Claude Code + Skills: A Practical Guide to 10x AI-Driven Test Case Generation
Claude Code + Skills: A Practical Guid…
Achieve 10x test case generation efficiency through Claude Code Skill encapsulation
This article introduces an AI-driven software testing approach based on Claude Code + Skill encapsulation. The core idea is encoding testing expert experience into structured Skill rule systems, leveraging Claude Code's multimodal capabilities to parse visual information like flowcharts in requirements documents, achieving full-process automation from requirements parsing, case generation, and review verification to script writing. Real-world cases show this approach can boost test cases from 33 to 400+, transforming the test engineer's role from manual case writing to AI commanding.
Introduction: A Cognitive Upgrade for the Testing Industry
Still writing test cases manually? Still dumping requirements documents into a generic AI chatbox, hoping it'll spit out high-quality test points? If your AI usage is still stuck at the "glorified search engine" stage, you might be falling behind in the efficiency race.
This article introduces a full-process AI-driven software testing approach based on Claude Code + Skills encapsulation. The core idea: Don't just "use" AI—learn to "train" AI. By encapsulating testing experts' experience into reusable Skills, AI evolves from a simple chatbot into a 24/7 super testing assistant.
Setting Up the Foundation: Standing on the Shoulders of Giants
Many test engineers follow this learning path: spend months grinding through Python syntax, slowly learn automation frameworks, and finally touch AI tools. This path is far too slow today.
The foundational stage only requires one thing—assembling your toolchain. The core tool is Claude Code, supplemented by various AI-assisted tools to directly build an efficient testing environment.

The traditional approach is to dump requirements documents into a generic AI chatbox and let it read the text. But here's the problem: it can't even see diagrams and flowcharts. A huge portion of business logic in requirements documents is expressed through flowcharts and state diagrams. A plain-text chatbox simply cannot understand this visual information, and the twenty or thirty test cases it produces are essentially useless.
Claude Code is Anthropic's AI programming assistant designed for developers. Its multimodal capabilities are built on Vision-Language Models (VLM). Unlike pure-text LLMs, VLMs can simultaneously process image and text inputs, converting images into vector representations the model can understand through visual encoders, then fusing them with textual information for reasoning. This enables Claude Code to "read" UML flowcharts, state machine diagrams, swimlane diagrams, and other visualized business logic in requirements documents—content that traditionally requires senior test engineers to spend significant time interpreting manually. This multimodal understanding capability is the technical starting point for achieving a qualitative leap in automated test case generation.
Skill Encapsulation: The Core Method for AI Test Case Generation
What Is a Skill? Why Does It Determine Test Case Quality?
A Skill here isn't some off-the-shelf plugin—it's a practice of encoding testing methodologies and expert experience into structured rules. Think of it as writing a "work manual" for AI—telling it what steps to follow and what standards to apply when facing different types of requirements.
From a technical perspective, Skill encapsulation is an advanced form of systematic Prompt Engineering. Prompt Engineering refers to the technical practice of carefully designing input prompts to guide AI models toward desired outputs. The beginner stage involves single-conversation prompt optimization; the intermediate stage is Few-shot Learning, where examples guide the model; Skill encapsulation enters the advanced stage—structurally encoding domain expert knowledge, execution steps, quality standards, and output formats into reusable "expert programs." This is highly consistent with the function encapsulation concept in software engineering: abstracting complex logic into callable units, lowering the barrier to use, and improving reusability.
Without Skill encapsulation, AI is just a chatbot; with it, AI becomes your super intern.
Real-World Results: 33 vs. 400+ Test Cases
Let's look at a real case. This is a multi-page requirements document for an Air China business project—complex logic with numerous flowcharts and business rules.
Feeding this document to Claude Code and activating the pre-written Skill system produced:
- 370 test cases, output in tabular format
- XMind mind map generated with one click
- Fully automated end-to-end
During the process, the AI automatically executed these steps:
- Auto-parsed PDF/Word document content
- Split requirements by module, building a structured requirements tree
- Interpreted diagrams, identifying branches and boundary conditions in flowcharts
- Auto-conducted requirements review, checking completeness and consistency
- Coverage verification, ensuring test points covered all requirement items
Each step was directed by pre-written Skills commanding the AI, not by a single vague prompt.
A more intuitive comparison: with the same document, generic AI produced only 33 bare-bones checklist items, while the Skill system delivered 400+ test points that passed case review. This isn't a 10% improvement—it's a 10x+ efficiency gap.
