Claude Fable 5 Coding Stress Test: Three Hardcore Tasks, All Passed — Plus a Hybrid Cost-Saving Strategy
Claude Fable 5 aces three hardcore coding tasks on first attempt; hybrid DeepSeek strategy cuts costs.
A developer stress-tested Anthropic's Claude Fable 5 with three progressively harder tasks: generating 750 lines of native WebGL code from a single sentence, fixing a real repo bug in 87 seconds via root cause analysis, and producing a stable 60 FPS rigid body + cloth + fluid coupling simulation. All passed on the first try for just ~$10 in API costs. Pro/Max subscribers can use Fable 5 free until June 22, after which a Claude Fable 5 + DeepSeek hybrid workflow via OpenRouter offers a practical cost-saving path.
Anthropic released Claude Fable 5 just two days ago, and a developer has already put it through a stress test with three real-world tasks ranging from simple to complex. The results were surprising — all three tasks passed on the first attempt, with total API costs of just around ten dollars. Even more importantly, there's currently a limited-time free window that, once missed, means you'll be paying per usage.
Task A: Generating a 3D World from a Single Sentence
The first test was the most straightforward: describe a requirement in a single sentence and have Fable 5 generate an interactive 3D scene.
The result? In 16 minutes and 49 seconds, the model delivered 750 lines of native WebGL code. The tester originally requested only four materials, but the model provided 13, complete with realistic shadows and a day-night cycle system — ready to run directly in a browser.
Some important context here: WebGL (Web Graphics Library) is a JavaScript API based on OpenGL ES that allows developers to render high-performance 2D and 3D graphics directly in the browser without any plugins. Unlike wrapper libraries such as Three.js, native WebGL code requires developers to directly manipulate low-level graphics pipeline concepts like shaders, vertex buffers, and texture mapping, making it significantly harder to write. 750 lines of error-free native WebGL code means the model not only understood JavaScript syntax but also mastered GLSL shader language, matrix transformations, lighting models, and other core computer graphics concepts.
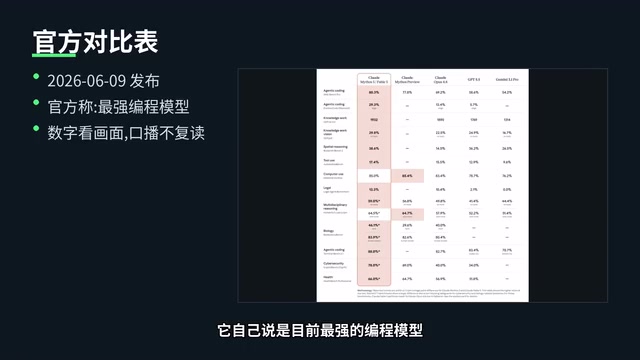
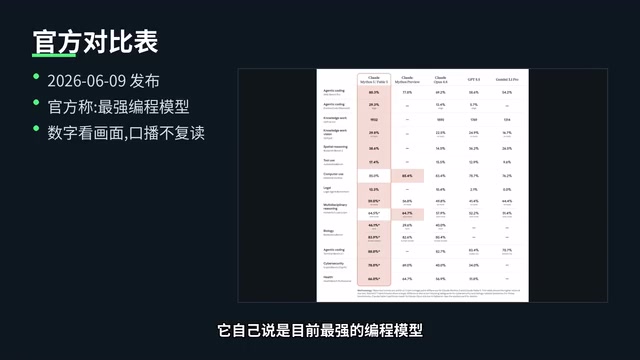
According to the comparison chart released by Anthropic, Fable 5 claims to be the strongest coding model currently available. Setting aside official marketing, judging solely from the output quality of this task — 750 lines of error-free WebGL code, material count exceeding expectations, and out-of-the-box completeness — it genuinely demonstrates impressive code generation capabilities.
Task B: Bug Fixing in a Real Code Repository
The second task moved beyond "toy scenarios" and went straight to testing with a real code repository (repo). This is the real litmus test for a coding model's practical value — can it locate and fix issues within a complex existing codebase?
In software engineering practice, real code repositories are fundamentally different from artificially constructed programming problems. Real repos typically contain dozens or even hundreds of files, complex module dependencies, legacy code, and implicit business logic conventions. Traditional AI coding assistants often perform poorly in these scenarios because they need to understand cross-file contextual relationships and the project's overall architectural intent.
Test results: Fable 5 completed the following operations in 87 seconds:
- Autonomously ran tests to reproduce the bug's trigger conditions
- Identified the root cause: found the data source issue in timezone handling
- Applied the correct fix: fixed the data source rather than applying a superficial patch at the display layer
- Bonus: discovered and cleaned up a potential risk from an outdated API endpoint
This task best demonstrates Fable 5's engineering comprehension. It didn't simply "treat the symptom" — instead, it traced the data flow back to its source for the fix, a strategy that only experienced developers typically employ. In software engineering, this approach is called a "Root Cause Fix," as opposed to a "Symptomatic Fix" — the latter may temporarily resolve the issue but often introduces new bugs elsewhere or buries deeper technical debt.
