Andrew Ng's New Course: A Complete Guide to Enhancing RAG with Knowledge Graphs

How knowledge graphs extend RAG from semantic similarity search to structured relationship reasoning.
Andrew Ng's new course with Neo4j teaches how Knowledge Graphs enhance RAG by going beyond vector similarity search. The course covers building graph-based retrieval systems using Neo4j, LangChain, and embedding models, using SEC financial filings as a hands-on case study. It demonstrates how graph traversal enables multi-hop reasoning and cross-document retrieval that traditional RAG cannot achieve.
Course Overview
Andrew Ng has partnered with Neo4j to launch a new short course, Knowledge Graphs for RAG, taught by Andreas Kollegger, Neo4j's Generative AI Developer Advocate. The course systematically covers how to leverage Knowledge Graphs to improve the effectiveness of Retrieval-Augmented Generation (RAG) applications.
The core message of the course is clear: Knowledge Graphs are one of the most powerful yet underestimated tools in AI. When you combine Knowledge Graphs with embedding models, you have a formidable weapon for performing RAG.
What Is a Knowledge Graph?
A Knowledge Graph provides a way to store and organize data that emphasizes the "relationships between things." Unlike traditional relational databases that organize data into rows and columns, Knowledge Graphs use a graph-based structure:
- Nodes: Represent things or entities, such as people or companies
- Edges: Represent connections or relationships between entities, such as employment relationships
Each node and edge can store additional information. For example, a "Person" node can store details like name and email; a "Company" node can store data like employee count and annual revenue; and the "Employment" edge connecting the two can store information like job title and start date.
The concept of Knowledge Graphs was formally introduced by Google in 2012 to enhance search engine semantic understanding, though its theoretical foundations trace back to the earlier Semantic Web movement and the RDF (Resource Description Framework) standard. The underlying data model of Knowledge Graphs is based on graph theory, using "subject-predicate-object" triples to express facts. Neo4j, currently the most popular native graph database, adopts the Property Graph Model, which allows both nodes and edges to carry key-value pair properties — making it more expressive than traditional RDF triples. Its query language, Cypher, draws design inspiration from SQL and SPARQL, using ASCII art-style pattern matching syntax (e.g., (a)-[:KNOWS]->(b)) that makes graph queries intuitive and readable.

The core advantage of this graph structure is that relationships themselves are part of the database, rather than merely being foreign keys shared between two tables. This makes representing and searching deep relationships extremely efficient, with query execution speeds far exceeding those of traditional databases.
This is why search engines and e-commerce sites use Knowledge Graphs as a key technology for delivering relevant results. When you search for a celebrity on Google or Bing, the sidebar card results are retrieved through a Knowledge Graph.
How Do Knowledge Graphs Enhance RAG?
Limitations of Traditional RAG
Retrieval-Augmented Generation (RAG) was proposed by the Meta AI research team in 2020. The core idea is to retrieve relevant information from an external knowledge base and inject it as context into the prompt before the large language model generates an answer. This paradigm addresses two major LLM pain points: knowledge cutoff date limitations and hallucination issues.
In a basic RAG system, the document processing pipeline works as follows:
- Split documents into smaller text chunks
- Use an embedding model to convert text chunks into vectors
- Search for chunks relevant to the prompt using functions like cosine similarity
Text embedding is a critical component of RAG — it maps natural language text into a high-dimensional vector space where semantically similar texts are positioned closer together. Cosine similarity measures the degree of similarity by calculating the cosine of the angle between two vectors, with a range of [-1, 1], where 1 indicates identical direction. Commonly used embedding models include OpenAI's text-embedding-ada-002, Cohere's embed models, and the open-source sentence-transformers family.
The text chunking step may seem simple but has far-reaching implications. Common strategies include fixed-size chunking (e.g., every 512 tokens), semantic chunking based on sentences or paragraphs, and recursive character splitting. Chunks that are too small lose context, while chunks that are too large introduce noise and may exceed the embedding model's context window. Overlapping Chunks mitigate context fragmentation by having adjacent chunks share portions of text.
This purely vector similarity-based retrieval approach has clear shortcomings — it is essentially a "flattened" semantic matching that can only capture surface-level semantic similarity in text, unable to understand structured relationships between entities. For example, when a user asks "What other companies does Apple's CEO manage?", vector retrieval might return text chunks containing the keywords "Apple" or "CEO," but it cannot reason along relationship chains like "Tim Cook → CEO of → Apple" and "Tim Cook → Board Member of → Nike." Furthermore, vector retrieval is inherently weak at Multi-hop Reasoning — when an answer requires synthesizing scattered information fragments across multiple documents, simple similarity ranking often fails to retrieve all the necessary context pieces.
Advantages of Knowledge Graph RAG

Storing text chunks in a Knowledge Graph opens up entirely new retrieval methods:
- Going beyond similarity search based solely on text embeddings
- After retrieving one text chunk, traversing the graph structure to find other related chunks
- Providing the LLM with more complete contextual information
- Leveraging relationships and metadata stored in the graph to improve retrieval relevance
Graph Traversal is the core operation of Knowledge Graph retrieval, with two basic strategies: Breadth-First Search (BFS) and Depth-First Search (DFS). In RAG scenarios, the typical retrieval flow is: first find the most relevant starting nodes through vector similarity, then explore neighboring nodes along relationship edges via graph traversal to collect additional context. Neo4j's Cypher language supports variable-length path matching (e.g., (a)-[:RELATED*1..3]->(b) represents a relationship chain of 1 to 3 hops), enabling multi-hop reasoning through concise declarative queries.

