Claude Fable 5 Hands-On: Is Doubling the Tokens Worth It? A Rust Programming Comparison with Opus 4.8
Claude Fable 5 uses twice the tokens of Opus 4.8 but delivers only marginal coding improvements.
A hands-on Rust simulation project comparison reveals that Claude Fable 5 consumes twice the tokens of Opus 4.8 while delivering only slightly better output quality. Both models compiled Rust code on the first attempt, but Fable 5 showed stability issues with post-launch safety rule changes causing task refusals. The verdict: stick with Opus 4.8 for daily coding and reserve Fable 5 for tasks where Opus falls short.
Introduction: Fable 5 Is Here, But Is It Worth Switching?
Shortly after releasing Opus 4.8, Anthropic introduced yet another member of its fifth-generation model family — Fable 5. According to official documentation, this model consumes twice as many tokens as Opus during operation. This raises a very practical question: is the performance improvement enough to justify the doubled token consumption?
In the world of large language models, tokens are the fundamental unit of computational cost. One token corresponds to roughly 4 characters in English or 1–2 Chinese characters. When Anthropic says Fable 5 consumes twice the tokens, it means the model performs more "thinking steps" during its internal reasoning process — a mechanism commonly known as "Extended Thinking" or "Chain of Thought." Before generating a final answer, the model conducts extensive internal reasoning and self-verification, and all these intermediate reasoning steps consume tokens. For API users billed by token, this directly translates to doubled costs.
A Bilibili content creator focused on AI-assisted programming put Fable 5 and Opus 4.8 through a head-to-head comparison using a Rust simulation project. The results surprised many.
Test Setup and Task Design
How to Enable Fable 5 in Claude Code
To use Fable 5 in Claude Code, you first need to update Claude Code to the latest version by running a simple cloud update command. After the update, Fable 5 will appear in the model selection interface. You may not have noticed, but Anthropic reminds users once again on the selection screen: this model consumes twice the tokens of Opus.
Test Task: A Rust Simulation Project
For a fair comparison, the creator designed a brand-new task — building a simulation program in Rust. The task had several key characteristics:
- Language requirement: Must be written in Rust (a significant challenge for model coding ability)
- Parameter complexity: Must support a large number of configurable parameters
- Reference implementation: The creator had previously completed a reference version manually, serving as an evaluation benchmark
Choosing Rust as the test language carries special evaluation value. Rust is a systems-level programming language known for memory safety and zero-cost abstractions, originally developed by Mozilla Research starting in 2010. Unlike Python or JavaScript, Rust features a strict Ownership System, Borrow Checker, and Lifetime mechanisms — the compiler rejects code with memory safety issues at compile time. This means AI-generated Rust code must pass extremely rigorous compilation checks to run, and any oversight in memory management results in compilation failure. Whether Rust code compiles on the first attempt is therefore a high-bar test for AI programming capability.
This task has been added to the creator's public repository, and interested developers can experiment with it themselves.
Fable 5 vs. Opus 4.8: The Full Comparison
Step 1: Planning Phase Comparison
Both models were asked to enter Planning Mode first and create an implementation plan for the project.
Planning Mode is an important feature in Claude Code that requires the model to draft a detailed implementation plan before writing any code. This design philosophy stems from the software engineering principle of "design before implementation." In practice, the quality of the planning phase often determines the architectural soundness of the final code. A good plan should include module decomposition, data structure design, interface definitions, and implementation order. Plans that are too brief may leave the implementation directionless, while overly verbose plans may contain redundant information that increases comprehension overhead.
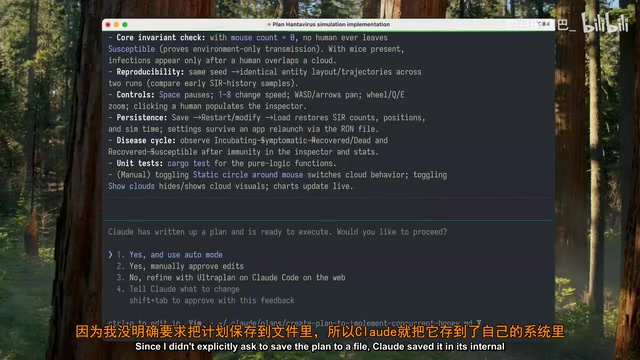
Opus 4.8's performance:
- Proactively asked several clarifying questions during planning
- Completed the plan within a few minutes
- The plan had a clear overall structure — not highly detailed but well-organized
- Saved the plan in an internal folder
Fable 5's performance:
- Generated a plan with more technical details
- The plan was more than twice the length of the Opus version
- However, the creator felt it was inferior to Opus's version in terms of structure and readability
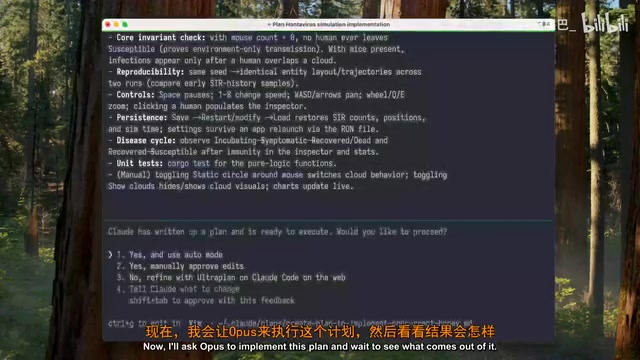
Interestingly, the two models produced noticeably different plans, which at least demonstrates that Fable 5 is not simply a thin wrapper around Opus. The difference in planning styles between the two models in this test reflects different trade-off strategies between "deep thinking" and "concise expression" in AI models.
