Perplexity Computer Integrates Deep Research as a Native Skill: A New Paradigm for AI Agent Capability Fusion
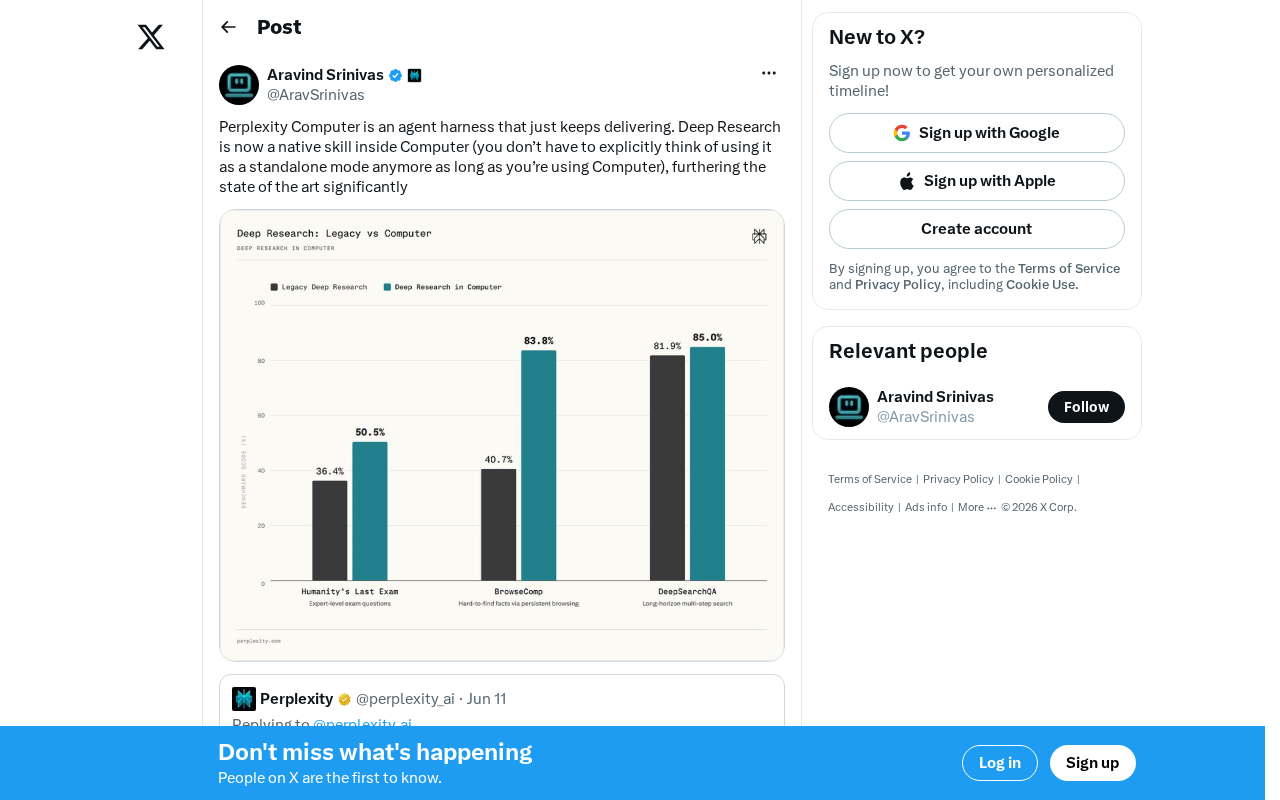
Perplexity makes Deep Research a native Computer skill, advancing seamless AI Agent capability fusion.
Perplexity has integrated Deep Research as a native skill within its Computer product, eliminating the need for users to manually switch modes. This shift embodies the Agent Harness design philosophy, where the AI autonomously decides when to invoke deep research. The article compares this approach with ChatGPT and Gemini, explores the industry trend toward unified AI Agents, and discusses the technical challenges of intent routing and resource optimization.
