AI Large Model Learning Roadmap Breakdown: Three Stages from Application Development to Model Fine-Tuning
A three-stage AI learning roadmap analyzed: from LangChain apps to RAG/Agent development to LoRA fine-tuning.
This article dissects a widely shared AI large model learning roadmap divided into three stages: application development with Python/LangChain/vector databases, RAG and Agent development for real business scenarios, and LoRA model fine-tuning for vertical domains. While the technical stack choices are sound and well-structured, the 90-day timeline is unrealistic—six months to a year is more practical for most learners.
A Widely Circulated AI Learning Roadmap
Recently, an AI large model learning roadmap—allegedly compiled by multiple industry professionals—has gained attention on Bilibili. This roadmap compresses the learning cycle into 90 days, divided into three progressive stages, aiming to help absolute beginners or traditional developers transition into large model technical roles.
Setting aside the marketing rhetoric, the technical stack choices in this roadmap genuinely reflect the mainstream demands in the current large model application development field. Let's break down each stage's core content and analyze its merits and limitations.
Stage One: AI Application Development Fundamentals (Python + LangChain + Vector Databases)
Core Technical Stack Analysis
The first stage focuses on four modules: Python fundamentals, LangChain framework, Prompt Engineering, and Vector Databases. The ultimate goal is to independently build an industry-specific intelligent Q&A system.
The logic behind this combination is clear:
-
Python is the universal language for large model development—virtually all mainstream frameworks offer Python as their primary supported language. Python became the de facto standard for AI and large model development thanks to over two decades of ecosystem accumulation in scientific computing and machine learning. From early libraries like NumPy and SciPy, to TensorFlow and PyTorch, and now the Transformers library and various large model inference frameworks, Python has always been the first-class citizen language. Its dynamic typing, concise syntax, and rich package management ecosystem (pip/conda) significantly lower the development barrier, while interactive development environments like Jupyter Notebook make experimental AI development highly efficient. For large model application development, Python is used not only for API calls and workflow orchestration but also for data preprocessing, model evaluation, service deployment, and other end-to-end tasks.
-
LangChain is currently the most mainstream orchestration framework for large model applications, responsible for connecting various components together. Open-sourced by Harrison Chase in October 2022, LangChain quickly became the most prominent orchestration framework in the large model application development space. Its core design philosophy decomposes large model applications into composable modules—including model calls (LLMs/ChatModels), prompt templates (PromptTemplate), output parsers (OutputParser), chains (Chain), memory (Memory), tools (Tool), and agents (Agent). Developers can combine these components like building blocks to create complex application workflows. LangChain also provides supporting infrastructure like LangSmith (debugging and monitoring platform) and LangServe (deployment tool). However, it's worth noting that LangChain faces fierce competition from alternatives like LlamaIndex, Semantic Kernel, and Dify, and its API changes frequently. The community has also voiced considerable criticism about its over-abstracted design. When learning, focus on core concepts rather than memorizing APIs.
-
Prompt Engineering determines whether you can effectively communicate with models and directly impacts output quality. Prompt engineering goes far beyond simply writing instructions for models—it has evolved into a systematic methodology encompassing multiple proven technical paradigms: Zero-shot prompting, Few-shot prompting, Chain-of-Thought (CoT), Self-Consistency, Tree-of-Thought, ReAct (Reasoning + Acting), and more. Each technique suits different task scenarios—for example, Chain-of-Thought prompting significantly improves accuracy on math and logical reasoning tasks by guiding the model through step-by-step reasoning. Additionally, prompt engineering involves practical knowledge such as System Prompt design, output format control, hallucination suppression strategies, and safety measures (preventing prompt injection attacks).