In short, Knowledge Graph RAG can discover connections between text sources that similarity-based RAG misses. In Knowledge Graph RAG, chunking strategy is particularly important because each text chunk becomes a node in the graph, and relationships between chunks (e.g., originating from the same document, referencing the same entity) are explicitly modeled as graph edges — weaving originally isolated text fragments into a semantic relationship network.
Course Learning Path
The course uses SEC (U.S. Securities and Exchange Commission) financial filing data as a hands-on case study, with a progressive learning path:
The SEC (U.S. Securities and Exchange Commission) requires all publicly traded companies to periodically submit standardized financial disclosure documents, including 10-K (annual reports), 10-Q (quarterly reports), and 8-K (current event reports), among other forms. These documents are highly structured: they contain fixed sections such as company information, financial data, risk factors, and management discussion, and filings from different companies share numerous linkable entities (such as common auditors, suppliers, industry classifications, etc.). This makes SEC data an ideal teaching case for Knowledge Graph RAG — it requires processing unstructured text descriptions while also modeling complex relationship networks between entities, perfectly demonstrating the advantages of graph structures over pure vector retrieval.
- Getting Started with Knowledge Graphs: Explore and modify a movie data graph using Neo4j's query language Cypher
- Vector Integration: Combine text embedding models to create vector representations for text fields in the Knowledge Graph
- Building a RAG System: Construct a Knowledge Graph for a set of SEC forms and use LangChain to perform RAG retrieval
- Cross-Document Retrieval: Create a graph for a second set of SEC forms, connect the two graphs, and use complex graph queries for cross-document retrieval
LangChain is one of the most popular LLM application development frameworks, created by Harrison Chase in 2022. It provides modular abstraction layers that chain together prompt templates, LLM calls, retrievers, memory modules, and other components into reusable "Chains." In Knowledge Graph RAG scenarios, LangChain offers specialized components such as Neo4jVector (using Neo4j as a vector store) and GraphCypherQAChain (automatically generating Cypher queries). Its LCEL (LangChain Expression Language) allows developers to orchestrate complex retrieval-reasoning pipelines declaratively — for example, first performing vector retrieval to get candidate nodes, then executing graph traversal to expand context, and finally injecting all information into the LLM to generate the final answer.

Practical Value and Insights
The practical significance of this course manifests on several levels:
For developers, Knowledge Graph RAG provides a more precise solution than pure vector retrieval for handling complex document collections (such as financial reports, legal documents, and medical records). When data involves complex interconnected relationships, the advantages of graph structures become especially apparent.
For AI application design, this reveals an important trend: RAG systems are evolving from a single "retrieve-generate" paradigm toward "structured understanding → relationship reasoning → precise generation." Knowledge Graphs don't just store information — they encode the semantic relationships between pieces of information.
For learners, the Neo4j + LangChain + embedding model technology stack represents the mainstream implementation approach for Knowledge Graph RAG today, with high engineering practicality. Combined with LangChain's GraphCypherQAChain, LLMs can automatically convert natural language questions into Cypher queries, enabling end-to-end graph-enhanced retrieval — significantly lowering the barrier for developers to use graph databases.
Conclusion
The core message of Andrew Ng's course is clear: When RAG meets Knowledge Graphs, the dimension of retrieval expands from "semantic similarity" to "relationship reasoning." For scenarios involving structured or semi-structured documents that require cross-document reasoning, Knowledge Graph RAG is a technical direction well worth exploring in depth.
From a broader perspective, Knowledge Graph RAG represents an important evolutionary direction in AI application architecture: deeply integrating symbolic AI (reasoning based on rules and structured knowledge) with connectionist AI (semantic understanding based on neural networks). Knowledge Graphs provide precise structured reasoning capabilities, while embedding models provide flexible semantic matching capabilities. Their combination enables RAG systems to both understand the fuzzy semantics of natural language and perform logical reasoning along explicit knowledge structures — precisely the dual capability needed to build reliable AI applications.
Related articles
AI Can't Kill Old-School Programming: Why Fundamentals Are Still a Developer's Moat
Vibe Coding is trending, but can it replace solid fundamentals? A deep analysis of why core principles, systems thinking, and knowledge frameworks remain a developer's moat in the AI era.
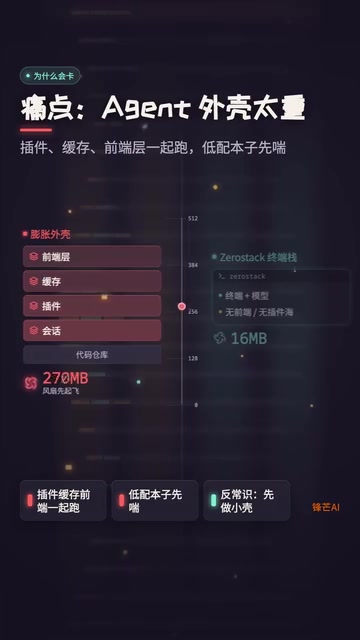
ZeroStack: An In-Depth Look at the Rust-Based Minimalist Coding Agent That Uses Only 16MB of RAM
In-depth review of ZeroStack, a Rust-based coding agent using only 16MB RAM. Analyzing its file I/O, multi-model support, permission controls, and ideal use cases.
ZCodeAI Free AI Agent Tool Review: Multi-Model Aggregation at Zero Cost
Detailed review of ZCodeAI, a desktop AI Agent tool by ZhiPu featuring free built-in models like DeepSeek V4 Flash and Xiaomi MiMo, with multi-model aggregation and no API Key required.