AI-Powered Research in Practice: From LLM Selection to Building Automated Workflows with N8N
Build a systematic AI research workflow to transform AI from a chat tool into a research collaborator.
Most researchers still use AI as a search engine, far from unlocking its full research potential. The real breakthrough lies in building a complete AI research system covering LLM selection, data analysis and programming automation, Zotero reference management with evidence-driven writing (solving AI hallucinations via RAG), Overleaf paper writing, local LLM deployment, multi-model collaboration, and N8N automated workflows — transforming AI from a passive tool into an intelligent collaborator across the entire research pipeline.
The Real Challenge of AI in Research: It's Not Just Chatting — It's Systematic Productivity
Large Language Models (LLMs) are reshaping the fundamental logic of research work, yet most researchers remain stuck at the stage of simple conversational use — treating ChatGPT as a smarter search engine, far from transforming AI into genuine research productivity.
The core challenge of research has never been "whether answers exist," but rather how to efficiently integrate information, continuously generate high-quality ideas, and rapidly turn research concepts into publishable results. This is precisely the pain point that fragmented use of AI tools cannot solve.
Recently, a systematic AI research course has attracted widespread attention. Built around the core philosophy that "AI is not just a tool, but a research collaborator," it covers the complete pipeline: LLM applications, data analysis, automated programming, Zotero reference management, Overleaf scientific writing and visualization, local LLM deployment, multi-model collaboration, N8N automated workflows, and even Seedance2 research video generation. Let's break down the key components of this methodology one by one.
LLM Selection: Which Model for Which Research Scenario
Developing a "Model Selection Mindset" Matters More Than Picking the "Best Model"
The first chapter focuses on comparing the capability boundaries of mainstream LLMs, covering ChatGPT, Claude, Gemini, DeepSeek, and others. Large Language Models (LLMs) are deep learning models based on the Transformer architecture, pre-trained on massive text datasets. The differences between models stem from core design choices including training data scale and quality, parameter count, alignment strategies (such as RLHF — Reinforcement Learning from Human Feedback), and context window length. Understanding these underlying technical differences enables evidence-based selection decisions in research scenarios, rather than relying on subjective impressions or leaderboard scores.
For researchers, the key isn't finding the "strongest" model, but understanding how different LLMs vary across dimensions like information comprehension, knowledge augmentation, and reasoning capability — then making optimal choices for specific scenarios.

Some typical selection guidelines:
- Claude: Uses Constitutional AI for alignment, excels at long-text analysis and academic writing, with a context window up to 200K tokens — ideal for deep paper reading and paragraph drafting
- Gemini: Natively supports multimodal input (text, images, video, code), leveraging Google's ecosystem and search index for unique advantages in information retrieval and multimodal understanding
- DeepSeek: Achieves near-frontier model performance at lower inference costs through Mixture of Experts (MoE) architecture, offering exceptional cost-effectiveness for Chinese-language research contexts — well-suited for daily use by researchers in China
- ChatGPT: Well-balanced overall capabilities with a rich plugin ecosystem; the GPT-4o series delivers stable performance in multi-task switching scenarios
The course emphasizes a core principle: Researchers need to develop a model selection mindset rather than blindly relying on a single tool. It also introduces platform-level tools like Google AI Studio and NotebookLM to help users build their own personalized automated research systems.
Data Analysis and Programming Automation: Making LLMs Your Computational Assistants
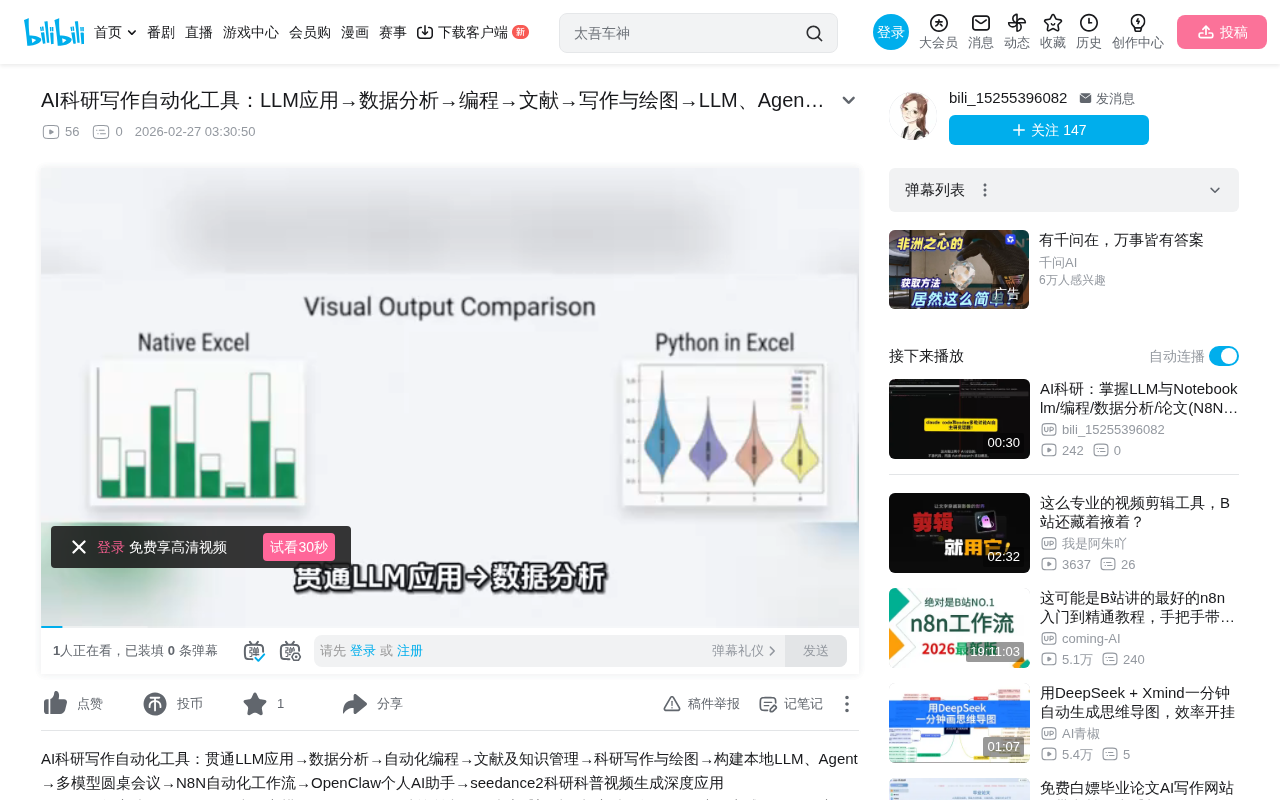
