10 Years of AlphaGo: Hassabis Returns to Korea to Reunite with Lee Sedol — How AI Transformed the Game of Go
AlphaGo at 10: how a Go-playing AI reshaped the game and charted the course toward general AI.
DeepMind founder Hassabis returned to Korea to mark AlphaGo's 10th anniversary, reuniting with Lee Sedol and playing Shin Jin-seo. This article revisits the 2016 match's technical breakthroughs, examines how AlphaGo revolutionized Go opening theory and training, and traces the decade-long AI evolution from AlphaGo to AlphaFold to large language models — arguing that AI amplifies human cognition rather than replacing it.
The Decade-Long Echo of AlphaGo
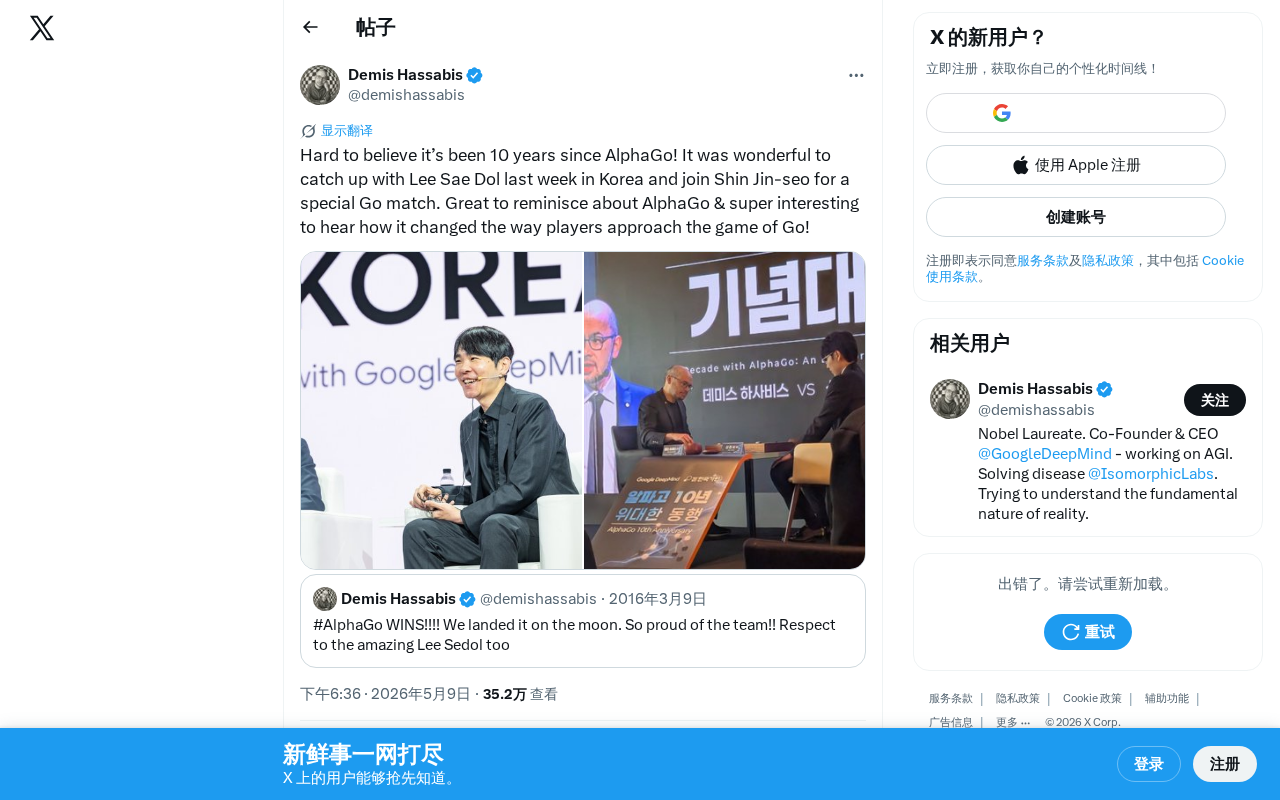
DeepMind founder Demis Hassabis recently reflected on social media: "Incredible that it's been ten years since AlphaGo!" Last week, he returned to South Korea to reunite with Lee Sedol — his opponent in that globally watched human-vs-machine showdown — and played a special game of Go against Shin Jin-seo, today's top-ranked player.
