Complete Guide to LLM Training: Pre-training, SFT Fine-tuning, and Preference Alignment Explained
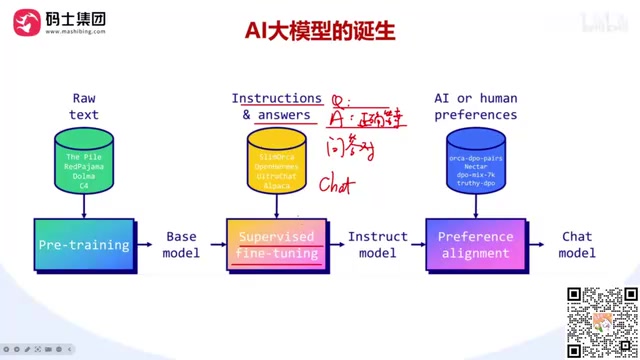
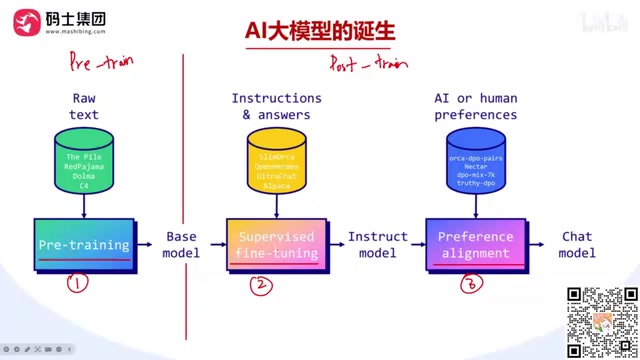
A complete breakdown of the three-stage LLM training pipeline: pre-training, SFT, and preference alignment.
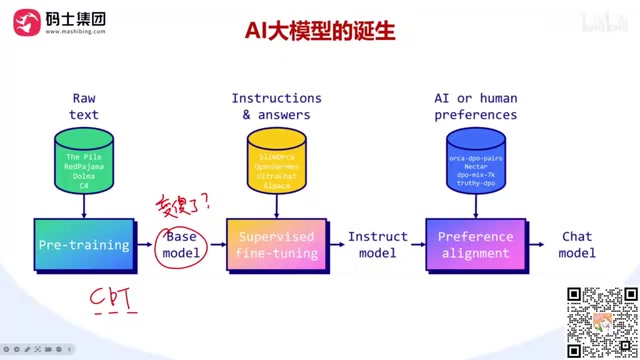
This article systematically covers the three-step LLM training pipeline: pre-training (learning to predict the next token), supervised fine-tuning/SFT (learning Q&A conversational ability), and preference alignment (optimizing response quality via DPO/PPO/GRPO). Regular developers only need to focus on post-training, choosing SFT or CPT based on data format. It also clarifies that LoRA is an implementation algorithm rather than a learning paradigm, and introduces three model compression methods: distillation, quantization, and pruning.
How Are Large Language Models Built? A Three-Step Training Process Explained
The LLMs we use daily—ChatGPT, DeepSeek, Kimi, Qwen, and others—may seem magical, but they all go through three core stages to come into existence. Based on a Qwen3 deployment and fine-tuning course from a Chinese AI instructor on Bilibili, this article breaks down the complete knowledge framework of LLM training in an accessible way.
Step 1: Pre-training — Building the Shell
Pre-training is the first and most resource-intensive stage of creating an LLM. Major tech companies crawl massive amounts of text data from the internet, clean it, deduplicate it, filter out inappropriate content, and then use this data to train the model.
The core objective of pre-training is to give the model the ability to Predict the Next Token. When you input "New Yo", the model predicts the next characters are most likely "rk"; then it predicts "City"... This is the fundamental principle behind how Generative Models produce text one token at a time.
From a technical implementation perspective, Next Token Prediction is the core training objective of autoregressive language models. The model uses the Causal Attention mechanism in the Transformer architecture, which only allows it to see all tokens before the current position, then outputs a probability distribution over every token in the vocabulary through a softmax layer. During training, Cross-Entropy Loss is used to measure the gap between the predicted distribution and the actual next token. This seemingly simple training objective, driven by massive data, enables the model to exhibit emergent capabilities like reasoning, translation, and coding—Scaling Law shows that as model parameters, data volume, and compute increase, model performance improves in a predictable power-law fashion, which is the theoretical basis for companies continuously scaling up training.
