AICodeSwitch Routing Management Explained: The Core Mechanism Behind Intelligent Request Distribution
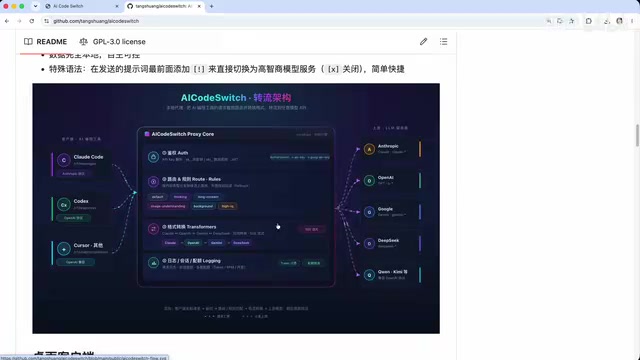
How AICodeSwitch intelligently routes AI coding requests across multiple LLMs based on configurable rules.
This article explains AICodeSwitch's routing management system, which intelligently distributes requests from AI coding tools like Claude Code and Cursor to different LLM providers. It covers the six request types (compact, image understanding, high-IQ mode, long context, thinking mode, and model override), overage limits for cost control, intelligent failover for seamless degradation, and configuration management mechanisms.
Why Do We Need Routing Management?
When using AI coding tools like Claude Code, Codex, or Cursor, we often run into a practical problem: different task scenarios require different LLMs. Image understanding needs a model that supports multimodal input, long-context conversations need a model with a large enough context window, and cost control calls for a cheaper model. AICodeSwitch's routing management feature is designed precisely to solve this "intelligent distribution" problem.
This article provides an in-depth look at the architecture, rule configuration, and real-world use cases of AICodeSwitch's routing management, helping you understand how this core feature works.
Architecture Overview: The Role of Routing in the Middle Layer
AICodeSwitch's overall architecture can be understood in three layers:
- Left side: AI coding tools (Claude Code, Codex, Cursor, etc.)
- Middle: AICodeSwitch (routing management + format conversion + logging & analytics)
- Right side: Upstream LLM providers (DeepSeek, GLM, Volcengine, etc.)
The core responsibility of routing management is: identify the request type → match rules → distribute to the appropriate upstream model. Think of it as an intelligent dispatch center — requests from coding tools first pass through the routing module for "inspection," where the router determines which model should handle the request based on preset rules, then returns the result to the coding tool.
Compared to similar tools (like CC Switch), AICodeSwitch's core advantage lies in rule-based conditional distribution. CC Switch can only connect requests to a single provider, while AICodeSwitch can dynamically select different models based on request type, context length, usage frequency, and other conditions.
Six Request Types: The Matching Logic Behind Routing Rules
The core of routing rules is "request type matching." AICodeSwitch has six built-in request types, each corresponding to a different use case:
Compact Conversation
Corresponds to the Compact command in Claude Code, used for conversation compression. When conversation history gets too long, the coding tool sends a compression request, and the router can distribute it to a lower-cost model for processing.
Image Understanding
This is one of the most intuitive use cases for routing management. When you send a message containing an image in Claude Code and want the LLM to understand the image content, the request falls under the "Image Understanding" type.
The key point is: models like DeepSeek and GLM don't support image understanding. Without routing distribution, sending such requests directly to these models would fail. By configuring an image understanding rule, you can automatically forward these requests to a multimodal-capable model (like Claude Sonnet), achieving the effect of "using DeepSeek as the primary coding model while automatically switching to Claude when images are involved."
High-IQ Mode
AICodeSwitch has a special built-in syntax: adding a specific marker (carbon sign marker) at the beginning of your prompt triggers High-IQ Mode.
The practical use case is: when you've been debugging with a regular model for a while without success, adding the marker to your message automatically routes the request to a top-tier model like Claude Sonnet 4. Once the problem is solved, you use the exit marker to switch back to the regular model, balancing effectiveness and cost.
Long Context
The router monitors the cumulative token count of the current session. When the context length exceeds a threshold, it automatically switches to a model that supports a larger context window. For example, GLM has a relatively small context window, while DeepSeek V4 supports 1M context. The router can automatically switch to DeepSeek as conversations grow longer, ensuring the conversation isn't interrupted by exceeding window limits.
Thinking Mode
Corresponds to request handling when Thinking mode is enabled. However, since most models default to thinking mode when connected to coding tools, scenarios requiring separate configuration are relatively rare.
Model Override
Directly matches the model name sent by the coding tool and replaces it with a specified model. For example, Claude Code internally calls the Haiku model for lightweight tasks — you can configure a rule to replace Haiku requests with a cheaper DeepSeek model, further reducing costs. Note that model names (including version numbers and dates) may vary across versions, so you'll need to verify the exact model name in the logs.