The Latest Evolution of Perplexity Computer
Perplexity recently announced a significant update: Deep Research has been integrated as a native skill of Perplexity Computer. This means users no longer need to manually switch to a separate Deep Research mode when using Computer — the system automatically invokes deep research capabilities based on task requirements.
Deep Research is a multi-step, multi-round automated research methodology that differs from traditional single-query retrieval. It simulates the workflow of a human researcher: starting with an initial query, generating follow-up sub-questions based on returned results, conducting in-depth investigation on each sub-question, and ultimately synthesizing multiple information sources into a structured report. This process typically involves dozens or even hundreds of web requests and cross-validation of information. OpenAI was the first to launch a similar feature in ChatGPT Pro in early 2025, followed by Perplexity, Google Gemini, and other products. The core technical challenges of Deep Research lie in query decomposition, source reliability assessment, and consistency integration of multi-source information.
This change may seem simple, but it represents an important shift in AI Agent architecture design philosophy.
From Standalone Tool to Native Skill: Why This Matters
Eliminating Cognitive Burden on Users
In the previous product design, Deep Research was an independent feature mode. Users needed to explicitly recognize "I need to do deep research right now" and then actively switch to the corresponding mode. While functionally complete, this design imposed additional cognitive burden on users — you had to first assess the task type, then select the appropriate tool.
By making Deep Research a native skill of Computer, the decision-making authority shifts from the user to the AI Agent itself. The Agent autonomously determines when to initiate deep research, when a simple retrieval suffices, and when to combine multiple capabilities to complete a task. This is the core value proposition of the Agent architecture.
An AI Agent refers to an AI system capable of autonomously perceiving its environment, formulating plans, and executing actions — distinct from traditional "input-output" style LLM interactions. In Agent architecture, core components typically include: a Planning module, a Memory module, a Tool Use module, and a Reflection module. The key capability of an Agent is "autonomous decision-making" — it doesn't require step-by-step instructions from users but instead breaks down tasks, selects tools, executes operations, and verifies results based on high-level objectives. This architectural philosophy originates from cross-disciplinary research in reinforcement learning and cognitive science, and has rapidly moved toward productization in recent years as LLM reasoning capabilities have improved.
The Design Philosophy of Agent Harness
Perplexity officially positions Computer as an "Agent Harness," a term worth paying attention to. In software engineering, "harness" typically refers to a "test framework" or "runtime framework" used to uniformly manage and orchestrate multiple components. By positioning its Computer product as an Agent Harness, Perplexity means it plays a "meta-layer" role — rather than directly executing any specific task, it serves as an orchestration hub that dynamically arranges underlying capability modules based on task requirements. This design pattern is known as the "Orchestrator Pattern" in microservices architecture, with the advantage that each capability module can be independently iterated and upgraded while the upper-layer orchestration logic remains stable. Similar design philosophies also appear in open-source Agent frameworks like LangChain and AutoGPT, but Perplexity is among the first companies to present this architecture in a consumer-grade product form.
With the integration of Deep Research, Computer now possesses at least the following native capabilities:
- Web Search and Information Retrieval: Perplexity's core competency
- Deep Research and Analysis: Multi-round, multi-source in-depth investigation of complex topics
- Computer Operation: Direct interaction with desktop applications and web pages
- Task Orchestration: Automatically combining the above capabilities to complete complex tasks
The "computer operation" capability refers to the AI Agent's ability to directly control mouse clicks, keyboard input, screenshot recognition, and other operations to interact with desktop applications and web pages. This technology was first publicly demonstrated by Anthropic in October 2024 with the release of Claude 3.5 Sonnet, known as "Computer Use." The underlying technical principle involves using vision models to recognize screen content, combining LLM reasoning capabilities to generate operation instructions, and then executing specific GUI operations through system-level APIs. The significance of this capability is that it breaks the limitation of AI working only within chat windows, enabling it to operate any software tool that humans can use.
