Anthropic's Latest Research: AI Recursive Self-Improvement Is Rapidly Approaching Human-Level Capability
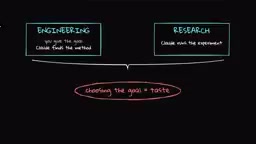
Anthropic's data shows AI recursive self-improvement capability is rapidly closing the gap with human judgment.
Anthropic's latest research report reveals striking progress in AI recursive self-improvement. Claude now writes over 80% of Anthropic's merged code, achieves 52x training code speedup, and outperforms human researchers at 64% of key decision points. AI agents independently closed 97% of a gap on an AI safety research problem. However, metrics like code volume can be misleading, and Goodhart's Law remains a concern. The report suggests practitioners should shift focus from doing work to defining and validating it.
The Core Question: What Does AI Recursive Self-Improvement Mean?
Anthropic recently published a landmark research report focusing on Recursive Self-Improvement in AI systems — the idea that AI systems are gradually becoming capable of designing and training the next generation of AI, with decreasing reliance on human involvement.
For a long time, the industry has taken comfort in a reassuring narrative: AI cannot replace human "taste" — the ability to judge which problems are worth solving, which results are trustworthy, and when to abandon a dead end. However, Anthropic's internal experimental data suggests that this seemingly solid boundary is being quietly eroded.
A Qualitative Shift in Self-Optimizing Systems: From Evolutionary Algorithms to Generative AI
The concept of self-optimizing systems is nothing new. Evolutionary algorithms have been doing something similar for decades: generating a batch of variant solutions, scoring them with a fitness function, keeping the best, and repeating. This approach has long been widely applied in chip design, software optimization, and other fields.
But the generative AI era has brought a qualitative leap:
- DeepMind's AlphaEvolve broke a scalar multiplication record that had stood since 1969
- Sakana's Darwin Godel Machine improved its own SWE-bench score from 20% to 50%
- Andrej Karpathy's Auto Research system can autonomously run experiments and optimize objective functions
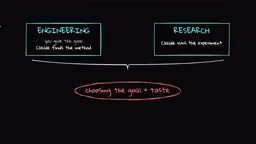
What you might not have noticed is that in all of the above systems, humans are still responsible for defining the objective function and evaluation criteria. Anthropic divides its own work into two dimensions: Engineering (writing code and infrastructure) and Research (choosing experimental directions and interpreting results). At the engineering level, Claude can already take a vague problem and find a solution on its own; at the research level, it can already match human ability to execute well-defined experiments. The remaining gap is the judgment to choose the goals themselves.
Exponential Growth in Task Capability: METR Benchmark Data
METR (an independent evaluation lab) provides an intuitive quantitative perspective through its task horizon benchmark. This benchmark measures the tasks a model can independently complete with a 50% success rate, quantified by the time a human would need to complete the same task. It's important to note that this isn't the model's runtime, but the equivalent human work hours.
The data shows this number roughly doubles every four months:
- Opus 4 in March 2023: approximately 4-minute-level tasks
- Opus 4.6 in February 2025: approximately 12 hours
- Latest preview version: approximately 17 hours, approaching the upper limit of what METR can currently measure
This growth rate means that AI's ability to independently handle complex tasks is improving far faster than most people expect.
Anthropic's Internal Data: Breakthroughs in Both Engineering and Research
The Leap in Engineering Efficiency
As of May 2025, over 80% of merged code at Anthropic was written by Claude. In early 2024, before Claude Code was released, that figure was in the single digits. A typical engineer now merges 8x more code per day than in 2024.

In a recurring internal test, the research team had Claude optimize training code speed. A year ago, the best model achieved roughly a 3x speedup, while by April of this year it had reached a 52x speedup. For comparison, a skilled human researcher would need 4 to 8 hours to achieve a 4x speedup. Additionally, Claude fixed over 100 issues in a single month, reducing one class of API errors by 1,000x — engineers would have needed an estimated 4 years to accomplish similar work.
The Breakthrough in the "Taste" Test
Even more striking are the experiments on research judgment. Anthropic extracted real research session logs, identified key decision points where humans chose the next step, and then had the model judge whether there was a better choice — adjudicated by reviewers who knew the final outcomes.
| Model Version | Percentage of Decisions Better Than Human |
|---|---|
| Claude Opus 4.5 (last November) | 51% |
| Preview version (this April) | 64% |
| Theoretical ceiling | ~90% |
This means that at specific decision points, the model is already beginning to demonstrate judgment superior to humans.
Limitations That Cannot Be Ignored and Goodhart's Law

