An Anthropic Employee's Firsthand Account: How Claude Fable 5 Evolved from Tool to Collaborative Partner
Anthropic insider reveals how Claude Fable 5 transformed AI interaction from command-execute to true collaboration.
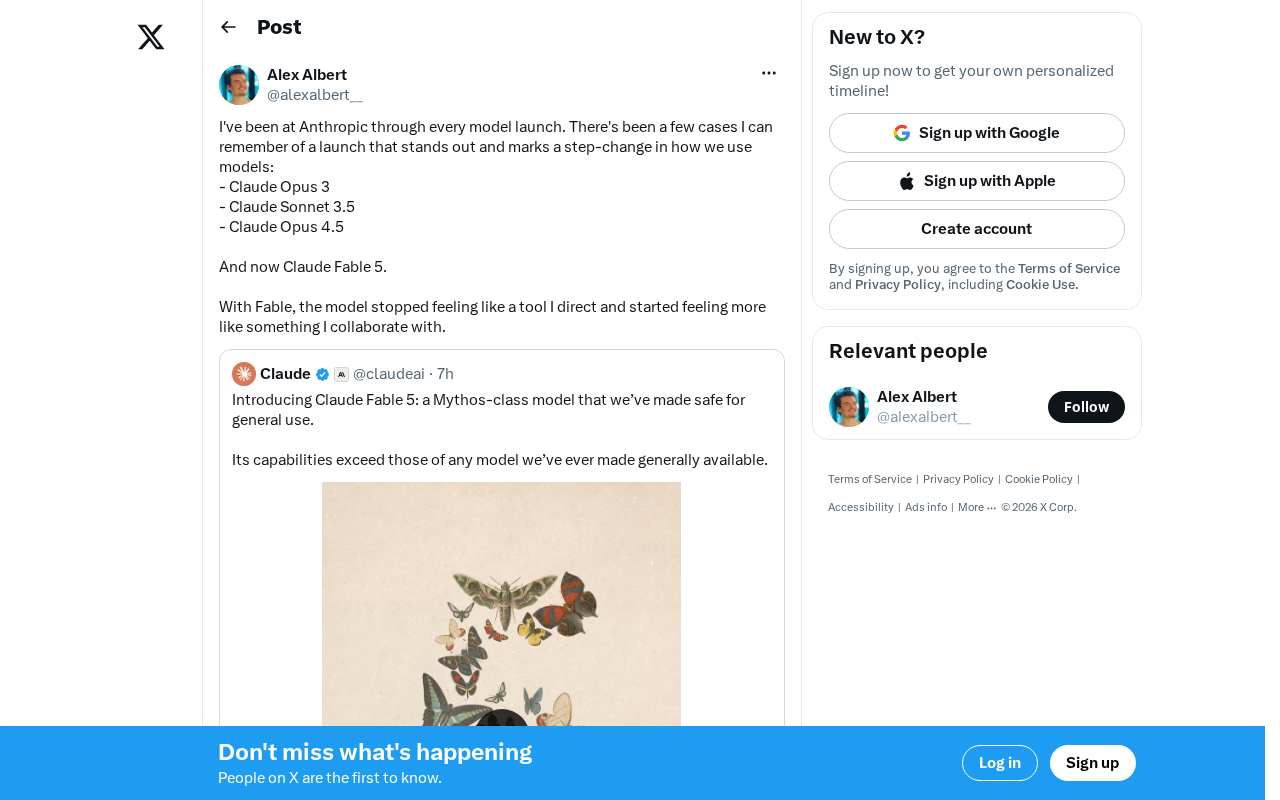
A veteran Anthropic employee identifies four milestone Claude releases—Opus 3, Sonnet 3.5, Opus 4.5, and Fable 5—noting that Fable 5 uniquely shifted the model from feeling like a directed tool to a collaborative partner. This signals a broader industry trend where AI competition moves beyond benchmark scores toward interaction experience quality.
A Veteran Anthropic Employee's Observations on Model Evolution
Recently, an employee who claims to have been present for every model release at Anthropic shared a thought-provoking reflection on Twitter. In his memory, only a handful of releases truly marked a "step-change" in how models are used—and the latest Claude Fable 5 is one of them.
Though brief, this assessment sketches a clear trajectory of AI capability evolution and reveals how Anthropic insiders genuinely feel about their own product iterations.
Four Milestones: From Claude Opus 3 to Claude Fable 5
The employee listed four releases he considers epoch-defining:
-
Claude Opus 3: As the flagship model of the Claude 3 series, Opus 3 stunned the industry upon release with its powerful reasoning capabilities and understanding of complex instructions. It was widely regarded as the first competitor to match or even surpass GPT-4 across multiple benchmarks. The Claude 3 series launched in March 2024 with three tiers—Haiku, Sonnet, and Opus—marking Anthropic's first multi-tier product strategy, offering differentiated options for various use cases and budgets. Opus 3's comprehensive lead on mainstream benchmarks like MMLU, HumanEval, and GSM8K signaled Anthropic's official ascent from challenger to first-tier competitor in the large model space.
