The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
Enterprise AI is shifting from Token quantity obsession to outcome-based evaluation frameworks.
The Tokenmaxxing trend — where AI vendors compete on context window size and Token throughput — is fading as enterprises realize more Tokens don't equal better results. This article examines the inherent contradictions of the parameter race, technical pitfalls like attention dilution and hallucinations in long contexts, and why outcome-based evaluation frameworks represent the correct direction for AI procurement decisions.
What Is the Tokenmaxxing Craze
Over the past two years of fierce competition among AI large models, an interesting phenomenon has swept through the enterprise AI market — Tokenmaxxing. In simple terms, it refers to AI service providers competing to outdo each other on technical parameters like context window length and Token throughput, creating an arms race built on the premise that "bigger is always better."
To understand this trend, you first need to grasp the concept of Tokens. A Token is the basic unit that large language models use to process text. A single Chinese character is typically encoded as 1-2 Tokens, while an English word might be split into 1-3 Tokens. The context window refers to the maximum number of Tokens a model can process simultaneously in a single inference pass. From GPT-3's 4K Tokens to Claude's 200K Tokens, and then to Gemini's claimed million-Token window, this parameter has grown exponentially in just two years. A larger context window means the model can "read" more content at once, theoretically enabling it to handle more complex long-document analysis tasks — but this doesn't mean the model's comprehension quality is uniform across all input information.
Enterprise customers have been swept up in this as well, chasing longer contexts and higher Token consumption as if Token count itself were a proxy for AI capability. Leaderboards and comparison tables are everywhere, and Tokens have become the new marketing currency.
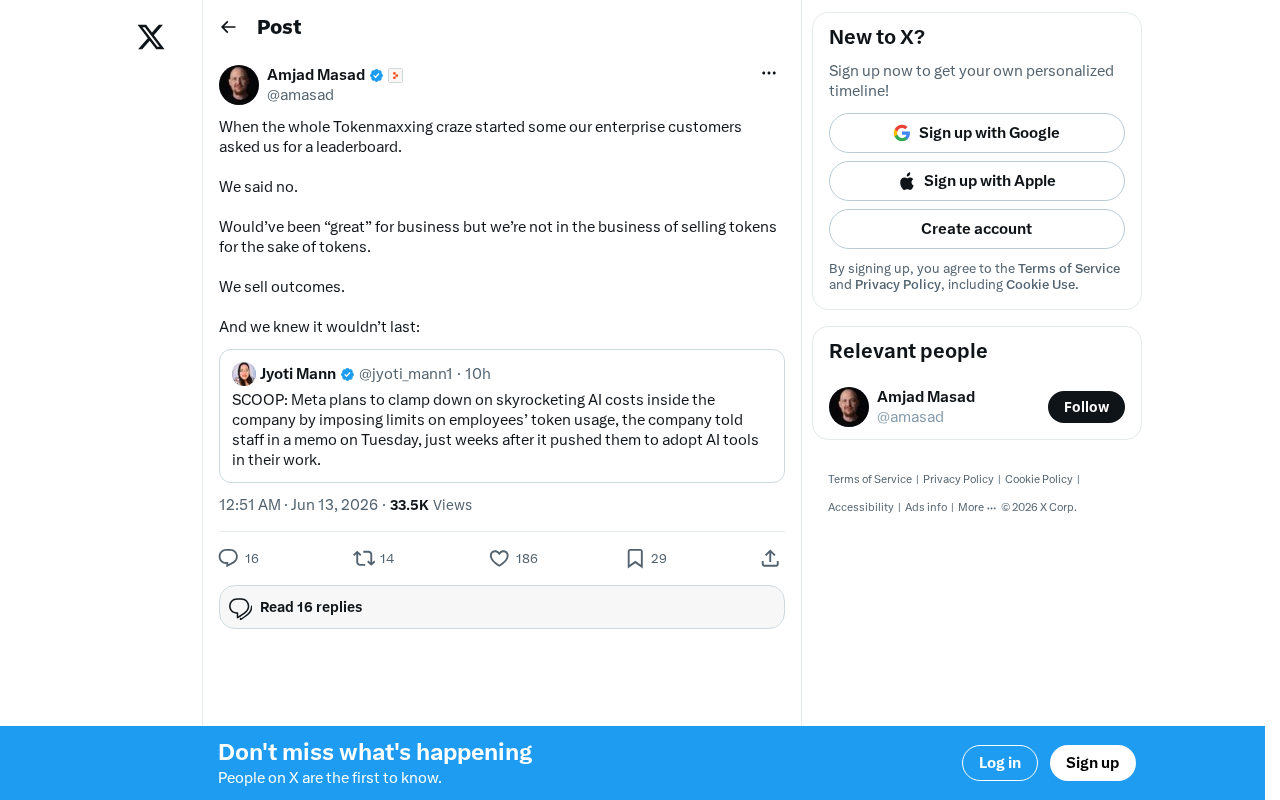
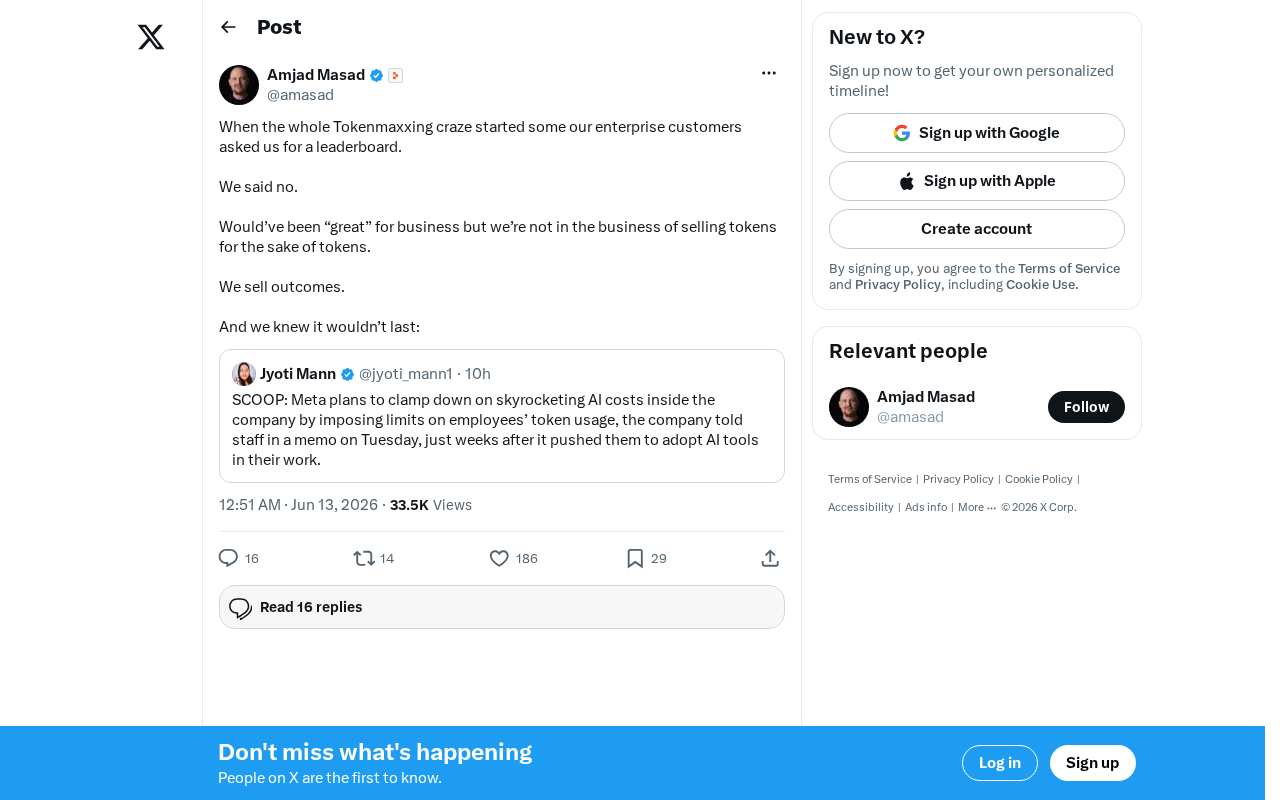
One Company That Said "No" to the Token Race
Amid this wave, one AI service provider refused to participate in the leaderboard game that enterprise customers were demanding. Their logic was clear and firm:
- Refusing to chase vanity metrics: Leaderboards "look good" for business growth, but fundamentally perpetuate a flawed evaluation standard
- Selling outcomes, not Tokens: Their business model is anchored to customers' actual business results, not the consumption of intermediate byproducts
- Independent judgment on trends: They predicted this craze wouldn't last
This decision may have cost them deals in the short term, but it reflects a steadfast commitment to product philosophy.
