Claude Opus 4.8 Released: Comprehensive Upgrades in Nuanced Understanding and Conversational Naturalness
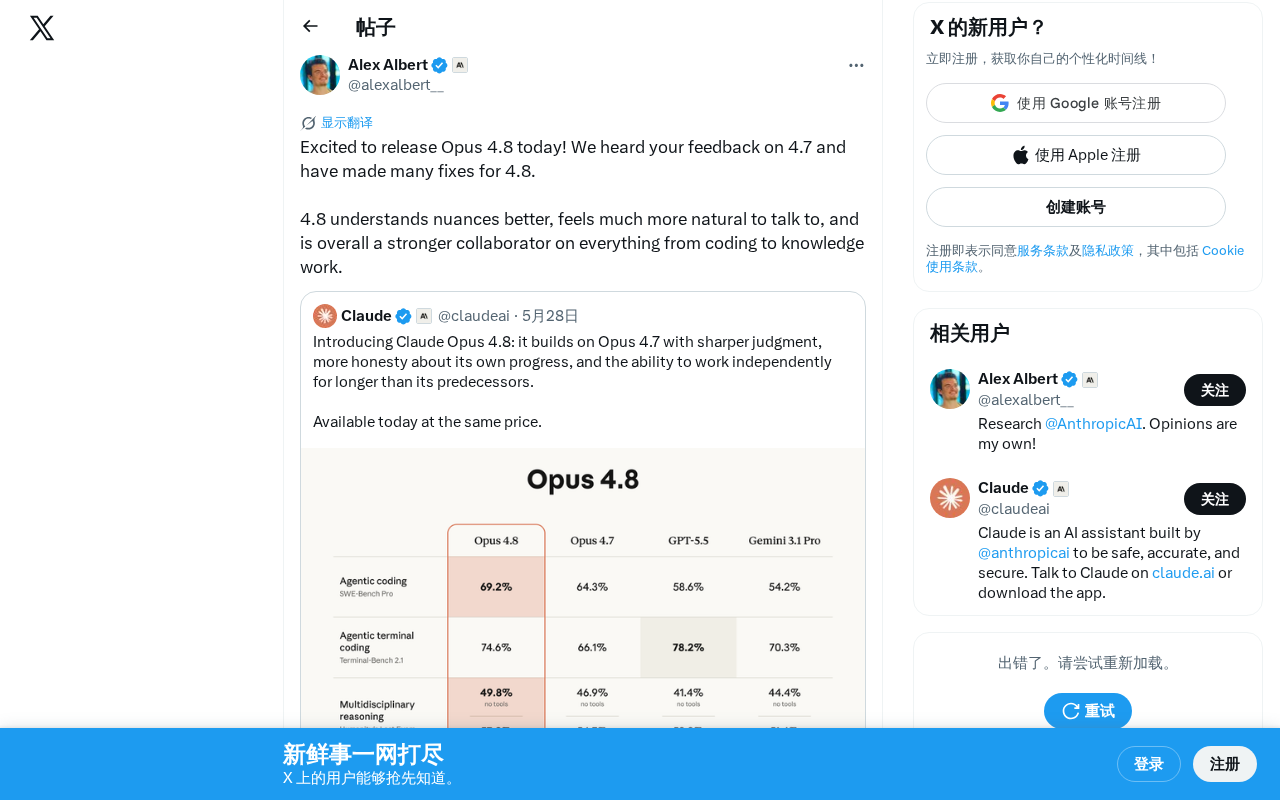
Anthropic releases Claude Opus 4.8 with systematic upgrades in nuance understanding, naturalness, and collaboration.
Anthropic officially released Claude Opus 4.8, incorporating systematic improvements based on user feedback from version 4.7. The three core upgrades include better understanding of nuances (at the pragmatics level), more natural conversational experience, and enhanced cross-scenario collaboration from coding to knowledge work. The company positions AI as a "collaborator" rather than an "assistant," reflecting the industry's evolving thinking on human-AI collaboration paradigms. This release demonstrates Anthropic's high-frequency minor version iteration competitive strategy.
Anthropic officially released Claude Opus 4.8 today, marking a significant iterative update following Opus 4.7. The company states that the new version delivers notable improvements in understanding nuances, conversational naturalness, and overall collaborative capabilities.
From 4.7 to 4.8: Rapid Iteration Driven by User Feedback
In the release announcement, Anthropic explicitly mentioned that Opus 4.8's improvements stem directly from user feedback on version 4.7. This rapid response to user needs is particularly important as competition among large language models intensifies. While the version number jump from 4.7 to 4.8 may seem minor, the official description of "many fixes" suggests this isn't a simple patch but rather a systematic capability enhancement.
