Claude Code in Action: Building a Movie Data Scraping & Display System from Scratch in 30 Minutes
AI-assisted programming builds prototypes in 30 minutes, but going from prototype to product still needs engineering judgment.
A Bilibili content creator used Claude Code to build a complete movie data system from scratch in 30 minutes, including a web scraper, Doris database, Spring Boot backend, and Vue frontend. Two key challenges emerged: modern anti-scraping measures require real browsers simulating human behavior, and different AI models perform vastly differently in scraping scenarios. The case demonstrates that AI excels at rapid prototyping, but stability, exception handling, and other engineering concerns still require ongoing human iteration.
How Fast Is Rapid Prototyping in the AI Era
Scrolling through social media, you constantly see people showing off systems built with AI. The urge to "whip up a system from scratch" is something many developers can relate to. A Bilibili content creator shared their experience using Claude Code to build a complete movie data scraping and display system from zero in under 30 minutes.
Claude Code is Anthropic's command-line AI programming assistant that understands natural language instructions directly in the terminal, automatically generating, modifying, and debugging code. Unlike traditional code completion tools (like GitHub Copilot), Claude Code has project-level context understanding — it can handle multiple files simultaneously, understand project architecture, and execute complete development workflows from creating files to running tests. This makes it particularly suited for rapid full-stack project scaffolding.
The value of this case isn't the system's complexity, but rather how it demonstrates the real efficiency of AI-assisted programming in "rapid prototype validation" scenarios — from idea to running system in half an hour.
System Architecture: Design Approach for Four Core Modules
The requirements were straightforward: scrape movie data from a website, store it in a database, and display it through a frontend/backend system. The overall architecture contains four core components:
- Web Scraper: Responsible for extracting data from the target movie website
- Database: Using Doris's Unique Key table to prevent data duplication
- Backend Service: Built on Spring Boot for handling data query requests
- Frontend Display: Using Vue + ECharts for data visualization

The database choice deserves special mention. Apache Doris is a high-performance real-time analytical database whose Unique Key model automatically deduplicates data based on specified primary keys. When duplicate primary key data is inserted, new data automatically overwrites old data without developers writing manual deduplication logic. This is particularly valuable for scraping scenarios — the same movie might be scraped multiple times, and the Unique Key table ensures data uniqueness at the database level, greatly simplifying application-layer code complexity. Compared to MySQL's INSERT ON DUPLICATE KEY UPDATE approach, Doris's solution is more elegant.
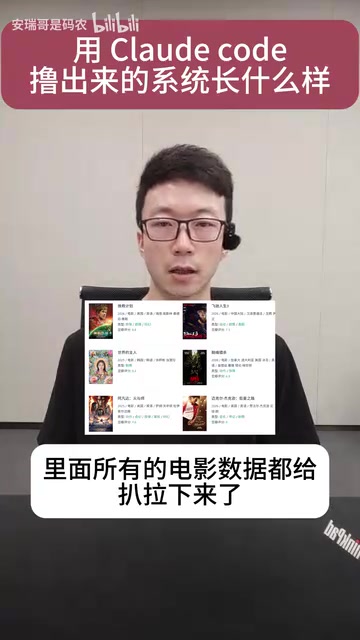
After feeding these four components' general requirements to Claude Code, it thinks through an execution plan and then implements each module step by step. For well-structured full-stack projects with clear tech stacks, AI's execution efficiency is truly impressive.
Key Challenge #1: Dealing with Modern Anti-Scraping Strategies
While the system is simple, the scraping component remains the biggest technical challenge. Nearly all websites today employ anti-scraping measures, and traditional HTTP request methods have long been ineffective.
Modern anti-scraping systems have evolved from early User-Agent detection and IP rate limiting to comprehensive protection based on browser fingerprinting, behavioral analysis, and machine learning. Systems like Cloudflare's Turnstile and Google's reCAPTCHA v3 analyze hundreds of dimensions — mouse trajectories, keyboard input rhythms, Canvas fingerprints, WebGL rendering results — to determine whether a visitor is human. Headless browsers are easily detected by these systems due to missing browser API characteristics and rendering behaviors.