Why Tokenmaxxing Is Destined to Fade
The Inherent Contradiction of the Parameter Race
More Tokens don't equal better results. It's like judging a car not by how much fuel it burns, but by where it takes you. As the industry returns to rationality, enterprises will refocus on the dimensions that truly matter:
- Task completion quality: Does the AI output actually solve the business problem?
- Response accuracy: How reliable and consistent are the results?
- Actual business ROI: Is the input-output ratio reasonable?
- Cost efficiency: Can the same results be achieved with fewer resources?
The Technical Pitfalls of Long Contexts
When context windows become excessively long, the attention mechanism in Transformer architecture faces an "attention dilution" problem. Research shows that large language models tend to remember information at the beginning and end of text better when processing very long contexts, while "forgetting" information in the middle — a phenomenon known as "Lost in the Middle." The industry commonly uses the "Needle in a Haystack" test to evaluate a model's ability to retrieve specific information within long contexts, and many models perform far worse on this test than their advertised context lengths would suggest. Furthermore, overly long contexts increase the probability of model hallucination — generating content that seems plausible but is actually incorrect.
The Market Is Self-Correcting
As AI applications enter deeper waters, enterprise users are gradually recognizing that blindly pursuing Token consumption not only increases costs but may also cause problems like attention dilution and increased hallucinations due to excessively long contexts. Truly mature AI procurement decisions are returning to an "outcome-based" evaluation framework.
This framework originates from mature methodologies in IT service outsourcing, with the core idea of measuring and paying based on delivered business outcomes rather than consumed resources. In the AI domain, this means moving away from billing by Token usage and instead pricing based on actual tasks completed, accuracy rates, human labor hours saved, and other business metrics. For example, the value of an AI customer service system shouldn't be measured by how many Tokens it processed, but by how many customer issues it successfully resolved, how much it reduced average handling time, and how many percentage points it improved customer satisfaction. Analyst firms like Gartner have also been consistently advocating for enterprises to adopt this evaluation approach to avoid the "vanity metrics trap" in AI investment.
What the Decline of Tokenmaxxing Means for the AI Industry
Technical Metrics ≠ Business Value
This phenomenon reflects a recurring problem in the AI industry: technical metrics being over-marketed. From parameter counts to Token numbers, from benchmark scores to context lengths, each wave of new metric hype eventually gives way to actual utility.
The AI industry's Benchmark culture has a long history — from ImageNet to GLUE, from MMLU to HumanEval, each generation of benchmarks has dominated industry narratives. However, there's a significant gap between Benchmark scores and actual business utility. Model vendors can boost scores on specific Benchmarks through targeted training (i.e., "gaming the leaderboard"), and these optimizations don't necessarily transfer to real business scenarios. Stanford's HELM project and community-driven evaluation platforms like Chatbot Arena attempt to provide more comprehensive model evaluation perspectives, but even so, no standardized test can fully replace real-world validation in an enterprise's own business context. This is why an increasing number of mature enterprises are building their own internal evaluation benchmarks rather than relying on public leaderboards for procurement decisions.
The Right Approach to Enterprise AI Procurement
For enterprises currently evaluating AI solutions, this is a lesson worth remembering:
- Define clear business objectives rather than chasing technical parameters
- Focus on end-to-end outcomes rather than Token consumption in intermediate processes
- Be wary of leaderboard-driven procurement decisions — leaderboards often reflect the dimensions vendors want you to see
- Choose vendors whose interests align with yours — those who sell outcomes are more motivated to help you succeed than those who sell resources
Conclusion: Focusing on Outcomes Is the Most Sustainable AI Strategy
Amid the noise of the AI industry, saying no to short-term temptations that "look good for business" requires clear self-awareness and accurate judgment of industry trends. The decline of Tokenmaxxing proves once again: on the path to technology commercialization, focusing on creating real value for customers is always the most sustainable strategy.
