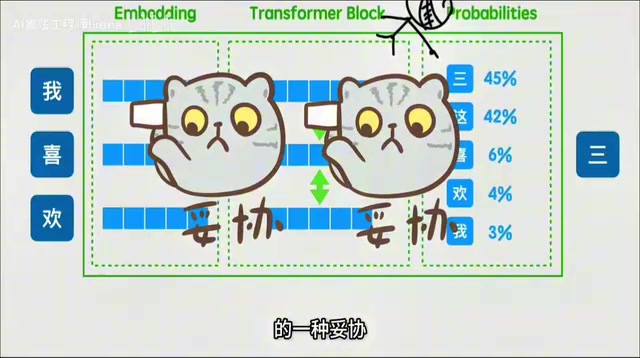
Many beginners wonder: why does it have to be Transformer?
The answer is actually quite simple: If it trains well and exhibits Scaling Law behavior, it's a good model. Transformer is essentially humanity's compromise given insufficient compute and data — with unlimited compute, you could just train one massive neural network end-to-end.
Scaling Law is an important discovery published by OpenAI in 2020: Transformer model performance follows a predictable power-law relationship with parameter count, data volume, and compute. As long as you keep increasing scale, model capabilities improve smoothly and predictably. This property is what sets Transformer apart — earlier architectures like RNN and LSTM could also handle sequences, but showed diminishing returns when scaled up, unable to "get stronger just by adding resources" like Transformer. This is the theoretical basis for GPT scaling from 117 million parameters all the way to 175 billion.
When we get lost in model details, we often overlook that the input-output task itself is very simple and clear. This perspective is crucial for understanding deep learning models.
Key Takeaways
- Transformer's essential purpose is to implement a word continuation function: input a text sequence, output the probability of the next word
- The architecture has three parts: Embedding (words to vectors + positional encoding), Transformer Block (multi-head attention for information fusion), Probabilities (output probabilities)
- Transformer is a decomposition of "directly training one big function" — essentially a compromise for insufficient compute
- The standard for a good model: trainable to good performance with Scaling Law properties — the larger the scale, the more predictably stronger it becomes
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.
 Deep Dives
Deep DivesMCP and A2A Protocols Explained: The USB Era of Agent Interoperability
A deep dive into MCP (Model Context Protocol) and A2A (Agent-to-Agent Protocol) — their architecture, core features, and how they work together to enable plug-and-play agent interoperability.