This was more than a simple reunion of old acquaintances. It was a profound look back at one of the most iconic moments in AI history.
The 2016 Match: Five Games That Changed the World
In March 2016, AlphaGo faced Lee Sedol in a five-game match in Seoul — one of the most symbolically significant events in the history of artificial intelligence. AlphaGo won 4–1, stunning the world. With its astronomically large number of possible game states (approximately 10^170), Go had long been considered the most formidable fortress for AI to conquer in the realm of board games.
To appreciate the magnitude of this achievement, consider Go's complexity. The board is a 19×19 grid with 361 intersections, each of which can be black, white, or empty. The theoretical state space is roughly 10^170 — a number that dwarfs the total number of atoms in the observable universe (approximately 10^80). By comparison, chess has a state space of about 10^47. This is precisely why brute-force search methods are completely useless in Go. Before AlphaGo, the strongest Go AIs could only reach an intermediate amateur level, with a vast chasm separating them from professional players.
AlphaGo achieved this breakthrough through an innovative technical architecture combining deep learning with Monte Carlo Tree Search (MCTS). On the deep learning side, it employed two key neural networks: a Policy Network that predicted the most likely next moves, dramatically narrowing the search space, and a Value Network that evaluated the win probability of a given board position. Monte Carlo Tree Search is an algorithm that evaluates decisions through random simulations — rather than exhaustively exploring every possibility, it uses statistical results from a large number of random games to determine which move is superior. AlphaGo was first trained through supervised learning on professional human game records, then continuously improved through self-play via reinforcement learning. It was this "learn from humans first, then surpass them" training paradigm that made AlphaGo's victory a milestone breakthrough for both deep learning and reinforcement learning.
During the match, Lee Sedol's "divine move" in Game 4 (move 78) is still regarded as one of the most brilliant flashes of human intelligence in the face of AI. Meanwhile, AlphaGo's move 37 in Game 2 was described by professional players as a move "beyond human understanding," completely overturning the Go community's traditional understanding of certain board patterns.
How AI Reshaped the Way Go Is Played
During this reunion, Hassabis specifically mentioned his fascination with learning how AlphaGo had changed the way players approach Go. These changes deserve a closer look.
A Complete Overhaul of Opening Theory
The most immediate impact of AlphaGo and its successor AlphaGo Zero was a comprehensive revolution in Go opening theory. Many opening moves that had been treated as established "joseki" (standard sequences) for centuries were shown to be suboptimal. Some of AI's preferred moves — such as the more frequent use of the "3-3 point invasion" and more flexible opening strategies — have been widely adopted by today's professional players.
Specifically, the "3-3 point" refers to the intersection of the third line from each edge in a corner of the board. In traditional Go theory, directly occupying the 3-3 point in the opening was considered overly conservative and cramped; professionals typically chose the star point (the 4-4 intersection) or the small knight's move (komoku) to begin the game. However, AlphaGo and its successors frequently played directly on the 3-3 point in the opening or invaded an opponent's star-point stone at the 3-3 point, often much earlier than traditional theory would suggest. AI analysis revealed that these moves, overlooked by human players for centuries, actually held subtle advantages in win rate. This discovery shook the Go world's long-held belief that "influence is more valuable than territory," prompting a reconstruction of the entire opening theory framework.
AlphaGo Zero, released in 2017, represented an even deeper technical breakthrough. Unlike the original AlphaGo, AlphaGo Zero relied on no human game data whatsoever. Starting solely from the rules of Go, it used pure self-play reinforcement learning to surpass all previous versions within just 40 days. This meant that AI could not only learn from human knowledge but could also discover knowledge from scratch on its own — even uncovering strategies that humans had never found in thousands of years. This result profoundly influenced the direction of AI research, demonstrating that in domains with well-defined rules, self-play can be more efficient than imitating humans.
