Claude Code Sub-Agent: A Practical Guide to Multi-Agent Collaboration for Enhanced Development Efficiency
Claude Code Sub-Agent boosts multi-agent collaboration efficiency through task decomposition and specialization
Sub-Agent is Claude Code's mechanism for delegating complex tasks to multiple specialized agents, each with independent prompts, tool permissions, and task instructions. It solves single-Agent instruction loss, context bloat, and cost explosion through task splitting. Currently limited to linear execution with non-shared context, the future parallel multi-agent mode promises transformative efficiency gains.
What is a Sub-Agent?
Claude Code's Sub-Agent mechanism refers to a system where a Master Agent orchestrates and delegates complex tasks to multiple predefined, specialized agents for execution. Each Sub-Agent has its own independent system prompt, tool permissions, and task instructions—essentially a dedicated "expert" for a specific domain.
This aligns perfectly with the "Single Responsibility Principle" commonly referenced in software engineering—rather than having one general-purpose Agent handle everything, multiple specialized Agents each take ownership of their respective domains. This design philosophy has deep historical roots in software architecture: from Distributed AI research in the 1980s to the rise of Microservices architecture in the 2010s, engineers have consistently explored optimal "divide and conquer" solutions. The Sub-Agent mechanism brings this thinking into the LLM era, where each agent functions as a "cognitive microservice"—with independent responsibility boundaries, independent runtime context, and standardized input/output interfaces.
Practical Case Study: Blog Writing + Git Commit
Division of Labor Between Two Agents
Here's a concise but typical example: defining two Sub-Agents—Blog Writing and Commit Push. The user only needs a brief instruction like "Fix the blog with Blog Writing, then Commit," and the entire workflow chains together automatically.
The execution process works as follows:
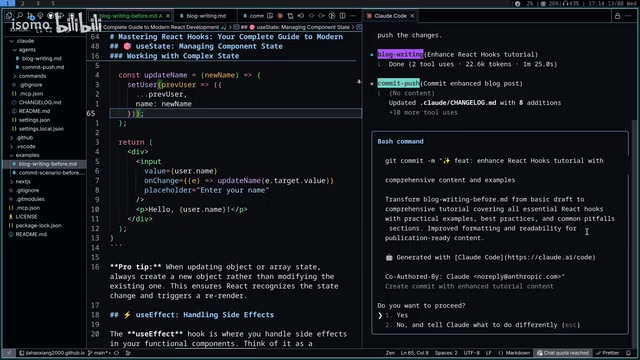
- Blog Writing Agent is triggered and polishes/rewrites the blog content according to predefined writing style and standards, including using bold and italic formatting to highlight key content, enhancing expression with emojis, etc.
- Once the blog fix is complete, Commit Push Agent takes over, automatically scanning the modifications, generating a commit message with emoji prefixes, updating the changelog, and finally pushing to the remote repository.
Agent Definition Structure
Each Sub-Agent definition contains several core elements:
- Name: The Agent's unique identifier
- Description/Summary: Similar to an MCP Server's function description, it tells the Master Agent what this sub-agent can do, what input it accepts, and what output it produces
- System Prompt: Defines the Agent's role, responsibilities, and specific execution steps
- Tool Permissions: Which tools the Agent is allowed to use
This structure closely resembles the Tool description mechanism in MCP—the Master Agent reads descriptions to determine which Sub-Agent to invoke, just as an LLM uses Tool Descriptions to decide which tool to call. It's worth noting that the quality of these "descriptions" is crucial: the Master Agent is essentially performing semantic matching and intent routing decisions. The more precise the description, the higher the dispatch accuracy—analogous to how document annotation quality affects retrieval effectiveness in search engines.
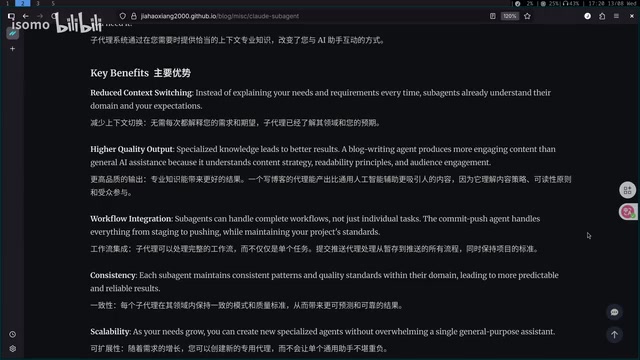
Why Do We Need Sub-Agents?
Solving the Instruction Loss Problem
When a single Agent handles complex tasks, as instructions in the prompt accumulate, the Agent tends to "forget" some of them. This phenomenon has deep architectural roots: the Transformer's Attention Mechanism suffers from an "attention dilution" effect when processing ultra-long contexts—when the input sequence is too long, the model's focus on key information gets diluted by large amounts of irrelevant content. Stanford University's 2023 research named this the "Lost in the Middle" problem, with experiments showing that models forget information positioned in the middle of the context at significantly higher rates than content at the beginning or end.
Sub-Agents address this by splitting tasks into independent contexts for execution. Each subtask has a smaller, more focused instruction set, significantly reducing the probability of instruction loss. This is essentially a Specialization strategy—rather than trying to fix the model's attention deficiencies, it architecturally circumvents them.
