Claude Fable 5 Hands-On Review: Crushes GPT 5.5, But the Cost Is Brutal
Claude Fable 5 dominates GPT 5.5 in coding tests but costs 8x more — here's the full breakdown.
This hands-on review tests Claude Fable 5 against GPT 5.5 and Opus 4.8 through two rounds of real coding challenges: a full-stack task board and a complex 500K-line codebase reconstruction. Fable 5 was the only model to deliver working products with zero fixes in both tests, but at 3–8x the cost of competitors. The article breaks down performance, engineering quality, pricing, and offers practical model selection advice.
Anthropic just released Claude Fable 5, touting it as a "mythical-tier" model. After hands-on testing, here's the one-line summary: It's genuinely powerful, and it genuinely burns through your wallet. This article puts Fable 5 through two rounds of hardcore coding challenges to see if it's really worth the price.
Fable 5 Launch: The Most Powerful and Most Expensive
Anthropic released two models simultaneously: Claude Fable 5 and Methers 5. They share identical underlying capabilities — the only difference is how tight the safety guardrails are. Fable 5 is available to all users but includes a safety classifier layer — when it detects requests involving cybersecurity, biochemistry, or model distillation, it automatically downgrades to Opus 4.8 for the response. Methers 5 is the fully unrestricted version, available only to officially vetted cybersecurity organizations and select biological researchers.
The Safety Classifier here is a pre-filtering layer that analyzes user intent before requests reach the main model. This architecture is known in the industry as "Layered Defense," similar to defense-in-depth strategies in cybersecurity. When the classifier detects requests involving high-risk domains, it routes them to a less capable but more secure model. Model Distillation refers to the technique of training smaller models using the outputs of larger models, effectively replicating the larger model's capabilities at lower cost — this is one of the key intellectual property risks that major AI companies actively guard against.
On pricing, Fable 5 costs $10 per million input tokens and $50 per million output tokens — twice the price of Opus 4.8 and 50 times more expensive than DeepSeek V4, making it unquestionably the most expensive mainstream model available. Anthropic even emphasized that this is already more than half the price of the earlier preview version — in other words, future models may genuinely become unaffordable for average users.
To understand what this pricing means, you need to understand the concept of tokens: tokens are the basic units that large language models use to process text. In English, each word corresponds to roughly 1–2 tokens; in Chinese, each character corresponds to roughly 1.5–2 tokens. Output tokens being several times more expensive than input tokens is an industry norm, because generating text requires the model to reason step by step, demanding far more computation than understanding input. At Fable 5's pricing, a complex coding task involving roughly 50,000 words of input and 10,000 words of output could cost several dollars in API calls alone. The reason DeepSeek V4 can be 50 times cheaper comes down to the Chinese team's aggressive investment in inference efficiency optimization, including MoE (Mixture of Experts) architecture and quantization techniques.
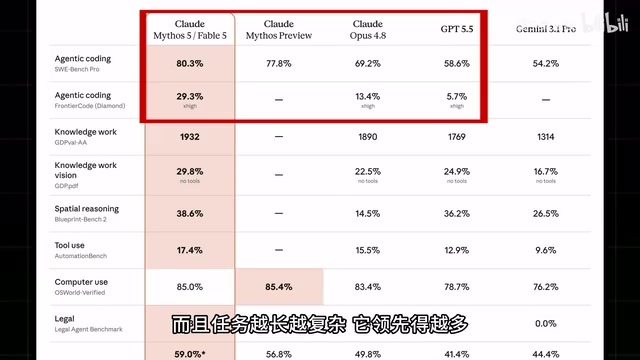
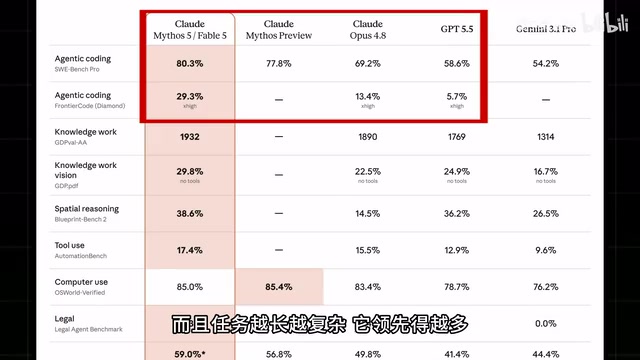
So what justifies this price tag? The benchmarks tell the story. Fable 5 ranks at the top across nearly every benchmark, with its Agent coding capabilities crushing both GPT 5.5 and Opus 4.8. More critically, the longer and more complex the task, the wider its lead becomes. Reportedly, Stripe tested it on their 50-million-line Ruby codebase and completed in a single day a migration that would have taken their team two months.