A Transformation in Professional Training Methods
Today, virtually all top professional players use AI as a core training tool. Shin Jin-seo is an outstanding representative of this generation of "AI-trained" players and is widely considered the strongest Go player in the world today. Players improve their skills by playing against AI and analyzing its recommended moves — something completely unimaginable a decade ago.
Redefining What Constitutes "Correct Play"
The deeper change lies in a shift in mindset. The Go world traditionally emphasized "go theory" — a system of judgment based on experience and intuition. The arrival of AI made players realize that many principles long held as gospel actually contained biases. This has encouraged a new generation of players to explore the board's possibilities with a more open mind, reducing blind deference to authority and tradition.
From Go to General AI: DeepMind's Decade-Long Leap
Looking back over the past ten years, AlphaGo's significance extends far beyond Go itself. It validated the enormous potential of deep reinforcement learning and directly propelled DeepMind's breakthroughs in protein structure prediction (AlphaFold), mathematical reasoning (AlphaProof), and other fields. Hassabis himself was awarded the 2024 Nobel Prize in Chemistry for his contributions through AlphaFold.
The protein folding problem that AlphaFold tackled had been a grand challenge in biology for over 50 years. Proteins are composed of amino acid chains, and their three-dimensional folded structures determine their biological functions — but predicting 3D structure from an amino acid sequence is extraordinarily difficult. Traditional experimental methods (such as X-ray crystallography and cryo-electron microscopy) can take months or even years to determine a single protein structure. In 2020, DeepMind's AlphaFold2 achieved near-experimental accuracy in the CASP14 protein structure prediction competition. DeepMind subsequently released a database of predicted structures for over 200 million proteins, covering nearly all known proteins. This breakthrough is accelerating progress in drug discovery, enzyme engineering, disease mechanism research, and many other fields, and has been called "one of AI's most significant contributions to science" by Nature.
From AlphaGo to today's large language models and multimodal AI, artificial intelligence has undergone explosive growth over the past decade. The core proposition that AlphaGo proved — that AI can surpass humans in complex tasks requiring intuition and creativity — is now being validated in field after field.
This evolutionary path from specialized AI to general AI is worth noting. AlphaGo was a form of "narrow AI" or "specialized AI" — it could only excel at the specific task of playing Go and could not transfer its abilities to other domains. Today's large language models (such as the GPT series, Gemini, etc.) and multimodal AI systems demonstrate a degree of general capability, handling tasks ranging from text generation and code writing to image understanding and logical reasoning. Key technical foundations enabling this leap include: the attention mechanism revolution brought by the Transformer architecture (proposed by Google in 2017), the establishment of the large-scale pretraining paradigm, and the maturation of training methods like Reinforcement Learning from Human Feedback (RLHF). Notably, the reinforcement learning principles in RLHF share a direct lineage with AlphaGo's training methods — AlphaGo can be seen as an important precursor to today's general AI technology roadmap.
Lessons on the Human-AI Relationship: AI Didn't Kill Go
When Lee Sedol retired in 2019, he described AI as "an entity that cannot be defeated." But looking back a decade later, the relationship between humans and AI is not simply one of competition and replacement. The story of Go illustrates precisely that AI can serve as an amplifier of human cognition — it didn't kill Go but instead breathed new life into this ancient game. The global Go-playing population grew significantly after AlphaGo, and the competitive level of the game has reached unprecedented heights.
Hassabis's reunion with Lee Sedol is a warm footnote in the history of technology. It reminds us that in an era of rapidly advancing AI, the most groundbreaking moments are often also the most deeply human ones.
Key Takeaways
- DeepMind founder Hassabis returned to Korea to reunite with Lee Sedol and play against Shin Jin-seo, commemorating AlphaGo's 10th anniversary
- AlphaGo profoundly transformed professional Go's opening theory, training methods, and mindset — AI has become a core training tool for players
- The deep reinforcement learning path validated by AlphaGo drove DeepMind's subsequent breakthroughs in protein prediction, mathematical reasoning, and beyond
- The Go story shows that AI can serve as an amplifier of human cognition, not merely a replacement
- From AlphaGo to large language models, AI has undergone explosive growth over the past decade — evolving from domain-specific to general-purpose capabilities
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.