-
Claude Sonnet 3.5: This mid-tier model's release was arguably Anthropic's "iPhone moment." Sonnet 3.5 delivered performance approaching or even exceeding Opus 3 at far lower cost and latency, fundamentally resetting user expectations around price-performance ratio and becoming one of the most popular coding assistants in the developer community. Sonnet 3.5's success revealed an important pattern in the large model industry: capability improvements don't necessarily require larger parameter counts. Through better training data ratios, improved architecture design, and more refined post-training alignment, mid-sized models can match or even surpass previous-generation flagships on real-world tasks. This phenomenon is known in the industry as the "model distillation effect" or "generational compression"—where a new generation's mid-tier model often reaches the level of the previous generation's top model.
-
Claude Opus 4.5: As Anthropic's largest model by parameter count to date, Opus 4.5 reached new heights in creative writing, nuanced understanding, and "human warmth," with many users describing it as the "most human-like" AI model.
-
Claude Fable 5: The most recently released model, and the one this employee considers the most transformative.
You may have noticed that this list doesn't include every Claude version—Claude 2, the Haiku series, and others are absent. This suggests that from an insider's perspective, not every iteration represents a qualitative leap. True milestones are rare, perceptible jumps in capability.
From "Tool" to "Collaborator": The Cognitive Shift Claude Fable 5 Brings
The employee's assessment of Fable 5 is particularly worth unpacking:
"With Fable, the model stopped feeling like a tool I direct and started feeling more like something I collaborate with."
This statement reveals a deep-level shift in interaction paradigms. With previous models, no matter how powerful, the user-AI relationship was fundamentally a "command-execute" pattern: humans state requirements, AI completes tasks. Claude Fable 5 appears to have somewhat broken this one-directional relationship, making interactions more bidirectional and dynamic.
From a Human-Computer Interaction (HCI) research perspective, this paradigm shift from "command-execute" to "collaboration" has deep theoretical roots. As early as the 1960s, computer science pioneer J.C.R. Licklider proposed the concept of "Man-Computer Symbiosis," envisioning computers not merely as execution tools but as extensions of human thought and cooperative partners. Today's development of large language models is gradually making this vision a reality. The key to this transformation lies in whether models possess rudimentary "Theory of Mind"—the ability to infer users' intentions, knowledge states, and emotional needs, and adjust their response strategies accordingly.
What Might This Human-AI Collaboration Shift Mean?
From a technical standpoint, the enhanced "sense of collaboration" likely stems from advances in several areas:
- Increased proactivity: The model no longer passively awaits instructions but can proactively offer suggestions, identify problems, and supplement angles the user hasn't considered.
- Deeper contextual understanding: The model better grasps user intent and workflows, maintaining coherent "collaborative awareness" across long conversations.
- More natural expression: Interactions no longer feel like filling out forms or issuing commands, but more like discussing problems with an insightful colleague.
Industry Implications: Interaction Experience as the Next Competitive Dimension
This insider's experience actually points to an emerging new competitive dimension in the AI industry—qualitative transformation in interaction experience.
Over the past two years, competition among AI companies has primarily focused on quantifiable metrics: benchmark scores, context window length, inference speed, and so on. But as models converge on these hard metrics, differentiation at the user experience level is becoming increasingly important. As of 2025, top models like GPT-4.5, Claude Opus 4.5, and Gemini Ultra 2.0 have narrowed their gaps on academic benchmarks such as MMLU, GPQA, and ARC to single-digit percentage points. This "benchmark saturation" phenomenon is forcing AI companies to seek new directions for differentiation—some are going deep into vertical domains (like code generation or scientific reasoning), while others are focusing on interaction experience. User retention data shows that what determines which model users stick with long-term often isn't benchmark rankings, but "conversation feel"—including response naturalness, handling of ambiguous instructions, and whether the model exhibits coherent "personality" across multi-turn dialogues.
The description "from tool to collaborator" represents precisely the kind of progress that's difficult to measure with benchmarks yet clearly perceptible to users. This also explains why Anthropic has consistently emphasized its "Helpful, Harmless, Honest" (HHH) philosophy in recent years—they're pursuing not just capability improvements, but fundamental enhancement of human-AI interaction quality. Notably, Anthropic's HHH framework stems from its unique Constitutional AI research approach. Unlike OpenAI's primary reliance on RLHF (Reinforcement Learning from Human Feedback), Anthropic built upon this foundation to develop RLAIF (Reinforcement Learning from AI Feedback), allowing models to self-evaluate and improve based on a set of predefined principles. This approach not only reduces dependence on large-scale human annotation but also enhances model behavior controllability and consistency. HHH isn't simply a safety constraint—it's a complete model behavior design philosophy aimed at enabling AI to exhibit more trustworthy interaction quality while maintaining powerful capabilities.
Of course, as an assessment from an Anthropic insider, these remarks inevitably carry a degree of subjectivity and positional bias. How Claude Fable 5 actually performs still needs validation from a broader user base and independent evaluations. But at least from this perspective, AI model evolution is moving from "more powerful" toward "more usable," from "capability stacking" toward "experience leaps."
Final Thoughts
Each landmark model redefines the boundary of the human-AI relationship. If Claude Fable 5 truly achieves the leap from "tool" to "collaborative partner" as this employee describes, then it's not just a product milestone for Anthropic—it may be a signal that the entire AI industry is entering a new phase.
The future of AI competition may no longer be solely about who's smarter, but about who better understands how to work alongside humans.
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.