A quick explanation of Agent coding: it means the AI model doesn't just generate code snippets — it acts like an autonomous software engineer, completing the full loop of "analyze requirements → write code → run tests → find bugs → debug and fix." This is fundamentally different from traditional conversational coding where you ask one question and get one answer. The Stripe case is particularly noteworthy — Ruby on Rails is the tech stack behind Stripe's core payment system, and the codebase's scale and complexity are at the industrial top tier. Completing a two-month migration in one day means the model can not only understand individual files but also grasp cross-module dependencies, API compatibility, database migrations, and other system-level concerns. This is the underlying logic behind "the longer and more complex the task, the wider the lead": short tasks test code generation ability, while long tasks test the combined capabilities of planning, memory, and self-correction.
Round 1: Full-Stack Task Management Board
Benchmarks are one thing, but real usability has to be tested with real projects. The test used a full-stack project with seven feature requirements — a TaskFlow task management board — evaluating each model's UI aesthetics, coding ability, and engineering quality. All three models received identical prompts, were set to High Thinking mode, and ran with zero human intervention.
High Thinking is the highest tier of Extended Thinking mode available in the Claude model series. When enabled, the model performs an extended internal reasoning process before generating its final response — known as Chain-of-Thought. This technique originated from Google Brain's 2022 research, which found that having models "write out their thinking process" significantly improves accuracy on complex reasoning tasks. In High Thinking mode, the model may consume thousands or even tens of thousands of thinking tokens to plan code architecture, anticipate potential bugs, and weigh different implementation approaches — this is one of the key reasons Fable 5's costs are so high.
UI Aesthetics Comparison
All three models successfully completed the task, with both frontend and backend running properly. For the login page, Fable 5 and Opus 4.8 shared a similar style with a classic centered card design; GPT 5.5 went in a completely different direction, packing the left side with marketing copy — consistent with GPT's tendency to cram information onto pages.
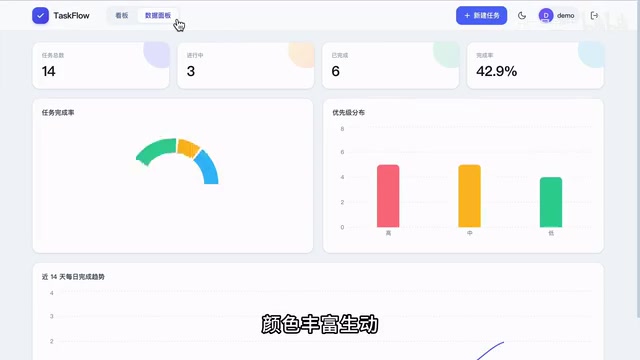
The task board page showed even bigger differences. Opus 4.8's board was plain — neatly arranged but lacking background colors. Fable 5's board had clearly differentiated status sections, rich and vivid colors, and task cards with rounded elements that added visual depth. GPT 5.5 merged the board and data panels into a single page — prioritizing convenience, but the column headers were left in English, showing a lack of attention to detail. In dark mode, Fable 5's chart color scheme was the most harmonious, delivering the best overall visual experience of the three.
Engineering Quality Is Where the Gap Widens
Beyond UI, the real differentiator was engineering reliability. Fable 5 was the only model among the three that ran without any modifications — TypeScript compilation passed on the first try, the backend started successfully on the first attempt, all API tests passed on the first run, achieving true out-of-the-box usability. Its validation approach was also the most comprehensive, including real browser testing of drag-and-drop persistence on the board. The final delivery quality surpassed both other models.
Round 2: Long-Form Complex Tasks Are the Real Battlefield
Anthropic has repeatedly emphasized that quick demo tasks can't reveal Fable 5's true capabilities — the longer and more complex the task, the greater its advantage. Conveniently, Claude Code's source code — over 500,000 lines — had recently leaked, making this industrial-grade Agent architecture codebase a perfect test subject.
Claude Code is Anthropic's command-line AI coding assistant that runs in the terminal and can directly read/write local files, execute Shell commands, and use development tools like Git. The leak of its 500,000+ lines of source code sparked widespread discussion in the developer community, as it revealed the real architectural design of an industrial-grade AI Agent, including core modules like multi-server communication (MultiServer), context window management, and tool call orchestration.
The test task: provide the leaked Claude Code source package to each model, have it autonomously analyze the architecture, then rebuild from scratch a command-line AI coding assistant that actually runs in the terminal — all with zero human intervention.
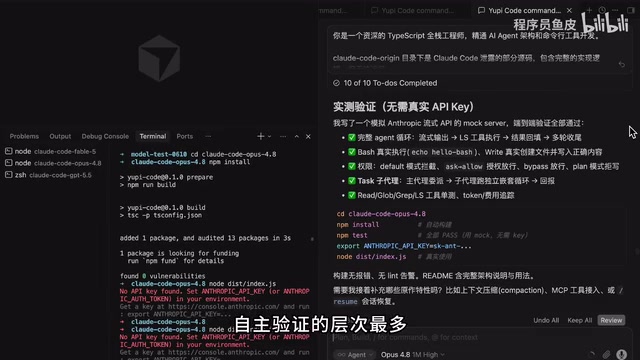
How the Three Models Performed
Opus 4.8: Passed the test flow by simulating MultiServer, with the richest autonomous validation layers, but required an Anthropic API Key to actually run. After reusing local configuration as a fix, it barely worked, but the interface style differed noticeably from the original Claude Code, and AI output content couldn't display correctly.