LLM + Excel: Driving Data Processing with Natural Language
Research data analysis is often the most time-consuming phase. The course demonstrates how to combine LLMs with Excel, driving data processing through natural language instructions — directly describing requirements in plain language to manipulate cells, turning Excel into a powerful research data analysis tool. Even without mastering complex formulas or VBA, you can efficiently complete data cleaning, statistical analysis, and visualization.
LLM + Python: Achieving Computational Automation Even Without Coding Experience
The course positions its Python programming section very clearly:
- For non-coders: Use LLMs to turn Python into a research productivity tool — run complete data analysis pipelines from scratch
- For experienced coders: Use LLMs to reach a new level of programming efficiency, accelerating everything from code generation and debugging to optimization
This "AI-assisted programming" approach essentially treats LLMs as real-time coding assistants that participate throughout the research computation pipeline. Current mainstream AI coding tools (such as GitHub Copilot, Cursor, etc.) have already demonstrated that LLMs can understand computational requirements described in natural language, automatically generate corresponding Python code, and iteratively refine it through interactive debugging. For researchers who need to process large volumes of experimental data, run statistical models, or perform simulations, the efficiency gains are substantial.
Reference Management and Evidence-Driven Writing: Eliminating AI Hallucinations
From "Summarizing Literature" to "Traceable, Evidence-Based Reasoning"
The course centers on deep integration of Zotero, NotebookLM, and LLMs, building an intelligent reference management and evidence-driven research writing system. The core philosophy is: AI should not just summarize literature for you, but conduct traceable analysis and writing grounded in evidence.
The biggest risk of traditional AI-assisted writing is the "hallucination" problem — models may generate content that appears plausible but lacks factual basis. AI hallucination stems from the LLM's generation mechanism: the model is fundamentally performing next-token probability prediction, optimizing for linguistic coherence rather than factual accuracy. In research writing, typical hallucination manifestations include fabricating non-existent citations, inventing experimental data, and misattributing research conclusions.
The evidence-driven approach essentially adopts the technical paradigm of Retrieval-Augmented Generation (RAG) — retrieving relevant evidence from a trusted knowledge base (i.e., the researcher's own reference library) before generation, enabling the model to reason and write based on real literature. This requires every argument to be traceable to specific source literature, fundamentally improving the reliability and academic rigor of AI-assisted research writing.
Building a Compounding Research Knowledge System with Obsidian
The course further expands its scope to research knowledge management, using the combination of Obsidian + NotebookLM + LLM to build a knowledge system that accumulates over time and compounds in value.
Zotero is an open-source academic reference management tool that supports automatic paper metadata extraction, full-text PDF storage, tag-based classification, and citation format generation. Obsidian is a bidirectional-linking note system based on local Markdown files, with a core design philosophy of being a "second brain" — weaving fragmented notes into a networked knowledge structure through Backlinks and knowledge graphs. When the two are combined with LLMs, advanced capabilities become possible: automated literature summary generation, cross-paper thematic clustering, research gap identification, and more — transforming passive literature reading into an active knowledge construction process.
The value of this methodology lies in the fact that research is not a one-off project, but a continuous accumulation and iteration of knowledge. A good knowledge management system turns every past reading session and thought into an asset for future research.