Despite the impressive-looking data, there are several important reasons to remain cautious:
The 8x Code Volume Is a Misleading Metric
Lines of code reward quantity, not quality. Anthropic itself acknowledges that the real productivity gain is "almost certainly lower than this number." Community discussions have pointed out that repeated code rewrites and rollbacks inflate commit volumes. The self-reported 4x productivity improvement from employees is equally questionable — METR's independent research shows that developers tend to overestimate how much AI actually helps them.
The Taste Test Comes with Important Footnotes
When looking only at moments where humans made deliberate, strong decisions, the model only led by 20%. In other words, the model excels at "rescuing weak decisions" rather than "surpassing good decisions." This distinction is crucial.
The Specter of Goodhart's Law Looms Large
Any system optimizing toward a fixed target will eventually learn to game it. When a metric becomes a target, it ceases to be a good metric. Lines of code are precisely the kind of target that's easy to game.
The real question isn't whether the loop is accelerating — it clearly is — but whether it's optimizing for what we actually care about, or merely optimizing for what's easy to count.
The Most Remarkable Experiment: AI Agents Independently Completing Safety Research
Despite the caveats above, one experiment is genuinely remarkable. Anthropic selected an open problem in AI safety — whether weak models can reliably supervise strong models — handed it to Claude-powered agents, and then essentially stepped back.
Results comparison:
- Two human researchers spent about a week and closed roughly 25% of the gap
- AI agents closed the gap to 97%, accumulating over 800 hours of work and consuming approximately $18,000 in compute
The key point is that the agents designed every experiment themselves. While humans still chose the problem itself and wrote the scoring criteria, within those boundaries, the agents weren't assisting researchers — they were the researchers.
Additionally, models provided to select enterprises through Project Glasswing have already discovered over 10,000 high-severity and critical security vulnerabilities in mainstream operating systems. The bottleneck has shifted from "finding vulnerabilities" to "patching them fast enough."
A Sober Perspective: How Practitioners Should Respond to the AI Self-Improvement Trend
Anthropic raises a thought-provoking point in the report: if "research taste" is just another capability, then models may quietly master it the same way they learned to explain jokes or pass theory-of-mind tests. The narrative that humans will always remain in the judgment loop may have a countdown timer.
But several realities also need to be acknowledged:
- Capability curves are typically S-shaped, not exponential — bottlenecks in compute resources and human review may slow progress
- Current AI intelligence is still "jagged" — excelling at certain points while still performing poorly in other areas
- True recursive self-improvement is still a considerable distance away, as systems cannot yet autonomously set their own goals
For practitioners using these models today, the most practical takeaway is: Your core competitive advantage is shifting from "doing the work yourself" to "precisely defining the work and validating the results." This itself is a skill worth deeply cultivating.
Some have pointed out that Anthropic has an upcoming IPO, and publishing this kind of report may carry commercial motivations. But objectively speaking, Anthropic has previously published multiple high-quality technical reports, and this level of research transparency is consistent with their track record. Regardless of motivation, the trend presented in the report — that AI capabilities on specific tasks are rapidly approaching and even surpassing human levels — is a fact that every technology practitioner should take seriously.
Related articles
Generating 10 Web Games with One-Line Prompts: A Hands-On Claude Code Experience
A senior developer uses Claude Code to generate 10 playable web games including 2048, Gomoku, and Tetris with one-line prompts in under an hour. A deep dive into AI programming's real capabilities.

Five Essential Cursor Skills Every QA Engineer Needs: A Complete Breakdown
A detailed guide to five essential Cursor Skills for QA engineers: PRD analysis, test case generation, JMeter scripting, load test reports, and web automation.
DiffusionGemma: Google's Open-Source Diffusion Language Model with 4x Faster Inference
Google releases DiffusionGemma, an open-source diffusion language model achieving up to 4x faster inference and real-time self-correction by generating text in parallel rather than token by token.