Overage Limits and Intelligent Failover
Overage Limits: Granular Cost Control
Each routing rule can be configured with three types of limits:
- Token overage limit: Skips the rule once cumulative token usage reaches the cap
- Request count limit: e.g., 2 requests per minute — automatically switches to the next rule when exceeded
- Request rate limit: Controls request density within a given time period
These limits work in conjunction with provider-level limits — routing rule limits cannot exceed the provider's own quotas. When a rule triggers its limit, the request automatically matches the next rule of the same type in priority order.
Intelligent Failover: Seamless Degradation
This is an extremely practical feature in routing management. When multiple rules of the same type are configured, if the provider corresponding to the first rule goes down or times out, AICodeSwitch automatically forwards the request to the next rule. For users, the entire process is seamless — you won't see any errors in Claude Code; the response might just be slightly slower (since the system needs to first detect that the primary service is unavailable before switching to the backup).
Timeout configuration is also part of failover: you set a timeout duration, and if a rule's request response exceeds that time, the system treats it as a failure and automatically moves to the next rule.
Configuration File Override and Activation Mechanism
AICodeSwitch's operation involves automatic configuration file management:
- When starting the service: Automatically backs up the original configuration files of Claude Code/Codex and overwrites them with new configurations
- When stopping the service: Automatically restores the backed-up original configuration files
- Modifications during runtime: Routing rule changes take effect immediately without restarting the coding tool
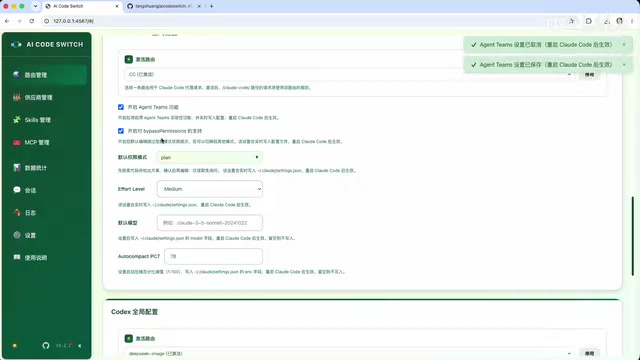
In the configuration panel, you can activate different routes for Claude Code and Codex separately, and configure parameters for the coding tools themselves, such as Agent Teams and Bypass Permissions (maximum permission mode that skips all confirmation steps). Note that while Bypass Permissions is convenient, it poses security risks — it's recommended to use it only within specific directories.
API Path Mapping: Extending to More Tools
AICodeSwitch also provides API path mapping to support third-party coding tools like Cursor and Trae. Simply configure the generated API path in the corresponding tool and select the route for that path to enjoy the same intelligent distribution capabilities.
It's worth noting that this interface can theoretically be used as a local general-purpose API service, but you need to be aware of providers' "coding plan restrictions." If a provider has coding plan restrictions enabled, non-coding requests may return errors. In such cases, you'll need to switch to a standard paid API (such as Volcengine Ark's paid endpoint) and disable the coding plan restriction option.
Summary
AICodeSwitch's routing management is essentially a request strategy distribution system. By identifying request types, matching preset rules, and executing intelligent distribution, it enables developers to seamlessly leverage multiple LLMs within a single coding tool. Whether it's automatic switching for image understanding, smooth transitions for long contexts, or cost control and failover degradation, routing management provides flexible and practical solutions. For developers who heavily use AI coding tools, understanding and making good use of routing management can significantly improve development efficiency and cost-effectiveness.
Related articles
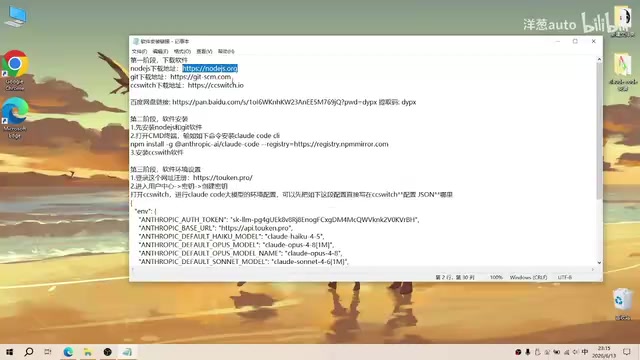
Complete Guide to Installing Claude Code CLI in China: Four Simple Steps
Step-by-step guide to installing Claude Code CLI in China using Node.js, Git, CC Switch, and an API relay service to bypass Anthropic's access restrictions.
The Compute Crisis: Why Google and Anthropic Are Paying SpaceX a Premium to Rent GPUs
Microsoft, Google, and Anthropic face severe compute shortages. Anthropic pays SpaceX $1B/month for GPUs. From TSMC capacity to HBM, storage, and power, the AI supply chain is in full crisis.
Mistral Le Chat Image Generation Review: Can It Replace Fable?
Mistral AI launches image generation in Le Chat, dubbed Le Chaton Fat. We analyze its capabilities, compare it with Fable, and explore the trend of AI chat platforms integrating image generation.