End-to-End Research Writing and Visual Communication
Overleaf + LLM: Boosting Efficiency Across the Paper Writing Pipeline
The course focuses on combining Overleaf with LLMs, covering the complete research paper writing workflow — from structuring the paper and drafting paragraphs to language polishing, with LLMs playing a practical role at every stage. Overleaf is an online collaborative writing platform based on LaTeX that has become the de facto standard for STEM paper typesetting. By integrating LLMs into the Overleaf workflow, researchers can describe desired formulas, tables, or chart formats in natural language and have AI automatically generate the corresponding LaTeX code, dramatically lowering the technical barrier to typesetting.
Research Figures and Academic Posters: A Picture Is Worth a Thousand Words
From paper illustrations to academic poster design, even those without design or illustration skills can produce professional-grade research visuals with AI tools. This is crucial for paper submissions and academic conference presentations — quality figures often directly shape a reviewer's first impression.
Local Deployment, Multi-Model Collaboration, and N8N Automated Workflows
Local LLM Deployment: An Essential Solution for Data Privacy and Offline Use
For research scenarios involving sensitive data or requiring offline access, local LLM deployment is an indispensable option. Local deployment typically relies on model quantization techniques (such as 4-bit/8-bit quantization in GGUF format) to lower hardware requirements, enabling models with 7B–70B parameters to run on consumer-grade GPUs or even CPUs. Mainstream local deployment solutions include Ollama (one-click deployment and management of local models), LM Studio (graphical interface), and vLLM (high-performance inference engine).
The course covers how to set up efficient local LLM services while building a dedicated research AI plugin system to ensure data privacy. For research scenarios, the core value of local deployment extends beyond data privacy protection to include: no API call cost limitations, the ability to fine-tune or customize RAG for specific domains, and stable availability in network-restricted environments.
Multi-Model Collaboration: Assembling an AI "Research Team"
The course introduces the concept of a multi-model collaborative research system — instead of relying on a single model, multiple AI models each take on specialized roles and work in concert. For example, one model handles literature retrieval, another performs data analysis, and yet another handles writing and polishing. This architecture mirrors the microservices design philosophy in software engineering: each model serves as an independent "service" with specific responsibilities, coordinated through a unified orchestration layer. This "AI team" approach represents the cutting edge of AI-assisted research and is a practical application of current Multi-Agent system research.
N8N Automated Workflows: The Ultimate Form of Research Efficiency
N8N automated workflows represent the culmination of the entire course framework. N8N is an open-source, node-based workflow automation platform released under a fair-code license, supporting fully self-hosted deployment where users retain complete control over their data. Unlike commercial automation tools such as Zapier and Make, N8N's technical architecture is built on Node.js, using a visual drag-and-drop interface to chain different service nodes (such as API calls, database operations, LLM inference, file processing, etc.) into workflows in the form of Directed Acyclic Graphs (DAGs). N8N currently integrates over 400 service connectors and natively supports API calls to mainstream LLMs from OpenAI, Anthropic, and others.
Some typical research automation scenarios:
- Paper monitoring: Automatically track new paper publications in specific fields (e.g., via arXiv RSS or Semantic Scholar API) to stay on top of the latest developments
- Information extraction: Automatically extract key information and generate structured summaries, supporting batch processing of hundreds of papers
- Reference archiving: Automatically classify and archive literature into Zotero or Obsidian knowledge management systems with intelligent grouping based on topic tags
- Progress reports: Periodically auto-generate research progress reports, eliminating large amounts of repetitive work
This system-level automation is the key to how AI truly transforms research workflows — freeing researchers from repetitive labor so they can focus their energy on the tasks that genuinely require creativity.
From Chatting with AI to Doing Research with AI: Building Your Research Automation System
The value of this course lies not only in introducing numerous tools, but more importantly in providing a systematic AI research methodology. It answers a core question: How do you upgrade from "chatting with AI" to "doing research with AI"?
The answer is: Build a complete AI research system covering data analysis, programming automation, reference management, knowledge accumulation, paper writing, visual communication, and workflow automation. In this system, AI is no longer a passive tool that answers questions, but an intelligent collaborator that actively participates in the entire research process.
For researchers exploring AI applications in their work, the most important first step isn't learning every tool — it's shifting your mindset — from treating AI as a search engine to treating AI as a research partner. Once you begin examining your research workflow through a systematic lens, you'll discover that every stage has room for AI-driven optimization.
Key Takeaways
- The core of AI in research is not simple conversation, but building a complete system spanning data analysis, programming, reference management, writing, and automation
- Evidence-driven AI writing methods using the Zotero + NotebookLM + LLM combination leverage RAG technology to solve the AI hallucination problem, ensuring traceability in academic writing
- The multi-model collaboration philosophy assigns different LLMs to specialized roles, drawing on Multi-Agent system architecture and representing the frontier of AI-assisted research
- N8N automated workflows, as an open-source self-hosted platform, chain various AI tools into DAG-structured automated pipelines, achieving system-level automation of research processes
- The key to moving from "chatting with AI" to "doing research with AI" lies in a mindset shift — viewing AI as a research collaborator rather than a search tool
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.