Codex VS Claude Code: The Token Economics Behind a 10x Price Gap

The 10x cost gap between Codex and Claude Code comes from token usage patterns, not per-token pricing.
Codex and Claude Code have nearly identical per-token prices, yet the same task costs 10x more with Claude Code. The real difference is token consumption: Codex uses ~1/4 the tokens thanks to terse output, leaner context management, and fewer exploratory steps. But Claude's extra tokens buy thoroughness — catching hidden bugs like race conditions and producing cleaner code. The smart choice depends on your scenario: Codex for daily dev work, Claude Code for critical, quality-first projects.
The same complex programming task costs $15 with Codex and $155 with Claude Code — a full 10x difference. This isn't a one-off fluke; it's a result repeatedly verified by multiple independent benchmarks. Most people's first instinct is "just pick the cheaper one," but the truth is far more nuanced. Today, we're breaking down this bill completely.
The Per-Token Price Is Nearly Identical — The Gap Isn't There
Most people instinctively assume Codex is cheaper because OpenAI's per-token pricing is lower. But pull up the official price sheets, and the conclusion is completely counterintuitive.
Codex's primary model, GPT-5.5, is priced at $5 per million input tokens and $30 per million output tokens. Claude Code's primary model, Opus 4.8, is priced at $5 per million input tokens and $25 per million output tokens.

Input prices are identical, and GPT-5.5's output price is actually higher. So the first conclusion is crystal clear: the 10x price gap has nothing to do with per-token pricing. Codex is even slightly more expensive than Claude Code on a per-token basis.
So where does the money actually go? The answer is token volume. Here's a quick primer on tokens: a token is the basic unit of measurement for how large language models process text. One token corresponds to roughly 3/4 of an English word, or 1–2 Chinese characters. Each API call is billed separately for input tokens (what you send to the model) and output tokens (what it generates), with output tokens typically costing 3–6x more than input tokens because generating text requires significantly more compute than reading it. In AI coding scenarios, a single complex task may involve dozens of round-trip calls, each producing input and output tokens, so total consumption can easily reach millions.
For similar complex tasks, Codex consumes roughly 1.5 million tokens, while Claude Code burns through 6.2 million — over 4x more. This isn't an isolated data point; multiple independent benchmarks consistently show a range of 3.2x to 4.2x, regardless of who runs the test or how. The fact that Codex is more token-efficient is universally consistent.
As for why the final bill balloons to 10x instead of 4x — it's because a larger share of those 6.2 million tokens are expensive output tokens, combined with differences in cache hit rates, which compound the gap further. Cache hit rate refers to how often previously sent input tokens in a multi-turn conversation are cached by the API, allowing them to be billed at a discounted rate (typically 10%–50% of the original price). Codex's architecture is designed with greater emphasis on cache reuse, while Claude Code tends to stuff large amounts of freshly read file content into each turn, resulting in lower cache hit rates — further widening the actual bill gap.
Three-Layer Breakdown: How Codex Gets Away with 1/4 the Tokens
Same job, but Codex finishes it with a quarter of the tokens. How? That's the question truly worth digging into.
Layer 1: Output Style Differences
GPT-5.5 is terse — no preamble, no detours. Ask it to write code, and it hands you a runnable program. Claude is the complete opposite — it likes to explain its thought process, asks clarifying questions, and throws in commentary about why it made certain choices.
Put simply: one is the heads-down worker, the other is the one who narrates while working.
One benchmark showed that GPT-5.5 used approximately 72% fewer output tokens than Opus on equivalent tasks. That precise figure comes from a single evaluation, but "significantly fewer" is the consensus across the board.

More critically, there's a compounding effect. AI coding isn't a one-shot deal — a single task involves dozens of round trips: reading files, running commands, modifying code. Save a little on each turn, and after dozens of turns, the gap snowballs into several multiples. This compound accumulation effect is very common in software engineering: a 1% efficiency difference per iteration becomes a 2.7x total gap after 100 iterations, and the per-turn token difference in AI coding is far greater than 1%.
Layer 2: Context Reading Strategy Differences
Here we need to understand a key concept: context. Context is everything the AI currently "remembers" — everything you've said, every file it's read, all piled together — and this part is also billed by the token. The context window is the maximum number of tokens a model can process in a single call; current mainstream models support context windows of 128K or even 200K tokens. A larger window means the model can "remember" more, but it also means each call may be stuffed with more billable tokens.
Claude Code reads files in a very "thorough" way: every file it reads, every command it runs, the full raw content gets stuffed into the context — no compression, no summarization — and it stays there. The problem is, if it reads a log file with tens of thousands of lines midway through, that log continues to occupy space and incur charges in every subsequent turn. The more it reads, the heavier the baggage, and the context snowballs larger and larger.
Codex's context management is more restrained, reading more selectively. Given the same context window size, its actual utilization efficiency is higher. Think of it this way: imagine a bookshelf that holds 200 books. Codex only keeps the few books it currently needs on the shelf, returning them when done; Claude Code leaves every book it's ever glanced at on the shelf, only clearing space when it's nearly full.
Layer 3: Task Execution Habit Differences
Claude Code explores more broadly and investigates more thoroughly. For the same bug, it proactively checks several related files, re-reads things multiple times, and repeatedly confirms with itself that nothing was missed. All those "let me double-check" actions consume tokens.
Codex goes straight for the target — once it has a fix in sight, it executes with minimal detours. This difference in strategy fundamentally reflects the classic "Exploration vs. Exploitation" trade-off in AI system design: exploring more possibilities reduces the risk of missing something but consumes more resources; going straight for the target is more efficient but may miss edge cases.
Cheaper Doesn't Mean Better: What Claude's Extra Tokens Buy
At this point, you might think Claude Code is just wasting money. But flip those three layers around, and the picture changes completely.
The 4x extra tokens Claude burns buy two things: thoroughness.