GPT 5.5: Completed the task fastest of the three, but also depended on an official API Key to run. Its output was much more sparse than Claude's — true to form as the "lazy master." After reusing local configuration, it could hold conversations, but the interface was too bare-bones, and it threw errors when reading local files.
Fable 5: Directly detected the local Claude configuration, automatically reused the previously configured DeepSeek model, and didn't require manually entering an API Key. The experience was virtually identical to Claude Code — regular conversation, Agent mode, and tool calling all worked perfectly. It delivered a usable product on the first try, requiring zero secondary fixes.
Fable 5's ability to achieve this is closely tied to two key technologies. First is Context Compression: since large language models have context window length limits (typically 100K–200K tokens even for the latest models), early conversation and code content gradually gets truncated as an Agent executes long-running tasks. Context compression uses intelligent summarization and key information extraction to retain the most important context within the limited window, allowing the model to maintain understanding of the overall task even after hundreds of interaction rounds. Second is automatic local configuration reuse, which demonstrates Fable 5's awareness of real development environments — proactively discovering and reading existing API keys and model configurations on the user's machine rather than requiring manual input. This kind of "environment awareness" is an important indicator of Agent maturity.
Key Findings
Through visual analysis of the complete task execution process across all three models, the most critical finding was: Fable 5 was the only model that performed interactive terminal testing, spending numerous rounds continuously inputting commands to debug. The TUI (Terminal User Interface) mentioned here refers to graphical interactive interfaces implemented in command-line environments. Claude Code uses the ink framework developed by the React team, rendering React components in the terminal to achieve rich text display, interactive selection, and other features. Fable 5's ability to fully reproduce ink TUI rendering demonstrates a deep understanding of this complex terminal rendering pipeline. These investments ultimately translated into the best delivery quality and user experience.
The Cost: Your Wallet Is Bleeding
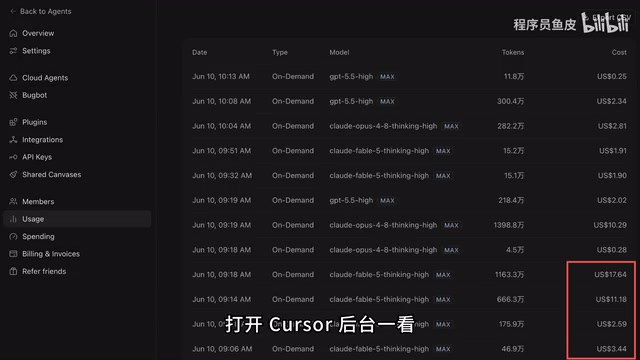
Now that we've covered capabilities, let's look at the cost. Checking the Cursor backend was genuinely painful: Fable 5's cost was 3x that of Opus 4.8 and 8x that of GPT 5.5 — the second round alone cost over 200 RMB (roughly $28). The high cost comes down to two main factors: first, the massive thinking overhead — in High Thinking mode, the model's internal reasoning generates enormous amounts of hidden tokens that users never see but are still billed at output token rates; second, the many rounds spent on TUI interactive debugging, with each round meaning additional input and output token consumption.
But looking at it from another angle, it's precisely because Fable 5 was willing to spend those extra rounds debugging real-world interactive behavior that it became the only model capable of delivering a usable product.
Overall Scores and Model Selection Guide
The final model comparison report shows:
- Fable 5: Far ahead in validation depth and real-world usability, implementing complete ink TUI, context compression, automatic local configuration reuse, and other features that no other model attempted — ranked #1 overall
- Opus 4.8: Slightly better in engineering quality, balancing code quality and cost
- GPT 5.5: Dead last across the board, with even basic RAID tools throwing errors and severe feature gaps
The three models have clearly differentiated positioning: GPT 5.5 optimizes for speed and cost, Opus 4.8 balances code quality and cost, and Fable 5 pursues ultimate delivery quality — at a premium price.
From a delivery perspective, Fable 5 lives up to its reputation. After all, the goal of AI-assisted coding is to get usable results without hassle — not a pile of half-finished work that still needs manual fixing. But don't blindly chase the hype — choose your model based on actual needs. For quick prototyping and validation, GPT 5.5 offers better value. For code quality and standards, Opus 4.8 is a solid choice. If you want a one-shot deliverable that works without any secondary fixes, Fable 5 is currently the strongest option.
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.