-
Vector Databases (such as Milvus, Pinecone, etc.) are the infrastructure for semantic retrieval. The core capability of vector databases is efficient storage and retrieval of high-dimensional vectors. In large model applications, text is first converted into high-dimensional vectors (typically 768 or 1536 dimensions) through embedding models (such as OpenAI's text-embedding-ada-002 or open-source BGE series), where distance relationships in mathematical space reflect semantic similarity between texts. Vector databases use approximate nearest neighbor search algorithms (such as HNSW, IVF, PQ) to achieve millisecond-level similarity retrieval. Popular choices include: Milvus (open-source, supports large-scale distributed deployment), Pinecone (fully managed cloud service), Weaviate (supports hybrid search), Qdrant (written in Rust, excellent performance), and Chroma (lightweight, suitable for prototyping). The choice depends on data scale, deployment method, and query performance requirements.
The Real Job Market Situation
The roadmap mentions a salary range of 15-25K RMB for this stage. Looking at the recruitment market, AI application development positions indeed represent the highest-demand direction currently. However, note that basic LangChain calling ability alone is unlikely to command high salaries. Employers value whether you can build truly usable products for specific business scenarios, not just run a demo.
Stage Two: RAG (Retrieval-Augmented Generation) and Agent Development
RAG: Giving Large Models Their Own Knowledge Base
RAG (Retrieval-Augmented Generation) is one of the most mature technical solutions for deploying large models in production. Its core approach: first retrieve relevant content from a private knowledge base, then provide the retrieved results as context for the large model to generate answers.
The complete RAG technical pipeline contains two core phases: the indexing phase and the query phase. During the indexing phase, raw documents go through three steps—loading, chunking, and embedding—before being stored in a vector database. Chunking strategy directly impacts retrieval quality; common methods include fixed-length chunking, semantic-based chunking, and recursive character chunking. During the query phase, the user's question is similarly converted to a vector, relevant document fragments are found through similarity search, and these fragments are combined with the original question to construct a prompt sent to the large model for answer generation.
RAG's two major advantages:
- Solves knowledge timeliness issues—the model is no longer limited by training data cutoff dates
- Significantly reduces hallucinations—answers are based on real documents rather than the model's "imagination"
Advanced RAG techniques also include: Query Rewriting, hybrid retrieval (combining keyword and semantic search), Reranking, Multi-hop Retrieval, and other optimization methods. The combined application of these techniques is the key differentiator between junior and senior RAG engineers.
Mastering RAG means you can build private knowledge base systems for enterprises, with broad applications in customer service, document management, internal Q&A, and other scenarios.
Agent: From Passive Answering to Active Execution
Agent (intelligent agent) is the hottest technical direction in recent years. Unlike traditional Q&A modes, Agents enable large models to autonomously plan tasks, invoke tools, and execute operations. For example, an Agent can automatically analyze data, generate reports, and send emails—all without human intervention.
The core Agent architecture typically contains four key modules: Perception (receiving user input and environmental information), Planning (decomposing complex tasks into sub-task sequences), Tool Calling (executing specific operations like search, code execution, API calls, etc.), and Memory (maintaining short-term and long-term context). Since 2023, the Agent field has experienced explosive growth: Stanford's Generative Agents paper demonstrated 25 AI agents engaging in autonomous social behavior in a virtual town; the AutoGPT project briefly became the fastest-growing open-source project on GitHub; OpenAI launched Function Calling and the Assistants API to provide native support for Agent development. Current mainstream Agent frameworks include AutoGen (Microsoft), CrewAI (multi-Agent collaboration), and MetaGPT (multi-role software development). Multi-Agent collaboration is a major trend in 2024, with the paradigm of multiple specialized Agents cooperating to complete complex tasks maturing rapidly.
Placing RAG and Agent as the core of Stage Two is reasonable—these two skills directly determine whether you can handle complex requirements in real business scenarios.
Stage Three: LoRA Model Fine-Tuning and Private Deployment
Key Points of Parameter-Efficient Fine-Tuning
Stage Three focuses on model fine-tuning and deployment, with emphasis on LoRA and PEFT parameter-efficient fine-tuning techniques. The core value of these techniques: you don't need to train a large model from scratch—you only need to make targeted adjustments on an existing model with a small amount of data to achieve excellent performance in specific domains.
