Building a DeepSeek Agent from Scratch: Principles, Token Optimization, and Bootstrapped Development
A hands-on guide to building a zero-dependency DeepSeek AI Agent, covering core principles and token optimization.
A developer built an AI Agent called Seekran from scratch in two days with zero dependencies, powered by DeepSeek V3 Flash. This article breaks down the Agent loop mechanism, Function Calling principles, token optimization strategies including cache hit maximization, and the bootstrapped development approach where the Agent modifies its own code — all at a cost of roughly two yuan.
Introduction: Why Build an AI Agent from Scratch?
In an era where AI Agent frameworks are everywhere, most developers opt for mature frameworks like LangChain or CrewAI to build intelligent agents. But one developer took the opposite approach — he decided to build an AI Agent entirely from scratch, with zero third-party dependencies, all hand-written code, for one single purpose: to truly understand how Agents work.
This Bilibili content creator spent two days developing an Agent tool called "Seekran," powered by the DeepSeek V3 Flash model on the backend, and published it to the NPM package registry so users can run it instantly via npx. NPM (Node Package Manager) is the largest package manager in the JavaScript ecosystem, hosting over 2 million open-source packages. npx is a package execution tool built into NPM 5.2+, which temporarily downloads and runs a specified package, then discards it — making it ideal for distributing CLI tools. This means any user with Node.js installed can experience the full Agent functionality with a single command, no manual download or installation required. What's even more interesting is that this Agent is "bootstrapped" — it was used to develop itself, and the entire development cost was roughly two Chinese yuan, about the price of a popsicle.
The Core Principle of AI Agents: One Loop to Rule Them All
An Agent Is Essentially an Interaction Loop
The core mechanism of an Agent is actually quite simple: establish a loop where the user interacts with a large language model, invoking a series of internal tools to perform various operations, ultimately achieving the user's desired outcome.
This description is concise but accurately captures the working pattern of virtually all AI Agents. In academia, this loop mechanism is called the "Perceive-Reason-Act" cycle, which can be traced back to the BDI (Belief-Desire-Intention) architecture in artificial intelligence. Since 2023, with the leap in large language model capabilities, this classic architecture has been revitalized. The ReAct (Reasoning + Acting) paper was the first to systematically demonstrate the effectiveness of having LLMs alternate between reasoning and tool invocation — under this paradigm, an Agent is no longer a simple question-and-answer system, but continuously refines its action strategy through multiple rounds of "chain of thought" until the task is complete.
Whether it's AutoGPT or Devin, the underlying logic is the same: receive instructions → plan steps → invoke tools → observe results → continue or finish. Once you understand this loop, you understand the essence of Agents.
An Agent's ability to invoke tools relies on the model's Function Calling mechanism. Here's how it works: developers predefine a set of tools with their names, parameter formats, and functional descriptions, passing them to the model in JSON Schema format. During inference, if the model determines it needs to use a tool, it generates a structured function call request rather than natural language text. The Agent framework captures this request, executes the corresponding function locally, and passes the result back to the model, which then continues reasoning based on the tool's output. The DeepSeek V3 series models have excellent native support for Function Calling, enabling developers to achieve stable tool invocation without complex prompt engineering.
Transparency by Design: Every Step Crystal Clear
This Agent has a design philosophy well worth emulating — transparency first. When you enter the Agent and ask it to introduce itself, the AI automatically scans the current working directory and provides details of every tool invocation. After each AI generation round, it lists in detail:
- Which tools were called
- How many steps were executed
- Token usage for Prompt and Completion
- Cache hit rate
This transparent design gives users a clear perception of the cost of each interaction, which is extremely practical in real-world use. You're no longer operating blindly inside a black box — you know exactly where every penny goes.
Thoughts on Technology Choices: Language Selection Still Matters in the AI Era
From Zig to JavaScript
The developer initially wanted to use Zig to build this Agent, because tech forums were hyping it up and the narrative that "in the AI era, language doesn't matter" was gaining traction. Zig is a systems programming language born in 2016, positioned as a "better C," known for zero-overhead abstractions, no implicit behavior, and compile-time computation. It gained significant attention in 2023-2024 thanks to Bun (a high-performance JavaScript runtime written in Zig).
But after careful consideration, he abandoned the idea for two reasons:
- Zig is still in a very early stage — the standard library and APIs undergo frequent breaking changes, lacking stability. As of 2025, Zig still hasn't released a stable 1.0 version, its standard library APIs change frequently, and its ecosystem is far less mature than established languages.
- The developer must be able to understand what the AI is writing to maintain control over the project's quality. More critically, Zig code makes up an extremely small proportion of LLM training data, meaning AI-generated Zig code is far less accurate and reliable than JavaScript or Python.
This is a very pragmatic judgment — essentially a rational trade-off between "technical novelty" and "engineering controllability." AI writes code so fast that it's hard to keep up; if you're not sufficiently familiar with the language itself, you can't effectively review the quality of AI-generated code. He ultimately chose JavaScript, the language he's most proficient in, and built the entire project with zero dependencies, implementing everything from scratch.
"Zero dependencies" means the project doesn't import any third-party npm packages. All functionality — including HTTP requests, terminal interaction, file operations, JSON parsing, etc. — is implemented using Node.js native APIs or built from scratch. This approach is relatively rare in the JavaScript community, which is notorious for complex dependency chains (the infamous left-pad incident being a prime example). The advantages of zero dependencies include: extremely fast installation, no supply chain security risks, minimal package size, and no unexpected breakage from upstream dependency updates. The downside is a larger development workload, requiring deep understanding of low-level APIs. For a learning-oriented project, this is actually the best choice — every line of code is your own, and your understanding is as thorough as it gets.