Task C: Textbook-Level Physics Coupling Simulation
The third task was the ultimate difficulty ceiling: rigid body + cloth + fluid three-way coupling simulation. In computer graphics, this is a textbook-level challenge because the interactions between the three physical systems are extraordinarily complex.
Specifically, rigid bodies, cloth, and fluid belong to three fundamentally different physical simulation paradigms. Rigid body simulation is based on Newtonian mechanics and collision detection; cloth simulation typically uses mass-spring models or finite element methods, requiring handling of numerous constraints; fluid simulation commonly employs SPH (Smoothed Particle Hydrodynamics) or Eulerian grid methods. Coupling all three means they must exchange force and displacement information in real time — for example, fluid pushing cloth, cloth wrapping around rigid bodies, rigid bodies stirring fluid — which causes numerical stability issues to escalate dramatically. In industry, this type of coupled simulation is typically handled by specialized engines like Houdini or NVIDIA PhysX. Being able to generate it with pure code in one shot and have it run stably at 60 FPS is genuinely an extremely difficult task.

You might not have noticed, but Fable 5 proactively declared "not verified by execution" in the header of the generated file. This kind of honest self-annotation is a good sign — the model is aware of its own capability boundaries.
But the actual verification result was: 14 minutes and 13 seconds, passed on the first try, stable 60 FPS. The model's "humble" disclaimer and its actual performance created an interesting contrast.
Cost Analysis: Just Around Ten Dollars for Three Tasks
The total API cost for all three tasks was only around ten dollars — not hundreds, just around ten. For this level of code output volume and quality, the cost-effectiveness is quite remarkable.

But what's more important is the current window period strategy:
- Before June 22: Pro and Max subscribers can use Fable 5 directly at no additional charge
- Starting June 23: Usage-based billing kicks in
This means right now is the best time to experience Fable 5 at zero marginal cost.
Post-Window Cost-Saving Strategy: Claude Fable 5 + DeepSeek Hybrid Workflow
After the free period ends, heavy users can consider a practical hybrid strategy:
- Claude Fable 5: Handles architecture design and complex logical reasoning
- DeepSeek V4: Takes on repetitive, high-volume code implementation
This isn't a replacement relationship — it's a division of labor. The logic behind this strategy is: architecture design and complex reasoning demand the highest "intelligence ceiling" from a model, making it suitable for the strongest model available; while large amounts of boilerplate code writing, unit test generation, documentation completion, and similar tasks have relatively lower capability requirements and can be handled by a more cost-effective model.
Switching is simple too — just modify two environment variables, and you can call DeepSeek directly using an OpenRouter key without even needing to register a separate account. OpenRouter is an AI model aggregation gateway that provides a unified API interface to access large language models from multiple providers, including Anthropic's Claude series, DeepSeek, Meta's Llama, and more. Developers only need a single OpenRouter API Key and can switch between different underlying models by changing the model name parameter in their requests, without separately registering accounts on each platform or managing multiple sets of keys. If you prefer a graphical interface, there's also an open-source tool called CC Switch you can use.
However, there's one pitfall to watch out for: don't try to confirm a successful switch by asking the model "who are you." The tester tried this twice — the model claimed to be Fable 5 one time and only honestly admitted to being DeepSeek the second time. This phenomenon relates to a known limitation of large language models: a model's self-identity awareness is unreliable. LLM responses are generated based on statistical patterns in training data, and when asked "who are you," the model may tailor its answer based on conversation context, system prompts, or even the user's phrasing tendencies, rather than reflecting its true model identity. The correct verification method is to check the status bar in the lower left corner and the backend billing records — billing doesn't lie. The model identifier field returned by the API and the model name in billing records are the objectively reliable indicators.
Summary and Action Items
Fable 5 has genuinely demonstrated top-tier coding capabilities: from a simple one-sentence requirement to complex physics coupling simulation, all three tasks of increasing difficulty passed on the first attempt. Even more impressive is its engineering-level depth of understanding when fixing bugs in a real codebase.
Action Items:
| User Type | Recommendation |
|---|---|
| Existing Pro/Max subscribers | Try it before June 22 — zero additional cost |
| Heavy developers | After June 23, adopt the Claude Fable 5 + DeepSeek hybrid workflow |
| Casual users | Wait and see — let the community accumulate more best practices |
The window is limited — it's worth getting hands-on early to verify for yourself.
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.