It's worth noting that version iteration strategies for AI large models differ fundamentally from traditional software. In the LLM space, even a decimal point version change can involve fine-tuning or alignment training across hundreds of millions of parameters. Anthropic's use of RLHF (Reinforcement Learning from Human Feedback) and Constitutional AI methods enables them to systematically translate user feedback into model behavior improvements, rather than merely patching at the rule level. This explains why the small step from "4.7 to 4.8" can deliver what the company calls a systematic enhancement.
This user-feedback-driven development model is becoming standard practice among leading AI companies. Compared to building in isolation before releasing major updates, frequent minor version iterations can more precisely address user pain points while reducing the adaptation cost of each update.
Three Core Improvements in Claude Opus 4.8
Better Understanding of Nuances
Opus 4.8 has made progress in understanding "nuances." This improvement means the model can provide more accurate responses when handling ambiguous expressions, implicit intentions, and context-dependent instructions. For everyday use cases, users no longer need to repeatedly revise their prompts to make the AI "understand what they actually want," directly lowering the barrier to use.
From a technical perspective, this capability corresponds to the model's mastery of pragmatics rather than just semantics. Semantics deals with the literal meaning of words, while pragmatics involves speaker intent, social context, and implicit presuppositions—precisely the source of the omissions, implications, and context-dependence that pervade everyday human expression. Earlier LLMs often gave irrelevant answers due to literal interpretation, which was a manifestation of insufficient pragmatic understanding. Improving this capability typically relies on higher-quality alignment datasets and introducing more preference annotations focused on "user true intent" during the RLHF phase.
The ability to understand nuances has always been one of the key indicators of LLM maturity—whether a model can accurately capture this information directly determines the practical value of an AI assistant.
More Natural Conversational Experience
The official description uses "feels much more natural to talk to" to characterize the conversational improvement. This isn't merely a language style adjustment but likely involves optimization across multiple dimensions including response length control, tone matching, and proactive follow-up questions. A "natural" AI conversation partner should be able to understand the rhythm and boundaries of dialogue like a human colleague, rather than mechanically outputting lengthy responses.
From an industry trend perspective, conversational naturalness is becoming a new competitive focus among AI companies. As foundational model capabilities converge, differentiation at the user experience level will become the key factor determining market dynamics.
Stronger Cross-Scenario Collaboration
Anthropic specifically mentions that Opus 4.8 serves as a "stronger collaborator" across scenarios "from coding to knowledge work." This phrasing is noteworthy—they use "collaborator" rather than "assistant," reflecting Anthropic's deeper thinking about AI positioning.
Positioning AI as a "collaborator" rather than an "assistant" represents an important shift in AI industry discourse over the past two years, backed by solid technical foundations: when a model has a sufficiently large context window and multi-step reasoning capabilities, it can participate in complex tasks requiring sustained follow-through, not just single-turn Q&A. Anthropic has repeatedly emphasized the balance between "AI Safety" and "Helpfulness" in their research. Positioning AI as a collaborator also implies the model is expected to exercise more proactive judgment—raising questions or alternative approaches at appropriate moments rather than unconditionally executing instructions. Together with OpenAI's "Copilot" strategy and Google's "Agent" roadmap, this forms the collective vision of leading AI companies for the next generation of human-AI collaboration paradigms.
In coding scenarios, stronger collaboration capabilities may mean better code context understanding, more precise bug identification, and more reasonable architectural suggestions. In knowledge work scenarios, this may manifest as deeper analytical capabilities and more insightful output.
Strategic Significance in the LLM Competitive Landscape
Against the backdrop of continued investment from giants like OpenAI, Google, and Meta, Anthropic has chosen to maintain competitiveness through high-frequency iteration. As Claude's flagship model, every update to the Opus series directly impacts Anthropic's position in the premium AI market.
Interestingly, the release cadence of Opus 4.8 indicates Anthropic is adopting a "fail fast, fix fast" strategy. Rather than pursuing a perfect version in one shot, they approach the optimal solution through continuous small, rapid steps. In the current environment of rapidly evolving AI technology, this strategy may be more effective than large version jumps.
For developers and enterprise users, the release of Opus 4.8 means there's another option worth serious evaluation for coding assistance and knowledge-intensive work. It's recommended to follow subsequent independent benchmarks and community feedback for a more comprehensive understanding of this update's actual impact.
Key Takeaways
- Anthropic releases Claude Opus 4.8, incorporating systematic improvements through alignment techniques like RLHF based on user feedback from version 4.7
- Three core improvements: better nuance understanding (at the pragmatics level), more natural conversational experience, and stronger cross-scenario collaboration
- The company positions AI as a "collaborator" rather than an "assistant," covering scenarios from coding to knowledge work, reflecting the industry's new consensus on human-AI collaboration paradigms
- Adopts a high-frequency minor version iteration strategy, rapidly responding to user needs to maintain competitiveness in the fierce LLM market
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.