Codex vs Claude Code: The Truth Behind the 10x Bill Difference & a Practical Selection Guide
Codex vs Claude Code: the 10x bill gap comes from token usage, not unit price — choose by scenario.
A deep dive into why the same coding task costs $15 on Codex but $155 on Claude Code reveals the gap isn't in per-token pricing but in token consumption patterns. Claude Code burns 4x more tokens due to verbose output, loose context management, and repeated verification — but this buys deeper code quality and catches hidden bugs like race conditions. The article provides a scenario-based selection framework and practical tips to cut AI coding bills by 20–40%.
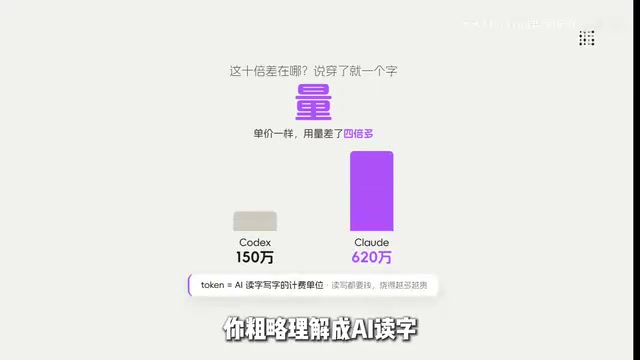
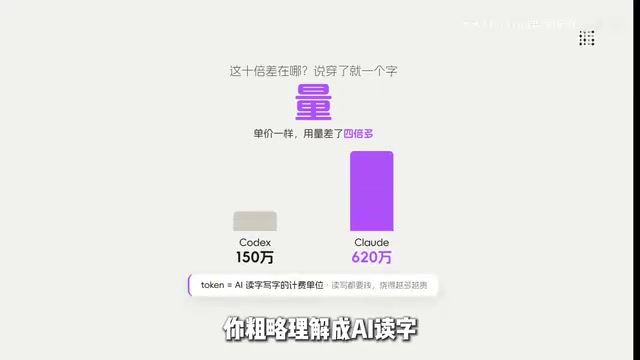
The same coding task costs $15 on Codex but $155 on Claude Code — a full 10x difference. Yet if you check the official pricing, GPT-5.5 output costs $30 per million tokens, while OPUS 4 is actually only $25. On a per-token basis, Codex isn't cheaper at all — it's even slightly more expensive. So where does that 10x gap come from?
A Bilibili creator who has spent two years deep in AI-assisted programming, switching between both tools daily, broke down the math completely. The core takeaway: The difference isn't in the unit price — it's in the token consumption.
Same Task, 4x the Token Consumption
According to hands-on testing, for the same type of complex programming task, Codex consumes roughly 1.5 million tokens, while Claude Code burns through 6.2 million.
It's worth explaining how token billing works. A token is the smallest unit a large language model uses to process text, but it doesn't map one-to-one to a Chinese character or an English word. For English, one token is roughly 0.75 words (about 4 characters). For Chinese, a single character is typically encoded as 1.5 to 2 tokens. More importantly, model billing is split into "input tokens" and "output tokens," with output tokens typically priced 3–5x higher than input — because generating text requires far more compute than reading it. Taking GPT-5.5 as an example, output at $30 per million tokens means every extra word the model "says" ticks the developer's bill up another notch. This also explains why Claude Code's "narrate while you work" style, discussed below, causes costs to skyrocket — output-side verbosity hits the most expensive billing tier directly.
So why does Claude Code burn 4x more tokens? It comes down to three things:
1. Verbose Output: Narrating While Working
GPT-5.5's coding style is "heads down, get it done" — it hands you a working chunk of code, no frills. OPUS 4, on the other hand, explains before writing, asks clarifying questions about your requirements, and then walks you through its reasoning after finishing. One works silently; the other narrates every step. Naturally, the latter's output tokens multiply.