This stage is like building a shell of a house—it requires enormous resources (data, servers, time), but only produces a Base Model with basic functionality.
Step 2: Supervised Fine-Tuning (SFT) — Interior Finishing
After pre-training, the model can generate text but doesn't yet have good conversational abilities. The SFT (Supervised Fine-Tuning) stage prepares large amounts of Question-Answer pairs for the model, teaching it "how to respond to specific questions."
The key to supervised fine-tuning lies in constructing high-quality instruction data. A typical SFT data format includes three roles: system prompt, user (user input), and assistant (model response). During training, the model only computes loss on the assistant portion (i.e., it only learns how to answer, not how to ask questions)—this technique is called "Loss Masking." Industry experience shows that data quality matters far more than quantity—a few thousand carefully annotated high-quality examples often outperform tens of thousands of low-quality ones. Additionally, the learning rate during SFT is typically 1-2 orders of magnitude lower than during pre-training to avoid destroying the general knowledge learned during pre-training.
By correcting model parameters against known correct answers, the model gains Chat capabilities. This is like the interior finishing of a house—only after finishing can you move in. The Instruct Models that major companies open-source are the "move-in ready" versions after this step.
Step 3: Preference Alignment — Decorating to Taste
The same question can have multiple correct answers, but which style best meets user expectations? Preference alignment solves this problem.
Depending on the specific algorithm, data preparation differs:
- DPO algorithm: Requires both positive examples (preferred responses) and negative examples (dispreferred responses)
- PPO/GRPO algorithms: Only requires preferred responses, letting the model explore why certain answers are better
A deeper look at the differences between these three algorithms: PPO (Proximal Policy Optimization) is the classic algorithm OpenAI originally used for RLHF, requiring four networks simultaneously—policy model, reference model, reward model, and value model—making training complex and memory-intensive. DPO (Direct Preference Optimization), proposed in 2023, is a simplified approach that cleverly incorporates the reward model implicitly into policy optimization, requiring only the policy model and reference model, significantly lowering the training barrier. GRPO (Group Relative Policy Optimization), proposed by DeepSeek, eliminates the value model and estimates the advantage function through group-relative ranking, demonstrating powerful reasoning capability improvements in DeepSeek-R1's training. These three algorithms represent the evolution of preference alignment technology from complex to simple.
This is like decorating—choosing artwork, plants, and furniture arrangement based on the resident's personal preferences, fully customized to individual taste.
Pre-training vs. Post-training: What Should Regular Developers Focus On?
Among the three steps above, the first is Pre-training, and the latter two are collectively called Post-training.
For most companies and developers, we don't need to do pre-training. Pre-training is the domain of major tech companies, requiring massive data and compute. What we need to do is post-training—take an open-source model and optimize it through SFT or preference alignment to adapt it to specific business scenarios.
Continuous Pre-Training (CPT): A Special Case
If your data isn't in Q&A format but consists of large volumes of domain-specific articles (e.g., agriculture, healthcare, legal documents), you need Continuous Pre-Training (CPT)—continuing to train an existing model with domain articles using the pre-training approach.
Continuous pre-training is very common in vertical domain applications. For example, when adapting a general-purpose LLM to the medical domain, you need to perform CPT with large amounts of medical literature, clinical guidelines, and patient records to help the model master professional terminology and domain knowledge. Data mixing ratios in CPT are a key engineering decision: besides mixing in general data to prevent forgetting, you need to control the proportions of data from different sources. Learning rate scheduling typically uses Cosine Annealing, with the starting learning rate set at the same order of magnitude as the learning rate at the end of pre-training. Additionally, CPT usually requires another round of SFT afterward to restore the model's conversational ability, since CPT may weaken the instruction-following capabilities learned during the SFT stage.
Which training approach to choose depends on two factors:
- What's your goal — Choose SFT to improve conversational ability, choose preference alignment to enhance reasoning
- What's your data format — Q&A pairs → SFT, plain articles → CPT
Solving the "Forgetting" Problem
Continuous pre-training can cause the model to "get dumber"—forgetting old knowledge while learning new knowledge. This is academically known as "Catastrophic Forgetting," a classic challenge in continual learning for neural networks. The solution is straightforward: review while learning new material. During training, in addition to new domain corpus, mix in 10%-20% of the original pre-training data to let the model "review" existing knowledge.