This trend of "skill fusion" is becoming the mainstream direction for AI Agent products.
Industry Trend: From Point Tools to Unified Agents
Comparison with ChatGPT, Gemini, and Other Competitors
Perplexity's move is highly aligned with the broader trend in the AI industry. OpenAI's ChatGPT has been continuously integrating search, code execution, image generation, and other capabilities into a unified conversational interface; Google's Gemini is similarly advancing seamless integration of multimodal capabilities.
However, what makes Perplexity unique is that, starting from its search engine DNA, it positions information retrieval and deep research as the core skill tree of its Agent. This creates a clearly differentiated competitive landscape compared to ChatGPT's approach from conversational generation and Gemini's approach from multimodal understanding.
The current competitive landscape in the AI Agent space can be understood through each company's "DNA." OpenAI started with the GPT series of large language models, building its Agent capabilities on powerful general reasoning and generation; Google DeepMind has the natural advantage of its search engine and multimodal data, with Gemini's Agent-ification path emphasizing cross-modal understanding and Google ecosystem integration; Anthropic focuses on safety and controllability as its core selling points, with Claude's Computer Use feature emphasizing reliable tool operation. Perplexity's differentiation lies in the fact that it is essentially an "Answer Engine," with its core competitive advantage being the accuracy and timeliness of information retrieval. Making Deep Research a native skill is effectively reinforcing this core strength, building a moat in the vertical scenario of "information-intensive tasks."
Practical Impact on User Experience
For end users, the practical significance of this update is:
- Smoother workflows: No more switching back and forth between different modes
- Potentially improved result quality: The Agent can dynamically decide whether deep research is needed during task execution, rather than making an either-or judgment at the outset
- Lower barrier to entry: New users don't need to understand what Deep Research is — the system automatically uses it when needed
Looking Ahead: The Next Step in AI Agent Capability Integration
This update to Perplexity Computer reflects a key direction in AI Agent development — seamless capability fusion. Future AI Agents won't ask users to choose between "search mode, research mode, or writing mode." Instead, like an all-capable assistant, they will automatically allocate the most suitable combination of capabilities based on task requirements.
Of course, this also introduces new technical challenges: How does the Agent accurately determine when to initiate deep research? How does it balance response speed with research depth? How does it find the optimal solution between resource consumption and result quality?
From a technical perspective, an Agent's automatic determination of when to initiate deep research is essentially an "Intent Routing" problem. The system needs to assess the task's complexity, the required depth and breadth of information, and the user's implicit expectations within an extremely short time after receiving a user request, then decide which capability modules to invoke. The difficulty of this decision lies in the fact that over-triggering deep research leads to response delays (Deep Research typically takes several minutes), while under-triggering returns shallow, incomplete results. Current mainstream approaches in the industry include classifier-based routing, LLM self-evaluation-based routing, and hybrid routing strategies. Additionally, deep research involves substantial API calls and computational resource consumption, and finding the right balance between cost control and result quality is a key consideration for commercial deployment.
The quality of solutions to these problems will determine the true competitiveness of each AI Agent product.
Perplexity describes Computer's continuous evolution with the phrase "just keeps delivering." Judging by the current pace of product iteration, this assessment is not an exaggeration.
Key Takeaways
Related articles
Claude Code Installation Guide & The Five Stages of AI Programming Tools Explained
Complete Claude Code installation guide with the five stages of AI programming tools, from manual coding to agents. Learn 0-to-1 project building and 1-to-100 iteration challenges.

Enterprise-Level AI Project Rules Files: 5 Hard Rules + 6 Writing Techniques
AI keeps messing up your code? Learn 5 hard rules and 6 writing techniques for enterprise-level Rules files in Claude Code, Cursor & more, with templates.
Building Cloud Computing Clusters from Old Phones: Google and UCSD Explore a New Path to Sustainable Computing
Google and UCSD explore building cloud clusters from old phones, leveraging ARM chip efficiency to cut e-waste and data center carbon footprints.