CodeRAG Technical Deep Dive: Four Core Components That Help AI Truly Understand Your Codebase
CodeRAG Technical Deep Dive: Four Core…
CodeRAG uses four synergistic technologies to help AI coding assistants truly understand enterprise codebases
CodeRAG is a code-oriented Retrieval-Augmented Generation framework that combines four technologies — vector similarity search (capturing code semantics), file system tools (simulating programmer navigation), Code Knowledge Graph/CKG (revealing structural dependencies), and DeepWiki (integrating design intent and historical knowledge) — to ground AI coding assistants' output in real code context, solving LLM hallucination problems and enabling reliable, traceable code generation and understanding.
Introduction: The Core Challenge of AI Programming
AI programming assistants are becoming increasingly powerful — from writing code and fixing bugs to code reviews, they seem capable of everything. But one core challenge persists: How can these AIs truly understand an enterprise's massive, intricately complex codebase?
Relying solely on the model's parametric memory to "guess" clearly doesn't work — it frequently produces hallucinations, generating code that looks correct but simply won't run. CodeRAG (Code-oriented Retrieval-Augmented Generation) is a technical framework born to solve this problem, with a single core objective: Ground AI's responses in real code context.
RAG (Retrieval-Augmented Generation) was originally proposed by Facebook AI Research in 2020. Its core idea is to retrieve relevant information from external knowledge bases as context input before the large language model generates an answer. This paradigm addresses two fundamental flaws of large models: the timeliness problem of parametric memory (training data has a cutoff date) and the hallucination problem (models confidently fabricate non-existent information). In the code domain, hallucinations are particularly dangerous — a seemingly reasonable but actually non-existent API call can cause compilation failures or even runtime crashes. CodeRAG adapts the RAG paradigm specifically to code scenarios, handling code-specific structural properties (AST, scoping, type systems) and multi-layered semantics (the interweaving of natural language comments and formal code logic).
This article breaks CodeRAG down into four technical implementation forms and examines how they work together.
Vector Similarity Search — The Semantic Soul of CodeRAG
Vector similarity is CodeRAG's most fundamental capability. It works by converting both the user's query (e.g., "how to implement a binary search") and thousands of code snippets in the codebase into mathematical vectors. Instead of simple keyword matching, it searches for code that is semantically closest to the query in high-dimensional space.
To improve accuracy, specialized embedding models optimized for code scenarios are now commonly used, capable of understanding both natural language intent and code structural features simultaneously. These models (such as Microsoft's CodeBERT, GraphCodeBERT, and OpenAI's text-embedding series) map code snippets into vector spaces typically of 768 to 1536 dimensions. Unlike general-purpose text embeddings, code embeddings need to capture information at three levels: lexical (variable names, keywords), syntactic (AST structure, control flow), and semantic (the actual functional intent of the code). For example, a quicksort written in Python and one written in Java, while textually completely different, should be close to each other in vector space. Vector similarity is typically measured using cosine similarity or inner product, and paired with vector databases like FAISS or Milvus, enables millisecond-level approximate nearest neighbor search.

Cursor's Implementation
The AI-driven IDE Cursor is a classic example, with an elegantly designed workflow:
- Client-side intelligent sync: The local client syncs changed portions of the codebase to cloud servers for vectorization and indexing
- Cloud-based vector matching: When a user asks a question, the query finds the most relevant code snippet addresses (file paths and line numbers) via vector matching in the cloud, without transmitting the code itself
- Local code extraction: The client retrieves the actual code locally based on the returned addresses
- Bundled inference: The question and relevant code are sent together to the large model for inference
This workflow cleverly strikes a balance between efficiency and privacy/security — sensitive code always stays local, while the cloud only handles vector indexes. The incremental sync mechanism (only syncing changed portions) dramatically reduces bandwidth consumption and index rebuild costs — for enterprise repositories with millions of lines of code, full index rebuilds can take hours. Its "index in the cloud, code on local" separation architecture borrows from search engines' inverted index concept: the cloud only stores vectors and corresponding file location metadata, not the source code. This design is particularly important for industries with stringent code security requirements like finance and healthcare, as it satisfies data residency compliance requirements while leveraging cloud GPU cluster computing power for efficient vector retrieval.
File System Tools — Simulating a Programmer's Navigation Habits
Semantic understanding alone isn't enough. A skilled programmer doesn't start by reading the entire codebase — they first look at the directory structure, find key files, review file outlines, and only then locate specific code lines.
The second pillar of CodeRAG is file system tools, providing AI agents with a toolkit similar to what human programmers use:
- FileTree: View directory tree structure
- FileOutline: View a single file's outline
- ReadLines: Read file content by exact line numbers
- SearchInFolders: Perform keyword searches within folders

File system tools follow the AI Agent Tool-Use paradigm. In this paradigm, the large language model is no longer a pure text generator but a decision-maker capable of planning and executing multi-step operations. The model selects appropriate tools via Function Calling, constructs parameters, executes calls, parses results, and then decides the next action. This ReAct (Reasoning + Acting) loop enables AI to perform progressive code exploration just like human programmers: first using FileTree to understand the project overview, then FileOutline to locate key modules, and finally ReadLines to precisely obtain needed code. Compared to stuffing the entire codebase into the context window at once, this on-demand retrieval approach dramatically saves token consumption and avoids attention dilution from "needle in a haystack" scenarios — research shows that when context is too long, the model's attention to information in middle positions drops significantly (the "Lost in the Middle" phenomenon).
The Synergistic Value of These Two Pillars
Vector similarity lets AI "read between the lines," understanding the user's true intent rather than doing naive text matching. File system tools transform AI from an information-overloaded drowning victim into a methodical engineer — making AI's exploration behavior as logical and traceable as a human programmer's.
The combination of semantic understanding + engineering navigation forms the foundation for CodeRAG's efficient and reliable processing of massive codebases.
Code Knowledge Graph (CKG) — From Text to a Reasonable Network
Pure semantic matching and file navigation aren't sufficient to reveal the intricate relationships between code. For example: Which downstream services would be affected by modifying a function? Which modules would be impacted by deprecating an API?
The Code Knowledge Graph (CKG) was created to solve these types of problems. Think of it as a "living map" depicting the entire code world:
- Nodes: Key elements in code (classes, functions, interfaces, database tables, etc.)
- Edges: Relationships between elements (calls, inheritance, read/write, etc.)

