Claude Sub-agents vs Agent Teams: How to Choose Between Two AI Multi-Agent Collaboration Patterns

Sub-agents vs Agent Teams: architecture differences and selection strategies for AI multi-agent collaboration
Single AI agents face three bottlenecks: serial processing, context window congestion, and single-perspective blind spots. The sub-agent pattern uses a star-shaped centralized structure suited for independent tasks, while agent teams use a mesh collaboration structure where each AI has an independent 200K token context window, ideal for complex projects requiring continuous communication. In a real-world test, agent teams achieved 95%+ feature completeness in RPG game development, far exceeding a single AI's 65-70%, at roughly 4x the cost. Choosing between them is fundamentally an engineering economics decision.
When a single AI agent hits an efficiency ceiling no matter how powerful it is, what should we do? Claude offers two fundamentally different paths: Sub-agents and Agent Teams. While both appear to be "multi-AI collaboration," they differ radically in architecture design, communication patterns, and applicable scenarios. This article provides an in-depth analysis of the core differences between these two multi-agent collaboration patterns and demonstrates their performance gap through a real-world case study.
Three Bottlenecks of a Single AI Agent
Before discussing multi-agent solutions, we need to understand why a single AI agent "can't keep up." Even the most powerful AI models encounter three insurmountable bottlenecks when facing complex engineering tasks:
First, the limitation of serial processing. A single AI can only handle one thing at a time—no matter how many tasks pile up, they must wait in queue. It's like having only one all-around programmer on a team, with every requirement bottlenecked through a single person.
Second, context window congestion. The context window is one of the core physical limitations of large language models. From a technical standpoint, it refers to the maximum number of tokens the model can "see" and process during a single inference. Tokens are not equivalent to characters or words—in English, one token corresponds to roughly 4 characters; in Chinese, one character typically maps to 1-2 tokens. A 200K token context window is approximately equivalent to 150,000 English words, or a medium-length technical manual.
When the context fills up, the model doesn't throw an error—it silently "forgets" the earliest input content. This mechanism is called sliding window truncation. For complex engineering tasks, this means architectural constraints, interface protocols, or business rules established early on may quietly disappear halfway through the task, causing subsequently generated code to produce hidden conflicts with earlier designs—issues that are extremely difficult to debug. This is especially fatal in complex projects—you might spend a long time discussing architecture design with it, only to find it has forgotten the original design constraints by the time it's writing the actual implementation.
Third, blind spots from a single perspective. With no one to discuss with and no one to raise objections, AI easily goes down a single path without looking back. In software engineering, code reviews and solution discussions are important precisely because multiple perspectives can catch blind spots that a single viewpoint misses.
These three bottlenecks compound together to form an efficiency ceiling that a single AI agent cannot break through on its own.
Sub-agent Pattern: The Manager-Assistant Relationship
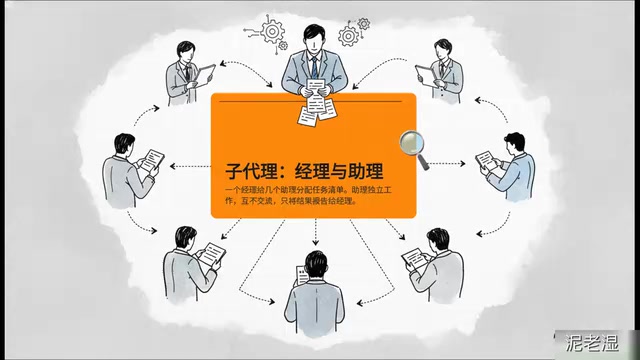
The core idea of the sub-agent pattern is centralized task distribution. Think of it as a manager working with several assistants: the manager breaks a large task into several independent smaller tasks, assigns them one by one to different assistants, and each assistant reports results back to the manager upon completion.
This pattern has several distinctive characteristics:
- Star topology: All information flows center around the main agent (manager), with zero communication between assistants
- Top-down task assignment: The main agent decides who does what; assistants are only responsible for execution
- Result-aggregation collaboration: Assistants deliver results back to the main agent, which handles unified integration
From the theoretical perspective of Multi-Agent Systems (MAS), the sub-agent pattern corresponds to the classic "Hierarchical Control Architecture." This architectural concept originated from distributed artificial intelligence research in the 1980s, emphasizing unified scheduling by a central coordinator in exchange for system behavior predictability and controllability. Modern LLM-driven multi-agent frameworks (such as AutoGen, CrewAI, and LangGraph) combine these classical theories with the language understanding capabilities of large language models, enabling communication between agents to be conducted in natural language rather than predefined protocols, dramatically reducing system design complexity.
The advantage of this architecture lies in its simplicity, controllability, and low overhead. But its limitations are equally obvious—assistants cannot communicate directly with each other, and when dependencies exist between tasks, all coordination work falls on the main agent.
Agent Team Pattern: The AI Version of Agile Development
Agent Teams represent a completely different collaboration paradigm. They more closely resemble agile teams in modern software development: the project manager sets the overall direction, while team members can freely communicate, pull meetings at any time, and conduct code reviews for each other.
The analogy between agent teams and agile development teams has remarkably precise technical correspondence. One of the core practices of agile development is the "Cross-functional Team"—team members possess different professional skills and can self-organize to complete the full process from requirements to delivery within a Sprint cycle. In agent teams, this cross-functional characteristic manifests as different AIs being given different system prompts and toolsets, giving them differentiated "professional personas." For example, a security expert AI would be injected with OWASP security specification knowledge, while a performance optimization AI would be configured with permissions to invoke performance analysis tools. The "daily standup" in agile corresponds to status synchronization messages in agent teams; "code review" corresponds to a reviewer AI's critical evaluation of an implementer AI's output; and "Kanban task claiming" corresponds to dynamic allocation mechanisms in shared task queues.
Compared to the sub-agent pattern, agent teams have several key differences:
| Dimension | Sub-agent Pattern | Agent Team Pattern |
|---|---|---|
| Topology | Star (top-down) | Mesh (interconnected) |
| Communication | Reports only to main agent | Peer-to-peer between members |
| Context Management | Shares main agent's context | Each member has independent 200K token window |
| Task Assignment | Hard assignment by main agent | Shared Kanban, proactive claiming |
The most critical point here is independent context windows. Each AI in an agent team has its own independent 200K token memory space, meaning the frontend AI won't have its memory "polluted" by backend technical details, and the security AI can focus on deep thinking within the security domain. It's like each team member having their own independent, oversized workbench without interfering with each other. From the MAS theory perspective, this design is closer to a "Distributed Cooperative Architecture," where each agent has local autonomy and achieves global objectives through peer-to-peer communication.
Selection Guide: When to Use Which
The core decision criterion boils down to two words: Independent vs Collaborative.
Scenarios Suited for Sub-agents
When your task can be decomposed into a bunch of mutually independent small tasks, sub-agents are the most efficient choice:
- Searching for the same error code across multiple files
- Refactoring several independent functions that don't affect each other
- Batch-generating test cases with uniform formatting
- Processing multiple independent data transformation tasks in parallel