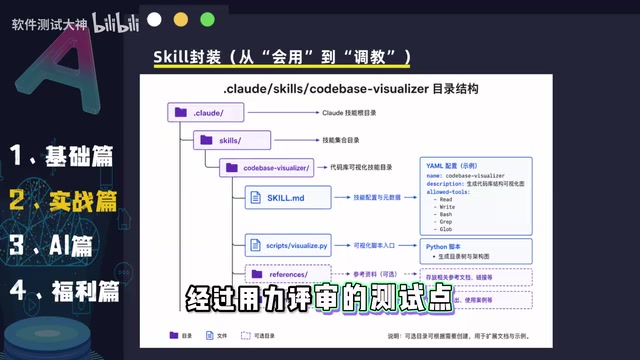
The Four-Layer Core Architecture of Skill Encapsulation
A well-designed testing Skill system typically includes these layers:
- Requirements Parsing Skill: Defines how to decompose requirements documents in different formats, how to identify functional points, business rules, and exception scenarios
- Case Generation Skill: Defines granularity standards, naming conventions, priority classification rules, and application strategies for test design methods like equivalence partitioning and boundary value analysis
- Review & Verification Skill: Defines coverage check rules, redundant case identification, and logic for supplementing missed scenarios
- Output Format Skill: Defines templates and specifications for outputting to Excel spreadsheets, XMind mind maps, or other formats
It's worth noting that the Equivalence Partitioning and Boundary Value Analysis involved in the case generation Skill are the most classic black-box test design methods in software testing, systematically proposed by Glenford Myers in his 1979 book The Art of Software Testing. Equivalence partitioning divides the input domain into equivalent intervals where values within each interval have equivalent effects on program behavior, requiring only representative values for testing. Boundary value analysis focuses on values at interval boundaries, since most defects concentrate at boundary conditions. Once these methodologies are encoded into Skills, AI can automatically identify input field data types and constraints, systematically generating three categories of test data—normal values, boundary values, and abnormal values—replacing the manual derivation process of test engineers.
These Skills are essentially structured expressions of testing experts' years of experience. Once encapsulated, they can be reused across teams, enabling everyone to produce expert-level test cases.
From Test Executor to AI Commander: Agent Workflow in Practice
Agent Workflow—The Ultimate Form of Test Automation
Once the Skill system matures, the next step is building Agent Workflows. Agent Workflow is a cutting-edge AI application paradigm whose core is giving AI autonomous "plan-execute-reflect" loop capabilities. Technically, it relies on the ReAct (Reasoning + Acting) framework, Tool Use/Function Calling, and multi-agent collaboration mechanisms. In testing scenarios, a complete Agent Workflow might include: a Requirements Parsing Agent, a Case Generation Agent, a Code Generation Agent, and an Execution Report Agent, with structured data passing context between agents to form a pipeline. The fundamental difference from traditional RPA (Robotic Process Automation) is that Agents possess semantic understanding and dynamic decision-making capabilities, rather than merely executing fixed rule scripts.
This means AI can not only generate test cases but also:
- Automatically generate Postman API test scripts
- Automatically write Selenium Web automation code
- Automatically produce Appium mobile test code
- Automatically execute tests and generate reports
Postman, Selenium, and Appium represent mainstream tools across three testing layers. Postman is the industry-standard tool for API interface testing, supporting test case management through Collections and Environments, with CI/CD integration via Newman. Selenium is the cornerstone framework for Web UI automation, controlling browser behavior through the WebDriver protocol with multi-language bindings including Python and Java. Appium is the unified framework for mobile automation testing, achieving cross-platform mobile app testing by wrapping iOS's XCUITest and Android's UIAutomator2. The technical feasibility of AI auto-generating these three types of scripts is built on the foundation that these frameworks have massive amounts of open-source code as training data, enabling models to understand test case intent and map it to corresponding API call sequences.
The Role Transformation of Test Engineers
Today's companies don't just want you to know testing—they want you to know how to train AI. Your role is shifting from "the person who writes test cases" to "the AI commander who gives orders."
This transformation requires three core competencies:
- Deep understanding of testing methodologies—you need to know what makes a good test case before you can teach AI to write one
- Skill encapsulation ability—converting tacit experience into explicit rules
- Workflow orchestration ability—chaining multiple Skills into end-to-end automated processes
When you can build such a system within your company, you're no longer just a test engineer—you're the technical architect of the testing team.
Summary: The Core Logic of AI-Driven Testing
The core logic of this approach is actually quite simple:
| Layer | Traditional Approach | AI-Driven Approach |
|---|---|---|
| Requirements Analysis | Manual reading, manual decomposition | AI multimodal parsing, automatic module splitting |
| Case Design | Written by hand based on experience | Skill-driven, standardized generation |
| Case Review | Manual review | AI auto-checks coverage and quality |
| Script Writing | Manual coding | AI auto-generates based on cases |
AI won't replace test engineers, but test engineers who can use AI will replace those who can't. And the standard for "can use" has evolved from simple prompting to Skill encapsulation and Agent orchestration.
If you're still hesitating about whether AI-generated test cases are "usable," try a different perspective: it's not that AI isn't capable—it's that you haven't learned how to command it properly.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.