Precisely because it reads comprehensively, investigates meticulously, and thinks more deeply, Claude Code caught a race condition in actual comparisons that Codex missed. Race conditions are among the most classic and trickiest bug types in concurrent programming — when two or more threads simultaneously access shared resources, and the final result depends on their execution order, a race condition can occur. What makes them dangerous: they almost never trigger in development and testing environments because single-machine loads are low and timing is stable; but under high-concurrency production scenarios, subtle timing differences can lead to data corruption, deadlocks, or even security vulnerabilities. Many major historical system failures — including the software defect involved in the 2003 Northeast blackout — were related to race conditions. Discovering these bugs typically requires extremely meticulous line-by-line code review, which is precisely where Claude Code's "take a few extra laps" strategy proves its worth. Those extra laps are exactly what surfaced the bug.
The code quality gap is also backed by data:
- Blind evaluation results: When code from both tools was anonymized and presented side by side, 67% of reviewers rated Claude Code's output as cleaner, while only 25% favored Codex. Code blind evaluation borrows from the double-blind peer review mechanism used in academic papers: reviewers don't know which AI generated the code and score purely based on readability, structural clarity, error handling completeness, and adherence to best practices. This method effectively eliminates brand bias — if reviewers knew the code came from a "more expensive" model, they might subconsciously give higher scores. The 67% vs. 25% blind evaluation result carries strong statistical significance, indicating that Claude Code has a quantifiable advantage at the code craftsmanship level.
- Developer survey: In a survey of over 500 developers, 65% still chose Codex as their daily primary tool.
These two numbers must be read together. Claude's code quality is genuinely higher, but most people still choose Codex for daily work — because for most tasks, saving money and effort while being "good enough" truly matters more than that extra bit of cleanliness.
Selection Guide: It's Not About Who's Better — It's About Doing the Math by Scenario
The entire logic chain comes together here: Codex saves money by being concise, and Claude spends money by being thorough. Neither is getting a free lunch — each spends its tokens on different things.

When to Choose Codex
- Day-to-day development and rapid iteration: Writing feature modules, wiring up APIs, handling routine logic
- Prototype validation: Quickly shipping an MVP — get it running first, refine later. MVP (Minimum Viable Product) is a core concept in lean startup methodology, systematically articulated by Eric Ries in The Lean Startup. The core idea is to build a product version that validates key hypotheses with minimal cost and time, using real user feedback to determine the next direction. Under this philosophy, code "perfection" matters far less than "getting it running and collecting feedback," which explains why most developers lean toward lower-cost options during early iterations.
- Budget-sensitive projects: Solo developers, startup teams, learning and experimentation
- Existing ChatGPT subscribers: Codex is essentially bundled with the subscription at no extra cost
When to Choose Claude Code
- Complex system refactoring: Large-scale projects involving multi-module interdependencies and legacy code. In these projects, code dependencies are tangled and complex — modifying one place can trigger chain reactions. Claude Code's habit of "checking a few extra files" actually becomes an advantage here, as it's more likely to catch compatibility issues hiding at module boundaries.
- Production-grade code: Scenarios with strict fault-tolerance requirements where quality comes first
- Security-sensitive domains: Where discovering hidden bugs like race conditions is critical
- Code review and optimization: Where deeper analysis and cleaner output are needed
It's worth noting that many mature engineering teams have already adopted a "hybrid strategy": using Codex for rapid daily development, then running a deep review pass with Claude Code before merging code into the main branch. This combination controls total costs while ensuring code quality at critical checkpoints.
Key Takeaways
The truth behind the 10x price gap is now clear: per-token pricing is nearly identical (GPT-5.5's output is actually more expensive), and the real difference lies in token volume — Codex's 4x efficiency advantage comes from being terse, reading less, and taking fewer detours. But the extra tokens Claude consumes aren't wasted — they buy more thorough investigation and cleaner code.
The essence of choosing between them isn't about which is "better" — it's about weighing cost against quality for your specific scenario. Choose Codex for everyday development to save money and hassle; choose Claude Code for critical projects where you're paying for quality — that's the rational engineering decision.
Related articles
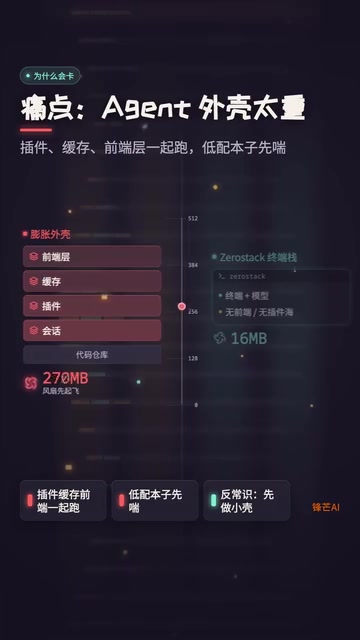
ZeroStack: An In-Depth Look at the Rust-Based Minimalist Coding Agent That Uses Only 16MB of RAM
In-depth review of ZeroStack, a Rust-based coding agent using only 16MB RAM. Analyzing its file I/O, multi-model support, permission controls, and ideal use cases.
ZCodeAI Free AI Agent Tool Review: Multi-Model Aggregation at Zero Cost
Detailed review of ZCodeAI, a desktop AI Agent tool by ZhiPu featuring free built-in models like DeepSeek V4 Flash and Xiaomi MiMo, with multi-model aggregation and no API Key required.
Claude Code Chinese Practical Handbook: A Complete Beginner's Guide for Users in China
A detailed look at the Claude Code Chinese handbook on Feishu, covering setup, domestic LLM integration, commands, and templates for users in China.