2. Loose Context Management: No Summarization, No Cleanup
Every time Claude Code reads a file or runs a command, it stuffs the full raw content into the context window — no summarization, no proactive cleanup. If it reads a 10,000-line log file midway through, that log occupies space in every subsequent conversation turn, continuously incurring charges. The baggage piles up, and token consumption snowballs.
To understand how serious this is, you need to know how the "context window" works. The context window is the maximum number of tokens a model can "remember" in a single conversation. Current mainstream models have expanded from the early 4K and 8K limits to 128K or even 200K tokens. But a bigger window doesn't mean you should fill it — in every conversation turn, all historical messages are re-sent to the model, meaning every piece of text in the context is billed again on every turn. Codex uses a strategy akin to "sliding window + summary compression," condensing earlier conversation content into brief summaries to control the actual token count sent per turn. Claude Code's approach is closer to "full retention" — it preserves information completeness but also triggers the snowball effect on token consumption. This difference is fundamentally an engineering trade-off between information fidelity and cost efficiency.
3. Repeated Verification: Better to Over-Check Than Miss Something
When encountering the same bug, Claude Code proactively checks several related files, verifies multiple times, and repeatedly confirms with itself that nothing was missed. All those "let me check again" actions burn tokens.

What Does the Extra Spend Actually Buy?
At this point, the answer might seem obvious — pick Codex, it's cheaper and more efficient. But flip those three points around, and the picture changes entirely.
The 4x extra tokens Claude Code burns buy two things: thoroughness.
Precisely because it reads everything, checks meticulously, and thinks more deeply, Claude Code caught a hidden bug in comparative testing that Codex missed — a race condition, the kind that never surfaces during testing but explodes in production. It's one of the most notoriously difficult bug types.
Race conditions are among the most classic and treacherous bugs in concurrent programming. When two or more threads or processes access a shared resource simultaneously, and the final result depends on their execution order, a race condition occurs. The reason it "never surfaces during testing but explodes in production" is that in development environments, code typically runs in single-threaded or low-concurrency settings where the probability of triggering a race condition is extremely low. But under high-concurrency production scenarios, subtle timing differences cause these bugs to erupt frequently — at best corrupting data, at worst crashing the system. The infamous Therac-25 radiation therapy machine incident was related to a race condition, resulting in multiple patient deaths from radiation overdose. These bugs are so hard to catch in conventional code reviews because they don't exist in any single line of code — they hide in the interaction timing between multiple code segments. Claude Code's ability to catch such issues stems precisely from its cross-validation of logical relationships across multiple related files, rather than just checking individual function correctness.
There was also a blind evaluation experiment: code from both tools was anonymized and compared by reviewers. 67% found Claude Code's code cleaner, while only 25% preferred Codex's output.
Blind evaluation is a common assessment method in software engineering and AI, with the core principle of eliminating brand bias. The process involves stripping all identifying information from code generated by both models, randomly numbering the samples, and having reviewers score them on dimensions like readability, naming conventions, error handling completeness, and architectural soundness. The 67% vs. 25% preference gap is statistically significant, indicating that Claude Code has a perceptible advantage in code quality. However, it's worth noting that "cleaner code" and "more production-ready" aren't the same thing — if clean code takes 3x longer to produce, it may not be the optimal choice in fast-iteration business scenarios.
But here's the interesting part: in a survey of over 500 developers, 65% still use Codex as their daily workhorse.
Sounds contradictory? It's not contradictory at all. Saving tokens and writing better code aren't two separate things — they're two sides of the same trade-off:
- Codex saves money by cutting the chatter
- Claude Code spends money on extra verification
Neither is gaming the system. Each spends its money on different things.
Choosing by Scenario: A Practical Selection Framework for Codex vs Claude Code
So the real question isn't "which is better" — it's which makes sense for your scenario.