LoRA and Training Paradigms: Different Conceptual Levels
Many beginners confuse the relationship between LoRA and SFT. This needs special emphasis:
- SFT, CPT, Preference Alignment are "learning paradigms" — the approach and methodology of training
- LoRA is a "specific implementation algorithm" — how to efficiently execute these training approaches
LoRA (Low-Rank Adaptation) is based on an important finding: parameter changes during LLM fine-tuning exhibit low-rank properties. Specifically, for a d×d weight matrix W, LoRA doesn't update W directly but decomposes the update into a product of two small matrices: ΔW = A×B, where A is a d×r matrix and B is an r×d matrix, with r much smaller than d (typically r=8, 16, or 64). This reduces trainable parameters from d² to 2dr, dramatically reducing memory usage. During inference, ΔW can be merged back into the original weights, adding zero inference latency. Variants like QLoRA (combined with 4-bit quantization) further compress memory requirements, enabling consumer-grade GPUs (like a single 24GB RTX 4090) to fine-tune models with billions of parameters.
Regardless of which post-training approach you choose, you can decide whether to use LoRA. They are concepts on different dimensions—one is "what to do," the other is "how to do it."
Three Approaches to Model Compression: Distillation, Quantization, and Pruning
After training, models need to be deployed, but large models often consume enormous amounts of GPU memory. There are three mainstream approaches to reduce model size:
| Method | Analogy | Principle |
|---|---|---|
| Distillation | Putting the filling from a large bread into a small cake | Using a large model (teacher) to guide a small model (student) in learning |
| Quantization | Forcefully squeezing the bread smaller | Directly compressing model parameter precision |
| Pruning | Trimming excess branches from a tree | Removing unimportant connections in the neural network |
A deeper look at these three techniques: Knowledge Distillation has the small model learn not only hard labels (correct answers) but also soft labels (probability distributions) from the large model's output, because soft labels contain inter-class similarity information that conveys richer "dark knowledge." Quantization compresses model parameters from FP32/FP16 precision to INT8, INT4, or even lower bit-widths. Common approaches include GPTQ (layer-wise quantization, suitable for GPU inference), AWQ (activation-aware quantization, protecting important weights), and GGUF (quantization format for the llama.cpp ecosystem, supporting CPU inference). Pruning is divided into unstructured pruning (removing individual weights, creating sparsity) and structured pruning (removing entire attention heads or network layers)—the latter is more hardware-friendly and achieves actual inference speedup. In practice, these three methods are often combined, such as first distilling to get a smaller model, then quantizing the smaller model.
All three methods share the same goal—saving GPU memory during deployment—but their implementation approaches are completely different.
Skill Requirements for LLM Positions
For the role of "LLM Application Algorithm Engineer":
- Application skills account for 70%-80%: Building applications on top of LLMs
- Algorithm skills account for 20%-30%: Knowing how to fine-tune, understanding data preparation, grasping underlying principles
- Education requirements: At least a bachelor's degree, no specific major required
- Core skills: Primarily Python, with hands-on fine-tuning experience, parameter tuning, and troubleshooting
You don't need to design an entirely new model architecture, but you need to understand the principles—knowing which angle to optimize from when problems arise, and understanding the meaning behind each parameter setting. Reinforcement Learning (RL) knowledge is also essential, since preference alignment algorithms like PPO and GRPO are all based on reinforcement learning. The core idea of RL is to have an Agent optimize its policy through reward signals obtained by interacting with an environment. In LLM training, the model is the agent, generated responses are actions, and human preference scores are reward signals. Understanding this framework is crucial for mastering various preference alignment algorithms.
Key Takeaways
- LLMs go through three stages: pre-training, supervised fine-tuning (SFT), and preference alignment—corresponding to building a shell, interior finishing, and decorating to taste
- Regular developers only need to focus on post-training, including SFT, CPT, and preference alignment; the choice depends on data format and business needs
- LoRA is a specific training algorithm (reducing trainable parameters through low-rank decomposition), while SFT/CPT are learning paradigms—they're on different conceptual levels and shouldn't be confused
- Model compression includes distillation, quantization, and pruning, all aimed at reducing GPU memory usage during deployment, often used in combination
- LLM Application Algorithm Engineer roles are primarily application-focused (70-80%), with algorithm understanding as secondary, requiring Python proficiency and hands-on fine-tuning skills
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.