The common characteristic of these tasks is: the input and output of each subtask is self-contained, with no need to know what other subtasks are doing. Like assembly line work, everyone manages their own station, and efficiency is maximized.
Scenarios Suited for Agent Teams
When a task's success depends on continuous communication and information sharing between members, agent teams are the more appropriate choice:
- Complex system refactoring: Where one change affects everything, requiring multi-party coordination
- Cross-domain solution design: Where security experts and performance experts need to "sit down and hash it out" to find the optimal solution
- Frontend-backend integration: Where frontend AI and backend AI need to constantly align on API interface definitions
- High-quality delivery requiring code review: Where one AI writes code and another AI reviews it and suggests improvements
Real-World Comparison: Pokémon RPG Game Development
No amount of theory compares to seeing a real comparison test. The challenge: develop a complete Pokémon-style RPG web game from scratch—including character systems, battle systems, map systems, and dialogue systems, all modules interconnected, with considerable complexity.
The results are striking:
| Metric | Single AI Agent | Agent Team |
|---|---|---|
| Lines of Code | ~800 | 2000+ |
| Feature Completeness | ~65-70% | 95%+ |
| Code Structure | Average | Highly modular |
| Cost | Baseline | ~4x |

The most noteworthy number here isn't the line count, but the 95%+ feature completeness. 800 lines of code is at best a half-finished demo, while 2000+ lines of highly modular code represents a nearly production-ready complete product.
Behind the "approximately 4x cost" figure lies a core economics question of LLM applications. Mainstream large models charge by token—input tokens and output tokens are typically priced separately, with output token unit prices often 3-5x that of input tokens. In agent teams, cost multiplication comes from two dimensions: first, the direct token consumption from running multiple AI instances in parallel; second, the additional tokens generated by inter-agent communication itself—every time one AI sends a message to another AI, that message is billed as input tokens. From an ROI perspective, the key variable is "rework cost": if the 65-70% completeness from a single AI requires manual completion of the remaining 30%, and that 30% happens to be the most complex parts—system integration, edge case handling, etc.—then the time cost of manual rework may far exceed the price difference of 4x token fees.
The reason agent teams can achieve such results comes down to this: different AIs in the team are responsible for different modules (character system, battle engine, map rendering, UI interaction, etc.), and they can collaborate with each other, catching each other's gaps. The AI responsible for the battle system can directly confirm attribute interfaces with the AI responsible for the character system, without needing to relay messages through a "manager."
Core Insight: Not Faster, But More Complete
The core value of agent teams is not about "working faster"—in fact, their cost is several times that of a single AI. Their true value lies in being able to deliver a level of completeness and professionalism that a single AI can never achieve.
This isn't a question of "which is better or worse," but rather a question of choosing the most appropriate tool for the task:
- Simple, independent tasks → Sub-agent pattern (efficient, low cost)
- Complex, collaborative projects → Agent team pattern (high completeness, high quality)
You don't need a sledgehammer to crack a nut, but you can't build an aircraft carrier with just a hammer either. First understand the nature of your task, then you can choose the right formation for your AI team.
When AI is no longer a solitary tool but can form teams, divide labor, and work side by side like humans, the software development paradigm we're familiar with may be undergoing a profound transformation. The enormous changes hidden behind this are worth serious consideration by every developer.
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.