When to Choose Codex
- Day-to-day iteration: Feature development, prototyping, shipping fast
- Budget-sensitive: Solo developers, small teams, learning and experimentation
- Well-defined tasks: Clear requirements with no need for AI to ask clarifying questions
When to Choose Claude Code
- Complex engineering: Production-grade code, multi-module integration
- Low fault tolerance: Finance, healthcare, and other domains with zero tolerance for bugs
- Deep debugging: Tasks requiring in-depth analysis and cross-validation

Practical Token-Saving Tips: Cut Your Bill by 20–40%
Beyond choosing the right tool, your daily coding habits can significantly impact token consumption. Here's a proven "token-saving trifecta":
- Trim the context: Don't dump your entire project on the AI at once — give it only the files and snippets it needs. This is especially important with Claude Code, since as mentioned earlier, it doesn't proactively summarize or compress. Whatever you feed in, it carries the full weight indefinitely.
- Write clear instructions: Spell out your requirements precisely to reduce rounds of AI clarification and probing. A vague instruction might trigger 3–5 rounds of back-and-forth, while a structured prompt (including input format, output requirements, and edge cases) often delivers a satisfactory result in a single turn.
- Clean up conversations promptly: Start a new session when conversations get long to prevent historical messages from continuously consuming tokens. Due to how context window billing works, by the later turns of a 20-turn conversation, each turn might consume 5–10x the tokens of the first turn.
These seemingly simple habits can cumulatively reduce your monthly AI programming bill by 20–40%.
From "Following Recommendations" to "Doing the Math": Building Your Own AI Tool Evaluation Skills

The most valuable part of this analysis isn't telling you to pick A or B — it's providing a reusable decision-making framework.
This is especially important given the rapid iteration in the AI programming tool landscape. 2024–2025 has been a period of explosive growth for AI coding tools. Beyond Codex (OpenAI) and Claude Code (Anthropic), the market includes GitHub Copilot, Cursor, Windsurf, Amazon CodeWhisperer, and more. These tools fall roughly into two categories: "completion-based" tools that embed in your IDE and offer real-time code suggestions, and "agentic" tools that can autonomously execute multi-step programming tasks — reading files, running tests, fixing errors, and more. Both Codex and Claude Code belong to the latter category, which is why their token consumption far exceeds traditional completion tools — agentic tools may require dozens of internal reasoning loops to complete a single task. According to Gartner, by 2028, 75% of enterprise software engineers will use AI coding assistants, up from less than 10% in early 2023. In this rapidly expanding market, understanding cost structures rather than just watching feature demos is becoming a core competency for developers and engineering managers alike.
Once you internalize this approach, you gain three capabilities:
- Quickly match any coding task to the right tool: Know which tool handles routine work and which to deploy for critical tasks — no more guessing
- Filter out noise: The next time you see a review claiming "Tool X crushes Tool Y," you can immediately tell whether they actually did the math or just eyeballed the unit price
- Shift from passive to proactive: Your approach to managing AI coding tools evolves from "following others' recommendations" to "running the numbers myself"
As the guiding principle puts it:
Don't ask which tool is better. Ask which tool deserves the spend for this particular job.
Keep that in mind, and AI programming tools go from a confusing expense to a calculable investment.
Final Thoughts
Both tools have their strengths — there's no one-size-fits-all winner. Codex excels in efficiency and cost control; Claude Code excels in depth and code quality. The smartest approach isn't picking one over the other — it's using each where it fits — Codex for daily iteration to control costs, Claude Code for critical modules to ensure quality.
This methodology doesn't just apply to today's Codex and Claude Code. Whenever a new AI programming tool emerges, you can evaluate it with the same framework: check the unit price, calculate the usage, match it to your scenario, and compare the output. Tools will evolve, but the ability to do the math is universal.
Related articles
The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
The Tokenmaxxing craze is fading as enterprise AI procurement shifts from chasing Token counts to focusing on actual business outcomes. Learn why outcome-based AI evaluation is the right approach.