CKG construction typically relies on static analysis toolchains. For different programming languages, corresponding parsers are used (such as Tree-sitter supporting incremental parsing for 40+ languages, Language Server Protocol providing cross-editor semantic analysis capabilities) to extract ASTs (Abstract Syntax Trees), then cross-file reference relationships are established through symbol resolution. Graph databases (such as Neo4j, TigerGraph) or property graph models are used to store and query these relationships, supporting graph query languages like Cypher or GSQL for complex path traversal and pattern matching.
Three Core Values of CKG
- More precise retrieval: Can directly query relationship-based complex questions like "which functions call the CreateUser interface and ultimately write to the database"
- Better context organization: Only feeds truly relevant code snippets to the model, avoiding token waste
- Verifiable and traceable answers: Every relationship can be traced to its source, greatly reducing the risk of AI "making things up"
ByteDance's open-source TreeAgent is a typical example of CKG implemented locally. TreeAgent builds a lightweight code relationship graph on the developer's machine, enabling AI Agents to perform structured code reasoning without relying on cloud services. It supports typical query patterns such as impact analysis (what downstream components are affected by modifying X), dependency tracking (what upstream components does Y depend on), and dead code detection (which functions are never called), making it particularly suitable for offline development and high-security scenarios.
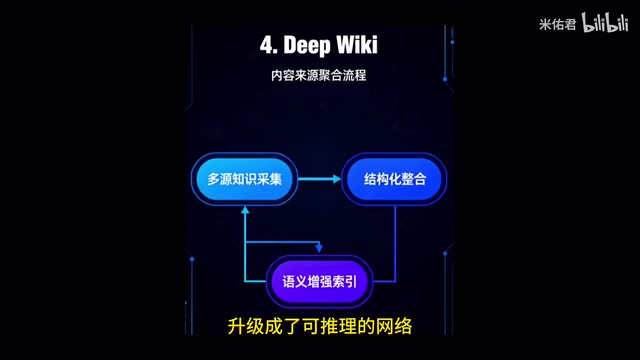
DeepWiki — The Semantic Encyclopedia of Code
If CKG is the structural map of code, then DeepWiki is the semantic encyclopedia of code. It goes beyond code comments to systematically answer deeper questions:
- Why was the code written this way?
- What role does it play in the overall system?
DeepWiki integrates knowledge scattered across design documents, PR discussions, and even incident postmortems, providing AI with the richest background information. This way, when AI generates answers, it can not only provide code but also explain the design intent and historical evolution behind it.
DeepWiki represents a paradigm shift from "code as documentation" to "knowledge as documentation." Traditional code documentation (like Javadoc, Doxygen) only describes the What layer of interfaces, while DeepWiki attempts to capture knowledge at the Why and How layers. Its knowledge sources include: Git commit history (revealing code evolution trajectories), Pull Request discussions (recording the debate process of design decisions), issue tracking (associating bug fix context), Architecture Decision Records (ADR), and even technical discussions in Slack or Feishu. This unstructured knowledge is summarized, correlated, and structured through LLMs to form a searchable semantic knowledge base. This solves the famous "knowledge evaporation" problem in software engineering — when core developers leave, vast amounts of tacit knowledge disappear with them, and new members may need months or even years to rebuild deep understanding of the system.
The Complementary Relationship Between CKG and DeepWiki
CKG's core value is upgrading code from a text collection to a reasonable network, enabling AI to understand causal relationships between code. DeepWiki goes further, filling in the "why" lesson for AI, bridging the gap in design intent and historical context.
Combined, they ensure AI's output is no longer isolated code snippets but an integrated answer containing context, design logic, and background knowledge. This combination also echoes the concept of "Code Archaeology" in software engineering — understanding a piece of code requires knowing not only what it does now, but also why it became what it is today.
Summary: The Four-in-One Complete CodeRAG Solution
CodeRAG forms a complete solution through the synergy of four technologies:
| Technical Component | Core Capability | Problem Solved |
|---|---|---|
| Vector Similarity | Captures deep code semantics | Understanding user's true intent |
| File System Tools | Simulates programmer navigation habits | Efficient and secure information retrieval |
| Code Knowledge Graph (CKG) | Reveals structural and dependency relationships | Precise retrieval and reasoning |
| DeepWiki | Integrates design intent and diverse knowledge | Enhancing answer depth |
The shared goal of these four technologies is to ensure AI programming assistants' output is truly grounded in real code context, making answers more reliable and robust. As AI programming tools become increasingly prevalent, CodeRAG represents not just a technical solution, but an engineering philosophy for moving AI from "seemingly smart" to "truly reliable."
It's worth noting that these four technologies are not mutually independent but form a progressive understanding system from coarse to fine, from surface to depth: vector similarity provides initial semantic anchors, file system tools enable precise information retrieval, CKG reveals structured dependency relationships, and DeepWiki supplements human-level design wisdom. As context windows continue to expand and multimodal models evolve, each component of CodeRAG continues to advance — but its core principle remains unchanged: Every AI output should be verifiable and traceable to its source.
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.