Claude Agent SDK + LiteLLM + Local LLMs: Building a Zero-Cost AI Agent Platform

Route Claude Agent SDK requests to local LLMs via LiteLLM Proxy for zero API cost.
Claude Agent SDK is a top-tier agent framework, but its API costs are prohibitively high. This article presents a solution using LiteLLM Proxy middleware to redirect the SDK's API requests to locally deployed open-source LLMs (such as Qwen), achieving zero inference cost while fully preserving tool calling, context management, and other framework capabilities. The core idea is decoupling framework capabilities from inference capabilities, making it ideal for development testing, enterprise internal deployment, and prototype validation.
Claude Agent SDK Is Powerful, But API Costs Are Staggering
In the AI Agent development space, Anthropic's Claude Agent SDK is one of the best frameworks available today. It excels in Agentic Coding, Context Engineering, and beyond—suitable not only for development tasks but also for a wide variety of non-development agent workflows.
Background: What Are Agentic Coding and Context Engineering? Claude Agent SDK is an agent development framework released by Anthropic in 2024. Its core strengths lie in deep support for "Agentic Coding" and "Context Engineering." Agentic Coding means the AI model can not only generate code but also autonomously execute code, read/write the file system, invoke external tools, and iteratively self-correct based on execution results—a capability leap that traditional code completion tools (like GitHub Copilot) cannot achieve. Context Engineering refers to fine-grained management of the model's context window, including how to compress, summarize, and retain critical information across multiple tool calls to avoid context overflow. These two capabilities are what make Claude Agent SDK far superior to simple prompt calls in complex, multi-step tasks.
However, there's an unavoidable reality: API call costs are prohibitively high.
For example, using the Claude Code Agent to complete a simple page generation task via API can cost nearly $1. And that's just an extremely simple task—if a team needs extensive testing, iteration, and development, costs become completely uncontrollable. For individual developers or small teams, this is an almost insurmountable barrier.
So the question becomes: Is there a way to leverage the powerful framework capabilities of Claude Agent SDK while keeping costs within a reasonable range?
Core Approach: LiteLLM Proxy + Local LLMs for Zero-Cost Inference
The answer is: redirect Claude Agent SDK's API requests to locally deployed LLMs through LiteLLM Proxy.
Overall Architecture Design
The entire solution is structured in three layers:
- Agent Framework Layer: A self-built agent platform responsible for task management, agent scheduling, and other high-level logic
- Claude Agent SDK Layer: Loaded as the core Worker for agents, providing complete agent capabilities (tool calling, context management, etc.)
- LiteLLM Proxy Layer: Intercepts requests that Claude Agent SDK would normally send to Anthropic's Cloud API and proxies them to local LLMs
The technical elegance lies in this: Claude Agent SDK by default sends requests to Anthropic's remote API, but by configuring LiteLLM Proxy, you can point it to a local proxy port. LiteLLM Proxy then transforms these requests into a format that local LLMs can understand, and the local model (such as Qwen deployed via LM Studio) handles the actual inference.
This way, we retain all of Claude Agent SDK's advantages in tool calling, task orchestration, and context engineering, while the actual inference computation happens entirely locally—reducing API call costs to zero.
Key Component Overview
- LM Studio: Exposes local LLM services through a local port, supporting loading and inference of various open-source models
- LiteLLM Proxy: An open-source LLM proxy gateway that unifies different API request formats—the core middleware enabling request redirection
- Claude Agent SDK: Provides the complete agent toolchain, including built-in tools like Web Search and Web Fetch
Deep Dive: How Does LiteLLM Proxy Achieve "Protocol Translation"? LiteLLM is an open-source unified LLM access layer project. The core value of its Proxy mode lies in "protocol translation" and "route management." Different LLM providers (OpenAI, Anthropic, Cohere, etc.) and local inference frameworks (Ollama, LM Studio, vLLM, etc.) each use their own API formats and authentication methods. LiteLLM Proxy acts as a middle layer that converts all requests into OpenAI-compatible format, then routes them to the target backend based on configuration. For Claude Agent SDK, it normally sends Anthropic-formatted requests to
api.anthropic.com; by setting the environment variableANTHROPIC_BASE_URLto point to LiteLLM Proxy's local port, the SDK sends all requests to the proxy, which handles format conversion before forwarding to the local model. This mechanism requires no modification to the SDK source code, offering low invasiveness and high maintainability.
Local Inference Engines: Why Are LM Studio and Qwen Suitable as Agent Foundations? LM Studio is one of the most popular local LLM management and inference tools today, supporting quantized GGUF-format models on consumer GPUs (or even pure CPU). Its built-in local server feature exposes loaded models as OpenAI-compatible APIs on a local port (default 1234), allowing any client that supports the OpenAI interface to call them directly. Qwen, mentioned in this article, is Alibaba Cloud's open-source large language model series. Its instruction-following capability and tool calling (Function Calling) support are among the best in open-source models, making it well-suited as an underlying inference engine for agents. It's worth noting that tool calling capability is a necessary condition for agent frameworks to function properly—the model must be able to correctly parse tool definitions and output structured invocation instructions, or the entire agent orchestration pipeline will break down.