Key Insight: Slow Down for Better Code Quality
The developer raised a thought-provoking point: AI writes code so fast that it's hard to keep up — slowing down is what keeps your project quality high. The key is the role humans play in the process — not being swept along by AI's speed, but maintaining your own rhythm and judgment. This is an important reminder for all developers using AI for programming.
Token Optimization Strategies: The Core of Saving Money with Agents
Four Token Consumption Optimization Techniques
Tokens are the basic unit for billing and text processing in large language models. In Chinese, roughly every 1-2 characters correspond to one token; in English, each word corresponds to approximately 1-1.5 tokens. The cost of each API call is determined by both input tokens (Prompt) and output tokens (Completion). For an Agent that requires frequent multi-turn interactions, token consumption optimization directly determines usage costs.
While maintaining accuracy, the developer implemented multiple methods in the Agent to reduce token consumption and improve cache hit rates:
- Internal tool output truncation: Tool outputs are often verbose; intelligent truncation can dramatically reduce token consumption
- Conversation history compression: As conversation turns increase, message history grows longer; compression strategies retain key information
- Discarding orphaned tool messages: Cleaning up tool invocation records that are no longer referenced
- Fixed system prompt prefix: Keeping the system prompt prefix unchanged to maximize DeepSeek's caching mechanism
The fourth point is particularly crucial. DeepSeek's Context Caching is a server-side optimization: when multiple requests share the same prefix content, the server reuses previously computed KV Cache (Key-Value Cache, a data structure in Transformer models that stores intermediate results of attention computations), significantly reducing computational costs and response latency. Cached tokens are typically billed at one-tenth of the original price or even less. This is why "fixing the system prompt prefix" can significantly reduce costs — the system prompt portion of each conversation hits the cache, and only new user messages and tool results require full-price computation.
It's worth noting that DeepSeek's caching already works quite well on its own. Combined with these optimization techniques, you can consume more tokens at a lower price, achieving better cost-effectiveness.
Hands-On Demo: Having the Agent Modify Its Own Code
The Real-World Effect of Bootstrapped Development
Bootstrapping is a classic concept in computer science — the most famous example being the C compiler written in C itself. In this project, "bootstrapping" means using the Seekran Agent to develop and improve Seekran's own code. This isn't just an efficient development approach; it's the ultimate validation of an Agent's capabilities — if a coding Agent can't even understand and modify its own code, its practical utility is questionable.
Actions speak louder than words. The developer had the Agent modify its own code to verify its effectiveness: when exiting the Agent, session statistics are displayed, but the prompt text was too prominent and needed to be toned down.
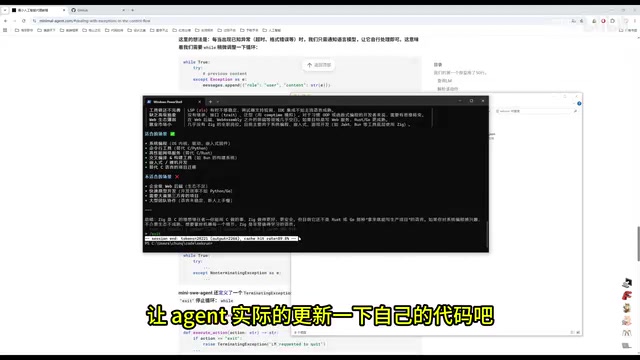
After re-entering the Agent and inputting the modification request, the Agent automatically analyzed the code, located the file, and completed the changes. Since Chinese output wasn't strictly enforced, the Agent sometimes outputs explanations in English — but if you can't understand it, you can simply ask it to translate. After reviewing the results, the modification was confirmed successful.
This bootstrapped development experience showcases the Agent's real capabilities: it can not only help you write code but also understand project context and precisely complete modification tasks. Bootstrapped development also creates a positive feedback loop: every improvement to the Agent makes the next self-improvement even more efficient.
Flexible Extension with Custom Features
Because it's a fully self-developed tool, the developer can add any features he likes at will. For example, he implemented auto-sensing and intelligent completion similar to Fish Shell, greatly improving development efficiency. This is another advantage of building from scratch — you know every line of code inside out, making extension and customization completely frictionless.
Conclusion: Key Takeaways from Building an Agent from Scratch
This hands-on experience of building a DeepSeek Agent from scratch offers several important insights:
- Understanding principles matters more than using frameworks: When you truly understand the Agent loop mechanism, you can use any framework more effectively
- Be pragmatic with technology choices: Don't get swept up by tech trends — choose a tech stack you can control
- Transparency is good design: Let users clearly see the cost and process of every step to build trust
- Token optimization saves real money: Strategies like cache hits and history compression deliver significant results in practice
- In the AI era, human judgment matters more: It's not about chasing AI's coding speed, but maintaining control over code quality
Two days, two yuan, zero dependencies — this small project may be simple, but the thinking and practical experience behind it is worth learning from for every AI developer.
Related articles

Databricks Open-Sources Omni: A Meta-Framework for Unified Management of All AI Agents
Databricks open-sources Omni under Apache 2.0 — a meta-framework unifying Claude Code, Codex & more AI Agents with shared sessions, cross-vendor review & enforced security policies.
Generating 10 Web Games with One-Line Prompts: A Hands-On Claude Code Experience
A senior developer uses Claude Code to generate 10 playable web games including 2048, Gomoku, and Tetris with one-line prompts in under an hour. A deep dive into AI programming's real capabilities.

Five Essential Cursor Skills Every QA Engineer Needs: A Complete Breakdown
A detailed guide to five essential Cursor Skills for QA engineers: PRD analysis, test case generation, JMeter scripting, load test reports, and web automation.