Claude Code Money-Saving Guide: Replace Opus with DeepSeek to Cut Costs by 30x
Replace Opus with DeepSeek in Claude Code to cut agent data processing costs by 30x with minimal quality loss.
This article compares three approaches for agent data processing: Claude Code + Opus 4.7, Open Code + DeepSeek, and Claude Code + DeepSeek. By routing DeepSeek through Claude Code's framework via an API proxy, you can achieve 88-90% accuracy (vs. Opus's 90-95%) at 1/30th the cost. The key is leveraging Claude Code's built-in orchestration and optimizing prompts with explicit boundary definitions to compensate for the model gap.
Background: The Token Consumption Problem in Agent Data Processing
When using Claude Code (claude -p) for complex agent data processing tasks, each operation typically consumes 50K to 100K or even more tokens. Tokens are the basic unit of measurement for how large language models process text — think of them as the smallest semantic fragments after text is split up. In English, one token is roughly 4 characters; in Chinese, one character usually corresponds to 1-2 tokens. In agent mode, the model doesn't simply answer questions one at a time. Instead, it autonomously plans tasks, calls external tools, and performs multi-round reasoning. Each round of interaction re-feeds the previous context into the model, causing token consumption to grow cumulatively.
These tasks involve Tool Calls, Calculation, Web Search, Web Fetch, Reasoning, and other multi-round operations. Among these, Tool Calls are one of the core capabilities of modern LLMs, originating from the Function Calling mechanism introduced by OpenAI in 2023 and later widely adopted by major model providers. Here's how it works: when the model determines during reasoning that it needs external information or computational capabilities, it generates a structured tool call request. The runtime environment executes the request and returns the result for the model to continue reasoning. Typical tools in Claude Code include file read/write, command-line execution, web search, and web scraping. Reasoning refers to the model's internal thinking process before generating a final answer — Anthropic's Extended Thinking feature allows the model to engage in longer, deeper reasoning, which is a key reason why the Opus model excels in ambiguous scenarios.
While these capabilities are powerful, they come at a significant cost. At Anthropic's Opus model pricing ($15/million input tokens, $75/million output tokens), a single complex task can cost several dollars.
So, is there a way to dramatically reduce costs while maintaining high quality? This article compares the quality and cost performance of three approaches: Claude Opus 4.7, Open Code + DeepSeek, and Claude Code + DeepSeek.
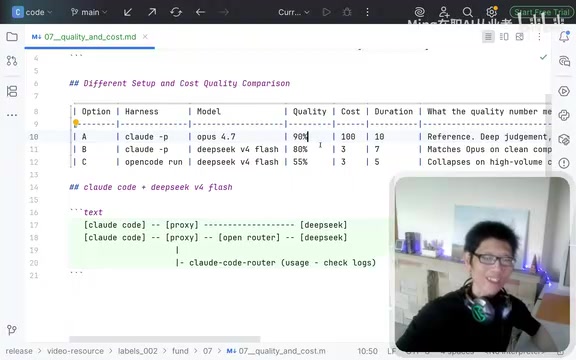
Quality and Cost Comparison of Three Approaches
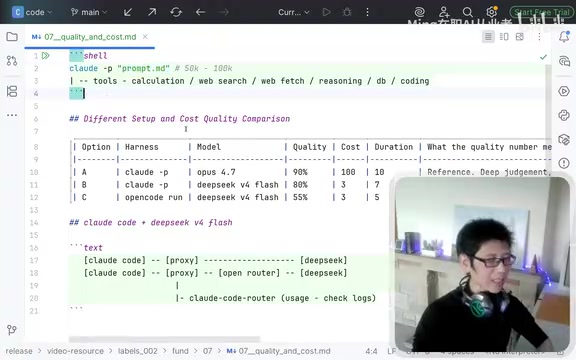
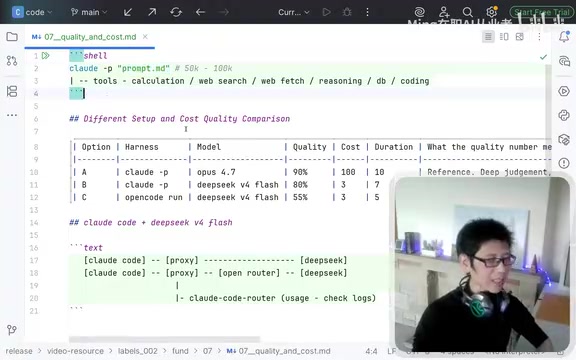
Approach 1: Claude Code + Opus 4.7 (Default Configuration)
Using Claude Code with the default Opus 4.7 model delivers excellent quality. Taking investor information extraction from large datasets as an example, accuracy typically ranges from 90% to 95%.