Practical Demo: Enterprise-Grade Agent Platform in Action
To validate this solution's feasibility, we built a prototype-level enterprise agent platform and ran a complete demonstration.
Creating Tasks and Assigning Agents
First, we create a research task on the platform: "Best Agent SDK in the market"—having the agent research mainstream Agent SDKs available on the market.
Next, we assign the task to an agent named "Alicia." In Alicia's configuration, you can see it uses Claude Agent SDK as its underlying engine and is equipped with tools like Web Search and Web Fetch, giving it the ability to search the internet and scrape web pages.

Execution Process and Log Analysis
Once the task is assigned, Claude Agent SDK immediately begins working. By examining LiteLLM's logs, you can clearly see:
- The local proxy port has started receiving requests from Claude Agent SDK
- Requests contain the complete task description, system prompt, user prompt, and all available tool lists
- All requests are being forwarded to the local Qwen model, not Anthropic's remote API
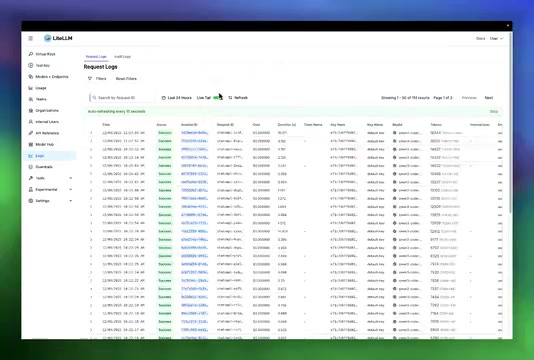
In the logs, you can see the complete call chain: system prompt setup, user message delivery, tool call records, and the model's step-by-step response process. Every chunk returned comes from the local model—the entire process incurs zero remote API fees.
Final Research Results
After completing the research, Alicia generates a comprehensive Agent SDK market analysis report covering the following mainstream frameworks:
- Anthropic Claude Agent SDK
- OpenAI Agent SDK
- LangChain
- LlamaIndex
- AutoGen
- CrewAI
The report includes not only brief introductions to each framework but also directly accessible links. More importantly, by checking the Anthropic API usage records, we can confirm that no new remote API requests were made during the entire process—all inference was completed locally.
Solution Advantages and Use Cases
Four Core Advantages
- Dramatically Reduced Costs: From nearly $1 per simple task to virtually zero—only local electricity and hardware costs
- No Compromise on Framework Capabilities: Fully preserves Claude Agent SDK's tool calling, context management, task orchestration, and other core capabilities
- Data Security and Control: All data and inference stay local, with nothing transmitted to third-party servers
- Flexible and Extensible: Through LiteLLM Proxy, you can switch between different local models at any time, or even mix local and remote models
Typical Use Cases
- Development and Testing: Use local models during heavy iteration and debugging, then switch to Claude API for production
- Enterprise Internal Deployment: Scenarios with strict data privacy requirements
- Personal Learning and Research: Experience and learn the full capabilities of Agent SDK at low cost
- Prototype Validation: Quickly validate agent solution feasibility without worrying about API fees
Conclusion: Decoupling Framework Capabilities from Inference Is Key
The core idea behind this solution is actually quite simple: decouple framework capabilities from inference capabilities. Claude Agent SDK provides an excellent agent orchestration framework, while the actual language model inference can be handled by any compatible model. LiteLLM Proxy plays the role of "translator" in between, making this decoupling possible.
Industry Perspective: Why Is "Framework-Inference Decoupling" an Important Trend in AI Engineering? The concept of "framework-inference decoupling" is becoming an important trend in AI engineering. Traditionally, agent frameworks were often tightly bound to specific models (like early LangChain's strong coupling with OpenAI), making model switching extremely costly. The emergence of middleware layers represented by LiteLLM enables the framework layer, inference layer, and infrastructure layer to evolve independently. This architectural pattern is similar to the "dependency injection" principle in software engineering—upper-level business logic depends on abstract interfaces rather than concrete implementations. For enterprises, this means using local models to control costs during development, seamlessly switching to more powerful cloud models in production, or even dynamically routing to different models based on task complexity to achieve fine-grained cost-quality balance. As open-source models like Qwen, DeepSeek, and Llama rapidly close the capability gap, the practical value of this hybrid deployment strategy will continue to grow.
It's important to note that local open-source models still lag behind Claude's native model in inference capability, and the quality of complex task completion may decline. However, for development debugging, prototype validation, and similar scenarios, this solution undoubtedly offers an extremely cost-effective option.
As open-source model capabilities continue to improve, this "top-tier framework + local model" combination will become increasingly practical and deserves the attention of every AI Agent developer.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.