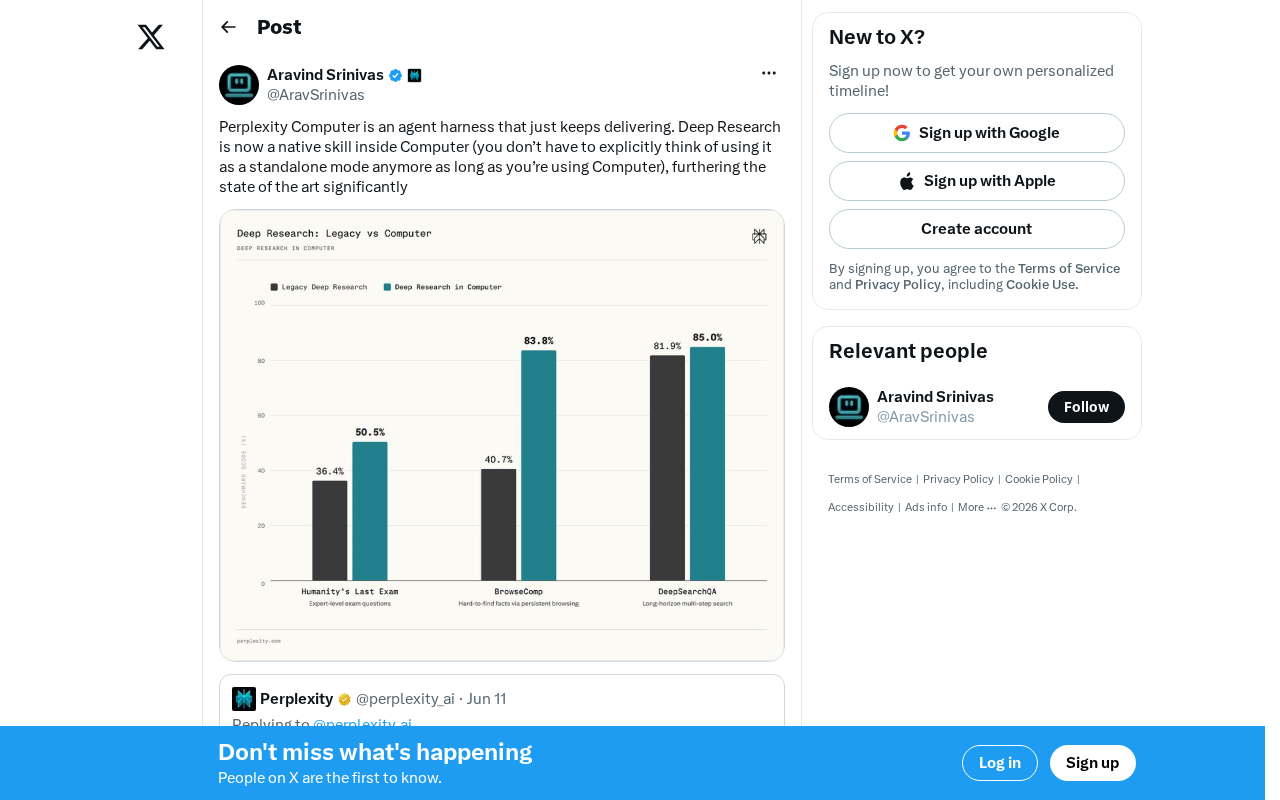
Perplexity Computer Integrates Deep Research as a Native Skill: A New Paradigm for AI Agent Capability Fusion
Perplexity integrates Deep Research as a native skill in Computer, enabling automatic invocation without manual mode switching. Analyzing the Agent Harness design philosophy and AI capability fusion trends.

Key Takeaways from Andrew Ng × OpenAI's Prompt Engineering Course: Two Core Principles Explained
Deep dive into Andrew Ng & OpenAI's ChatGPT Prompt Engineering course: Base LLM vs instruction-tuned models, two core prompting principles, and API-first development thinking for developers.