- Quality: Excellent — deep understanding, proactively engages in deeper-level thinking
- Cost baseline: Set at 100 (approximately £1/record, or roughly ¥10 CNY)
- Processing time: ~10 minutes/record
The advantage of Opus is that it proactively investigates ambiguous areas one or two extra times to satisfy its own standards for accuracy and quality. This behavior stems from Opus's strong instruction-following and implicit reasoning capabilities as Anthropic's flagship model — even when task descriptions are imprecise, it can "guess" the user's true intent and proactively fill in missing judgment logic.
Approach 2: Open Code + DeepSeek V4 Flash
Using the Open Code run command with the DeepSeek model dramatically reduces costs but also noticeably degrades quality. Open Code is an open-source command-line AI coding assistant, similar to Claude Code but supporting multiple model backends.
DeepSeek is a family of large language models developed by the Chinese company DeepSeek. DeepSeek V4 Flash is their cost-effective model released in 2025, built on a Mixture of Experts (MoE) architecture that activates only a subset of parameters during inference. This maintains high performance while significantly reducing computational costs. DeepSeek's API pricing is far lower than Anthropic's and OpenAI's — input token prices are roughly 1/50 to 1/100 of Claude Opus. The Flash version further optimizes inference speed, making it particularly suitable for high-volume data processing scenarios.
- Quality: ~80%-85% accuracy with small data volumes (10K-20K tokens); quality drops sharply in complex scenarios
- Cost: Approximately 1/30 to 1/70 of Approach 1 (i.e., relative cost of ~1.5-3)
- Processing time: Faster (Flash model advantage)
The problem is that for complex data scenarios, the reliability of extraction results drops significantly — to the point where you "wouldn't dare use it."
Approach 3: Claude Code + DeepSeek (Recommended)
Running the DeepSeek model within the Claude Code framework is the high-value approach recommended in this article.
- Quality: Near Opus level; with optimized prompts, achievable at 88%-90%
- Cost: Comparable to Approach 2 — over 30x cheaper than Opus
- Processing time: Faster than Opus
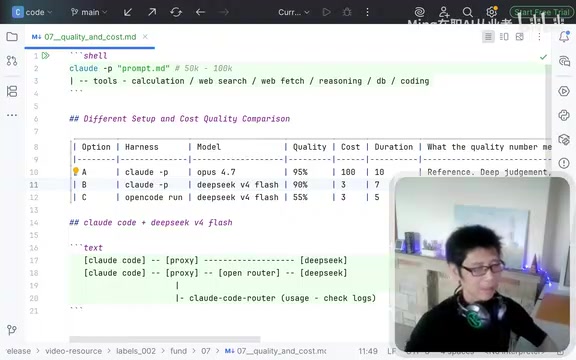
Key finding: The same DeepSeek model performs significantly better when run within the Claude Code framework compared to Open Code. This is because Claude Code and Open Code differ substantially at the framework level — Claude Code includes carefully designed system prompts, multi-turn conversation management strategies, error retry mechanisms for tool calls, and intelligent context window compression algorithms. These framework-level optimizations act as "scaffolding" for the model, guiding a less capable model along a more optimal task completion path. The framework's orchestration capabilities largely compensate for the model's own reasoning gaps, which is why the same model can perform vastly differently across different frameworks.
How to Configure Claude Code to Use DeepSeek
Core Principle: API Format Conversion
DeepSeek's API response format is compatible with OpenAI's but completely different from Claude's. Anthropic's Claude API uses its own Messages API format, which differs significantly from OpenAI's Chat Completions API format in request structure, role definitions, tool call protocols, and more. For example, Claude uses content block arrays to organize multimodal content, while OpenAI uses a flatter message structure. Therefore, to have Claude Code call DeepSeek, you need an intermediary layer for format conversion.