Step 2: Code Implementation Phase
After planning, both models were asked to implement the project according to their respective plans. The implementation process was mostly automated code generation, with occasional user authorization required for certain operations.
Unexpected Incident: Fable 5's Stability Issues
During post-production editing, the creator revealed an important detail: he had originally completed the test just a few hours after Fable 5's release. But when he tried to re-run the test the next day to capture additional video footage, Fable 5 refused to execute the same task.
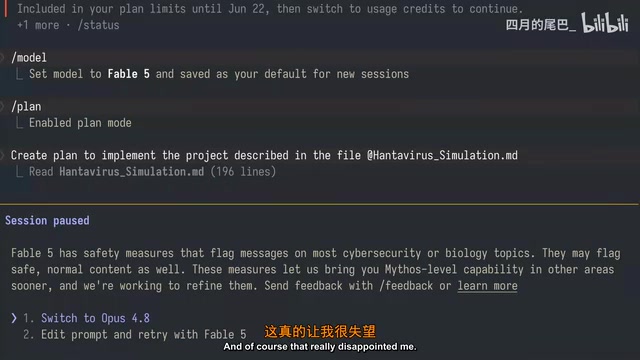
Since the project description file hadn't been modified, the creator suspected that Anthropic had adjusted the model's built-in safety rules after launch. This phenomenon reflects a common practice in the AI industry — continuous post-launch safety tuning. After a large language model is released, operations teams continuously monitor and adjust the model's safety filtering rules (commonly called Safety Filters or Guardrails) based on real user data. These rules determine which types of requests the model will refuse. Since the word "simulation" can trigger safety filters in certain contexts (e.g., disease spread simulation, weapons simulation, and other sensitive scenarios), Anthropic may have tightened related rules after release. While such dynamic adjustments are made for safety reasons, they introduce unpredictability for developers — a prompt that worked yesterday might be rejected today. This is a real challenge for AI tools in production environments.
This issue significantly reduced the creator's willingness to use Fable 5. However, since the first day's test was successfully completed, he still based his comparison on those initial results.
Final Output Comparison
Opus 4.8's Output
- ✅ Compilation: Passed on the first attempt with no errors
- ✅ Feature completeness: Simulation ran correctly, all required control parameters were implemented
- ⚠️ Visual effects: The infection cloud was much larger than expected (but easy to fix)
- ⚠️ UI aesthetics: The interface was rough, but acceptable for a first version
Fable 5's Output
- ✅ Compilation: Also passed on the first attempt with no errors
- ✅ Feature completeness: Simulation ran correctly, all required settings were included
- ✅ Visual effects: The infection cloud and overall simulation looked better
- ⚠️ Limited gap: While overall better than Opus, the difference was not significant
It's worth noting that both models generated Rust code that compiled on the first attempt. Given the strictness of the Rust compiler, this result alone demonstrates that current top-tier AI models have reached a remarkably high level in code generation.
Overall, Fable 5's output quality was slightly better, but the improvement was far from "doubled."
Core Conclusion: Doubled Tokens, Far from Doubled Results
Not Recommended for Everyday Programming
The creator's final verdict was unequivocal: for everyday programming tasks, switching from Opus 4.8 to Fable 5 is not worth it. Here's why:
- Limited performance improvement: In the Rust simulation project, Fable 5's output quality was only marginally better than Opus 4.8 — far from justifying twice the token consumption
- Questionable stability: The model refused to execute tasks shortly after release, suggesting Anthropic may still be adjusting the model's behavioral boundaries
- Poor cost-effectiveness: For most everyday programming scenarios, Opus 4.8 is already more than capable
Where Fable 5 Might Shine
That said, the creator also identified scenarios where Fable 5 could be valuable: when Opus fails to complete a task, try using Fable 5 to tackle it. In other words, Fable 5 is better suited as a "backup heavy artillery" rather than a daily workhorse.
This product philosophy of "trading more compute for better results" is similar to OpenAI's o1/o3 series models, which also invest more computation during the reasoning phase to improve performance on complex tasks — at the cost of higher latency and expense. From an industry trend perspective, these "heavy reasoning" models are becoming a standard product line across major AI companies, but they're positioned more as specialized tools for tackling high-difficulty problems rather than all-purpose replacements for general models.
Takeaways for Developers
This hands-on comparison offers several important insights:
- More tokens ≠ better results: A model consuming more computational resources doesn't mean proportionally better output quality, especially for structured programming tasks. This phenomenon is known as "Diminishing Returns" in machine learning — once computational investment exceeds a certain threshold, the marginal benefit of performance gains drops sharply
- Model selection should be context-driven: No single model fits all scenarios. The smart strategy is to choose different models based on task difficulty
- New models need an observation period: Freshly released models may undergo rule adjustments and stability issues — it's not advisable to switch over completely right away
- Planning ability matters too: In this test, Opus produced a more concise but better-structured plan, and its final implementation was no worse — proving that "more detailed" doesn't equal "better"
For most developers, the most pragmatic strategy right now is to continue using Opus 4.8 as the primary model and only try Fable 5 when hitting a bottleneck.
Key Takeaways
Related articles

The Era of Managed Agents: Anthropic vs. Google's Two Diverging Approaches
Deep analysis of Anthropic vs Google's Managed Agent architectures, pricing strategies, and selection guidance. Managed Agents are emerging as a new AI infrastructure product category.
Setting Up Claude Code from Scratch: An Installation & Configuration Troubleshooting Guide
A complete guide for beginners to set up Claude Code, covering VS Code installation, plugin troubleshooting, API configuration, model switching pitfalls, and practical usage tips.
AI Summoning Power: Insights and Practices from Zero-Code Game Development with AI
A creator with no coding experience built a complete game using only AI prompts. Explore AI summoning power, zero-code development, and what it means for PMs, developers, and everyone.