Therefore, the only reliable approach is: make the scraper operate a browser like a real person. Specifically:
- Must launch a real browser instance (not headless mode)
- Simulate real user clicks, scrolling, and other behaviors
- The server running the scraper must have desktop functionality
- Browser windows must frequently pop up during scraping
- Occasional manual intervention may be needed for verification
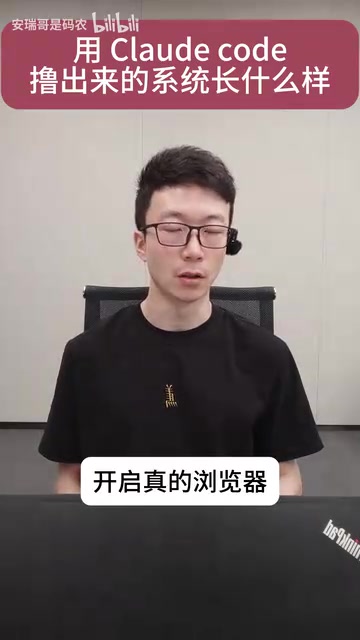
This means the deployment environment can't be a typical headless server — it needs a desktop environment configured (like XFCE, GNOME, or remote access via VNC/RDP). This is a critical detail many developers overlook in actual scraper development — everything works fine locally, but the scraper fails after deploying to a cloud server, often because there's no graphical interface environment.
Key Challenge #2: Model Selection Determines Success or Failure
A fascinating discovery: different AI models perform vastly differently in scraping scenarios.
The creator compared MiniMax 2.7 and GLM 5.1, with surprising results:
- For the same scraping task, MiniMax said it "couldn't handle it"
- After switching to GLM, the same code logic worked normally
- More critically, during browser page verification, MiniMax consistently failed verification when calling the browser, while GLM passed smoothly
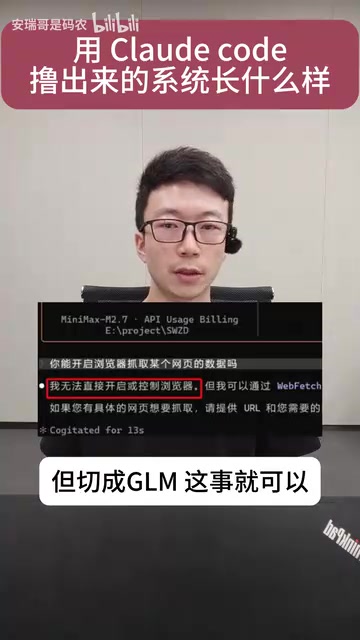
MiniMax 2.7 is a large language model from MiniMax (稀宇科技) that excels in text generation and dialogue; GLM 5.1 is Zhipu AI's latest model based on the GLM architecture. Their performance differences in browser automation scenarios likely stem from varying proportions of web automation and Selenium/Playwright code samples in training data, as well as differences in tool use and multi-step reasoning capabilities.
This reflects the capability divergence of current large models in vertical scenarios — models with similar general benchmark scores may perform vastly differently on specific tasks. Choosing the right model is sometimes more important than optimizing prompts. For developers, multi-model comparison testing at critical technical junctures should become a standard workflow step.
From Toy to Product: Real-World Iteration Challenges
While a basic version can run in 30 minutes, making it a stable, usable system requires addressing numerous engineering issues:
- Process hangs: Long-running scraper processes may freeze for various reasons
- Data loss: Network interruptions or abnormal process exits preventing data persistence
- Incorrect data formats: Parsing failures due to varying page structures
- Database insertion failures: Type mismatches, missing fields, and other database-level issues
There's a classic "last 10% problem" in software engineering — the first 90% of features might take only 20% of the time, while the final 10% of polish (exception handling, edge cases, performance optimization, monitoring and alerting) consumes 80% of the time. AI tools currently excel at generating "Happy Path" code — the logic path when everything runs normally. But production issues like network jitter, memory leaks, concurrency conflicts, and data anomalies require developers to address them based on actual operational experience.
These engineering details are what truly consume time, and where AI-assisted programming still can't fully replace human effort. Getting a scraper to work in development versus running stably 24/7 in production are entirely different engineering challenges.
Summary and Reflections
Key takeaways from this Claude Code case study:
- AI excels at "0 to 0.5" rapid prototyping: Building prototypes and validating ideas is where AI coding tools like Claude Code deliver the most value
- Technology choices still require human judgment: Choosing Doris's Unique Key table or a server with a desktop environment — these decisions require development experience
- Model selection is a hidden cost: Different models perform vastly differently in specific scenarios and require actual testing to determine
- "0.5 to 1" still requires patience: Stability, exception handling, and data quality issues need continuous iteration
AI has dramatically lowered the barrier from "idea to code," but turning "code into product" still requires engineers' professional judgment and sustained effort. For developers, leveraging AI tools for rapid validation and then applying engineering thinking to polish details is the most efficient development approach today. This also means developers' core competitiveness will shift from "coding speed" to "decision-making ability" — knowing which technology to use, which risks to guard against, and where to invest effort. These judgment skills become even more precious in the AI era.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.