LoRA (Low-Rank Adaptation) was proposed by Edward Hu and colleagues at Microsoft Research in 2021. Its core idea is based on a key hypothesis: the weight update matrices during fine-tuning exhibit low-rank properties. Specifically, LoRA doesn't directly modify the original model's weight matrix W, but decomposes the weight update into a product of two low-rank matrices: ΔW = BA, where the rank of B and A is much smaller than the original matrix. For example, for a 4096×4096 weight matrix, LoRA might only need to train two 4096×8 matrices, reducing trainable parameters from approximately 16 million to about 65,000—a 99.6% reduction.
PEFT (Parameter-Efficient Fine-Tuning) is a unified framework from Hugging Face that integrates multiple parameter-efficient fine-tuning methods including LoRA, QLoRA (quantization + LoRA, further reducing VRAM requirements), Prefix Tuning, P-Tuning, Adapter, and more. QLoRA technology in particular makes it possible to fine-tune 65B parameter models on a single consumer-grade GPU (such as an RTX 4090 with 24GB VRAM), dramatically lowering the hardware barrier for fine-tuning.

The Scarcity of Vertical Domain Fine-Tuning Talent
The roadmap specifically mentions the demand for fine-tuning talent in vertical domains like healthcare, legal, and finance—a point worth taking seriously. General-purpose large models often lack precision in specialized domains, and vertical domain fine-tuning requires both technical capability and industry knowledge. Such compound talent is genuinely scarce.
The core challenge in vertical domain fine-tuning lies not in the technology itself, but in acquiring and processing high-quality domain data. Take healthcare as an example: training data involves electronic medical records, medical literature, clinical guidelines, etc. This data often faces privacy compliance requirements (such as HIPAA and personal information protection laws), difficulties in professional terminology annotation, and inconsistent data formats. The legal domain faces challenges like extremely high precision requirements for statutory text and significant differences across legal systems in different jurisdictions. Financial domain data is highly time-sensitive and confidential. Therefore, vertical domain fine-tuning engineers need triple competencies: first, deep understanding of fine-tuning techniques (data mixing ratios, learning rate scheduling, overfitting prevention, etc.); second, domain expertise to evaluate model output quality; third, data engineering skills to design complete pipelines for data cleaning, annotation, and augmentation. This compound skill requirement is the fundamental reason such talent is scarce.
The corresponding salary range of 18-28K RMB is relatively reasonable, but top fine-tuning engineers earn far more than this—the key lies in your depth of understanding of specific industry data and business logic.
Rational Assessment: Is This Learning Roadmap Reliable?
What Deserves Recognition
This learning roadmap's technical stack selection and stage division are sound—progressing from the application layer to core capabilities to underlying fine-tuning, moving from shallow to deep, aligning with natural learning patterns. For beginners who don't know where to start, it provides a relatively clear directional reference.
What Requires Clear-Headed Thinking
However, several points must be acknowledged:
- The 90-day timeline is overly optimistic. For absolute beginners, Python fundamentals alone might take over a month. Completing all three stages realistically requires six months to a year.
- Completing the curriculum doesn't equal employment. Technical ability is just one threshold—project experience, business understanding, and engineering capabilities are equally important.
- Technology iterates extremely fast. New frameworks and paradigms emerge monthly in the large model space, and learning roadmaps need continuous updates. For example, LangChain's API underwent multiple major refactors over the past year—specific usage patterns learned today might need readaptation within months. Maintaining continuous awareness of technical community developments is more important than memorizing any fixed roadmap.
Overall, this roadmap can serve as a technical stack reference checklist, but never treat it as a shortcut manual. Learning in the AI large model field is fundamentally a long-term endeavor requiring sustained investment.