Key Takeaways
Related articles
Claude Code Installation Guide & The Five Stages of AI Programming Tools Explained
Complete Claude Code installation guide with the five stages of AI programming tools, from manual coding to agents. Learn 0-to-1 project building and 1-to-100 iteration challenges.

Enterprise-Level AI Project Rules Files: 5 Hard Rules + 6 Writing Techniques
AI keeps messing up your code? Learn 5 hard rules and 6 writing techniques for enterprise-level Rules files in Claude Code, Cursor & more, with templates.
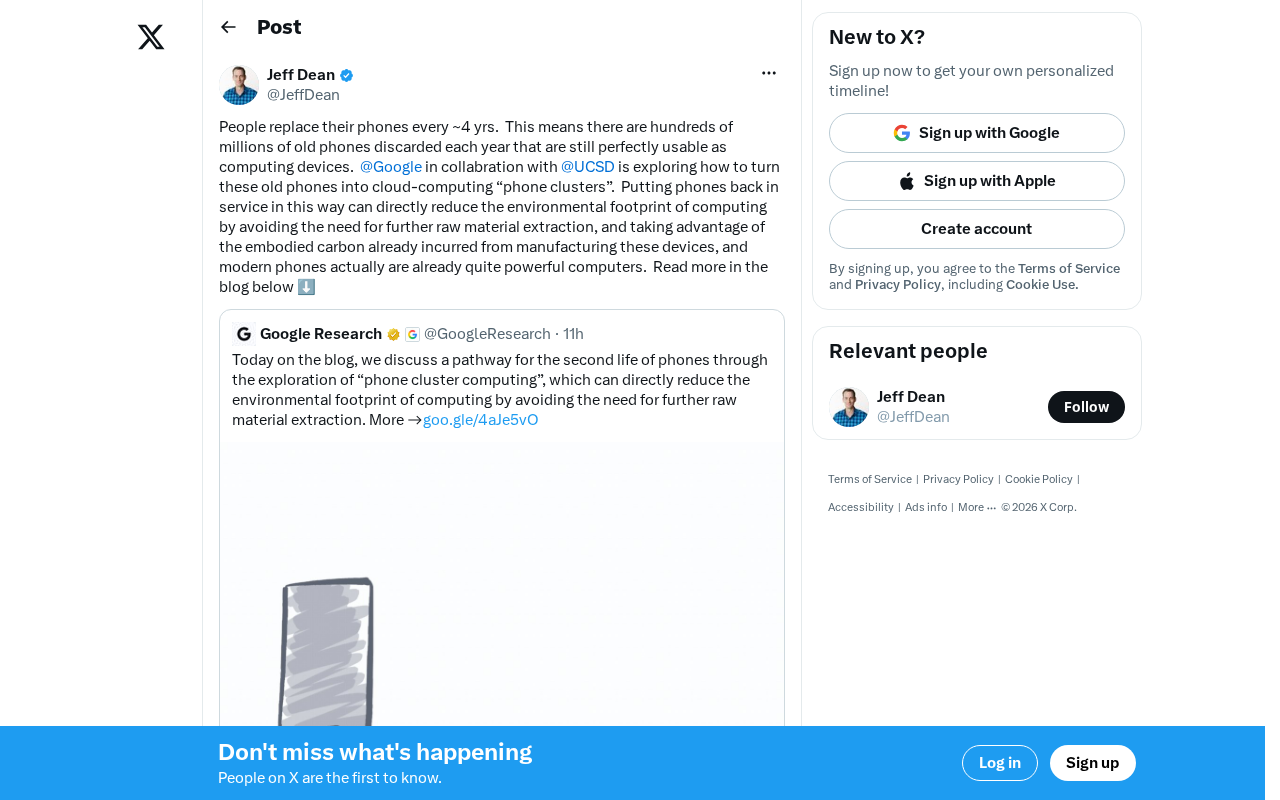
Building Cloud Computing Clusters from Old Phones: Google and UCSD Explore a New Path to Sustainable Computing
Google and UCSD explore building cloud clusters from old phones, leveraging ARM chip efficiency to cut e-waste and data center carbon footprints.