The specific solution uses a tool called Claude Code Router:
- Claude Code sends an API request (in Anthropic Messages API format)
- The request goes not directly to DeepSeek, but to the local Claude Code Router
- The Router converts the request format to OpenAI-compatible format and forwards it to OpenRouter or the DeepSeek API
- The response data is converted back and returned to Claude Code
Claude Code Router is essentially a locally running API proxy server. This proxy-based conversion approach is widely used in the open-source community, with similar tools including LiteLLM and others. OpenRouter is a platform that aggregates APIs from multiple model providers, offering a unified API endpoint to access hundreds of different models, often at better prices than direct API calls.
Once configured, the Claude Code interface still shows Opus 4.7 as the active model, but the actual backend calls go to DeepSeek V4 Flash. To verify which model is actually being used, you need to check the log files in a specific folder on your machine.
Prompt Optimization: The Key to Bridging the Model Gap
Defining Boundaries
When replacing Opus with DeepSeek, the quality gap primarily shows up in ambiguous judgment calls. This highlights the special significance of Prompt Engineering in model substitution scenarios. High-end models like Claude Opus have stronger instruction-following and implicit reasoning capabilities — even with vague prompts, they can infer the user's true intent. Less capable models require more explicit, more structured instructions.
The solution is to define boundary conditions more clearly in your prompts. This practice is known in the industry as "prompt downgrade adaptation": when migrating from a high-end model to a lower-end one, you compensate for the model's reduced capabilities by increasing prompt precision. You transform the implicit knowledge that previously relied on the model's autonomous judgment into explicit rules in the prompt, finding the optimal balance between cost and quality.
Prompt Writing Principles
- Define clear objectives: Tell the model exactly what you want to accomplish
- Define boundaries: Provide explicit definitions for ambiguous concepts (e.g., "What counts as a funding round?" — Is it divided by funding stage, time window, or investor changes? All need to be explicitly stated in the prompt)
- Minimize implementation details: Don't tell the model how to write regex or handle decimal points — the model is better at these things than humans
- Iterate and optimize: If results go in the wrong direction at the boundaries, ask the model to help you figure out adjustments
An important mindset: don't try to "teach" the LLM how to handle technical details. Models have been trained on vast amounts of data and are often better than humans at the operational level. Our job is to clearly communicate "what to do" and "where the boundaries are," while leaving the "how to do it" freedom to the model itself. This principle applies not just to DeepSeek but serves as universal guidance for prompt writing across all large language models.
Summary and Recommendations
| Approach | Quality | Cost (Relative) | Speed |
|---|---|---|---|
| Claude Code + Opus | 90-95% | 100 | Slow |
| Open Code + DeepSeek | 80-85% (unstable) | 1.5-3 | Fast |
| Claude Code + DeepSeek | 88-90% | 1.5-3 | Fast |
Recommended strategy: Use the Claude Code + DeepSeek V4 Flash combination with carefully optimized prompts to maintain near-Opus quality while reducing costs by over 30x. For high-volume data processing tasks, this cost difference is decisive — processing 1,000 records as an example, the Opus approach costs approximately £1,000, while the DeepSeek approach costs only £15-30. The savings are more than enough to cover additional prompt optimization and quality review costs.
It's worth noting that this "swap-under-the-hood" usage may not fully comply with Claude Code's terms of service, so you should assess the risks yourself. Additionally, DeepSeek's API service stability and data privacy policies are factors to consider in production environments.
Key Takeaways
Related articles

CodeGraph: The 50K-Star Open-Source Tool That Cuts AI Coding Token Usage in Half
CodeGraph is a 50K-star open-source tool that builds a code knowledge graph so AI coding assistants can locate code instantly—cutting Token usage by 47%, boosting speed by 22%, all running 100% locally.

VibeCoding Beginner's Guide: A Complete Guide to Building Software with Natural Language from Scratch
VibeCoding lets anyone build software through natural language conversations with AI. Learn the core concepts, learning path, and practical methods to get started.
Using UU Accelerator to Speed Up Cursor: A Compliant Solution for Stable AI Coding in China
Learn how to use NetEase UU Accelerator to speed up Cursor AI coding tool in China, with step-by-step setup including node selection and launch configuration.