Alleviating Context Window Pressure
When a single Agent processes multi-step tasks, the context continuously expands. Claude Code currently supports a maximum context window of 1MB, but larger contexts bring two problems:
- Quality degradation: When context is too long, the model's processing capability for certain tasks noticeably declines
- Cost explosion: APIs charge by context tier—under 256K is the base price, exceeding 256K doubles or even triples the cost. The per-token price for 1MB context jumps from $3 to $6
The billing mechanism here deserves deeper understanding: mainstream LLM APIs use a Tiered Pricing model that fundamentally reflects the nonlinear consumption of GPU VRAM during long-context inference—Transformer's KV Cache grows quadratically with sequence length, causing infrastructure costs to spike dramatically. This cost is ultimately passed through to API pricing. Sub-Agents make each request's context smaller and more precise, saving money while improving quality.
Workflow Standardization and Reuse
Once common work patterns are solidified into Sub-Agents, you've essentially built reusable automation pipelines. The next time you encounter the same type of task, you can invoke it directly without repeatedly describing process details. This aligns with the DevOps concept of "Infrastructure as Code"—encoding human operational experience and best practices into versionable code that can be reliably reproduced and continuously iterated.
Current Limitations and Future Outlook
The Bottleneck of Linear Execution
Currently, Claude Code's Sub-Agents still operate in a Linear execution mode: the Master Agent blocks and waits after invoking a Sub-Agent until it completes, then dispatches the next one. Multiple subtasks can only be processed serially, not in parallel.
From a computer science perspective, this is equivalent to a single-threaded synchronous execution model—simple and reliable, but throughput is limited by the slowest step. For I/O-intensive tasks (like network requests, file read/write), serial waiting causes significant resource idle time—precisely why asynchronous programming and concurrency models shine in software engineering.
The Promise of Parallel Multi-Agent
What's truly exciting is the Parallel Multi-Agent mode: multiple Agents running simultaneously with Agent-to-Agent communication and coordination between them. This field is currently at a critical stage of protocol standardization—Anthropic's MCP (Model Context Protocol) and Google's A2A (Agent-to-Agent) protocol are both attempting to define standard formats for inter-agent information exchange, addressing classic distributed systems challenges like message routing, state synchronization, and conflict arbitration, while also handling the additional complexity introduced by LLM output non-determinism.
Parallel multi-agent will bring qualitative leaps:
- Efficiency gains: From several-fold to tens or even hundreds-fold improvements
- Capability breakthroughs: Simultaneous expertise across multiple domains, cross-Agent coordination, handling complex problems that even individuals or teams struggle with
- Infinite decomposition: Tasks can be broken down layer by layer, with each layer further divided into multiple sub-Agents, forming a tree-structured execution architecture
For example, if you want to create a technical video, you could have a group of Agents simultaneously handle: research collection, code writing, documentation generation, and demo video production. Each step can be further subdivided, ultimately requiring only a single topic to produce complete code, documentation, and video.
The Cost Issue of Non-Shared Context
A practical issue with current Sub-Agents is non-shared context. The Master Agent and Sub-Agents each maintain independent contexts, meaning the same information may be loaded repeatedly, doubling token consumption. In distributed systems, this corresponds to a classic problem: shared state management. Traditional solutions include shared memory, message queues, distributed caches, etc. However, in LLM scenarios, the "state" itself is unstructured natural language—how to efficiently compress, index, and retrieve context information is one of the core challenges urgently needing breakthroughs in current AI engineering. This isn't friendly for cost control and represents a direction requiring future optimization.
How to Create Sub-Agents
The creation process is quite straightforward: use the /agent command in Claude Code, then new a new Agent, and follow the guided steps to define it progressively. Claude Code can even help you auto-generate the Sub-Agent's prompts and configuration.
The key is to design the following for each Sub-Agent:
- Clear Role Definition: What does this Agent do
- Precise Task Instructions: What specific work needs to be completed
- Logical Execution Steps: What to do first, what to do next—the process must be explicit
- Necessary Constraints: Output format, quality standards, and other boundary requirements
In Prompt Engineering practice, there's an important principle when writing system prompts for Sub-Agents: the more specific, the better. Vague role definitions lead to unpredictable Agent behavior in edge cases, while precise step descriptions significantly improve output consistency and reliability. You can reference the "Chain-of-Thought" prompting technique, decomposing complex tasks into explicit reasoning steps written into the system prompt to guide the Agent along the expected execution path.
Summary
The core value of the Sub-Agent mechanism lies in: improving execution quality for each subtask and overall workflow reliability through task decomposition and specialization. Behind it is an architectural-level response to the inherent limitations of Transformer attention mechanisms, and a natural extension of software engineering's "divide and conquer" philosophy into the AI era. Although it currently operates in linear execution mode with cost issues from non-shared context, it has already demonstrated the enormous potential of multi-agent collaboration.
Before truly parallel multi-agent arrives, learning to efficiently collaborate with a dozen Sub-Agents in linear mode is the most worthwhile practical direction to invest in right now.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.