Related articles
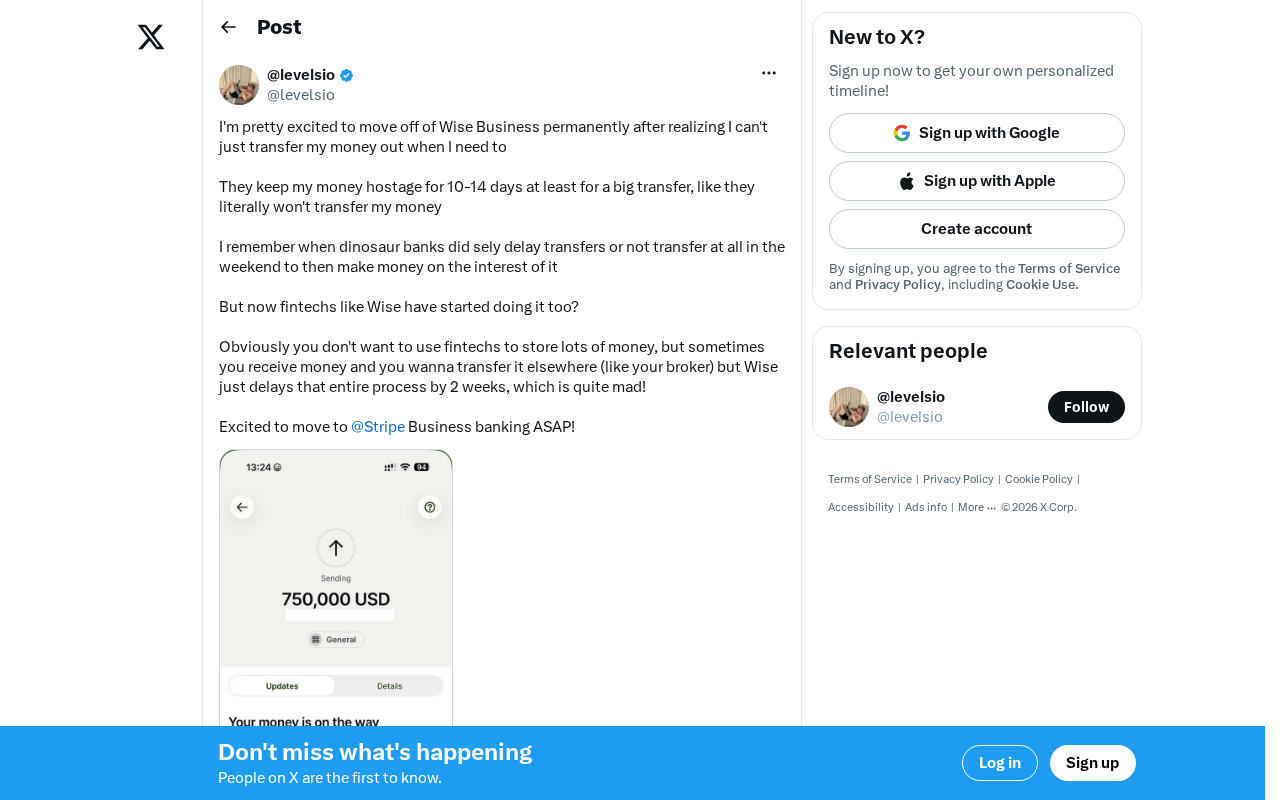
Wise Large Transfer Delayed Two Weeks: How Should Cross-Border Entrepreneurs Respond?
Wise Business users face 10-14 day delays on large transfers, sparking debate on whether fintech is repeating traditional banking mistakes. Analysis and practical tips for cross-border entrepreneurs.
Perplexity Partners with Intel: Local AI Models and Hybrid Inference Come to Laptops
Perplexity partners with Intel to bring local AI models and hybrid inference to Core Ultra Series 3 laptops. We break down the architecture, NPU capabilities, and the cloud-to-edge AI trend.

AI Agent Development: A Complete 6-Week Systematic Learning Roadmap
A 6-week systematic learning roadmap for AI Agent development, covering core architecture, ReAct principles, multi-agent collaboration, RAG integration, and deployment.