Agentic RAG in Practice: Architecture Deep Dive and LangChain Implementation Guide
Agentic RAG encapsulates retrieval as tools and empowers LLMs with autonomous decision-making to overcome traditional RAG limitations.
Traditional RAG follows a fixed unidirectional pipeline (retrieve → assemble → generate) with no feedback loop or self-correction. Agentic RAG encapsulates retrieval, file reading, and other capabilities as callable tools, using the ReAct pattern to let LLMs autonomously decide in a Think → Call Tool → Observe → Think Again closed loop, enabling multi-step iterative retrieval and dynamic error correction. This article uses the ChatBoss open-source project to demonstrate four core tool designs and LangGraph code implementation.
The limitations of traditional RAG systems are becoming increasingly apparent to developers: returning empty results when retrieval fails, inability to answer metadata questions like "what documents are in the knowledge base," and lack of multi-turn iterative error correction. In 2025, Agentic RAG is emerging as the core paradigm for LLM application development. This article starts from the implementation principles of traditional RAG, provides an in-depth analysis of Agentic RAG's architecture design, and delivers a complete code implementation based on LangChain and LangGraph.
Traditional RAG: Implementation Flow and Critical Limitations
Offline Pipeline: Document Chunking → Vectorization → Storage
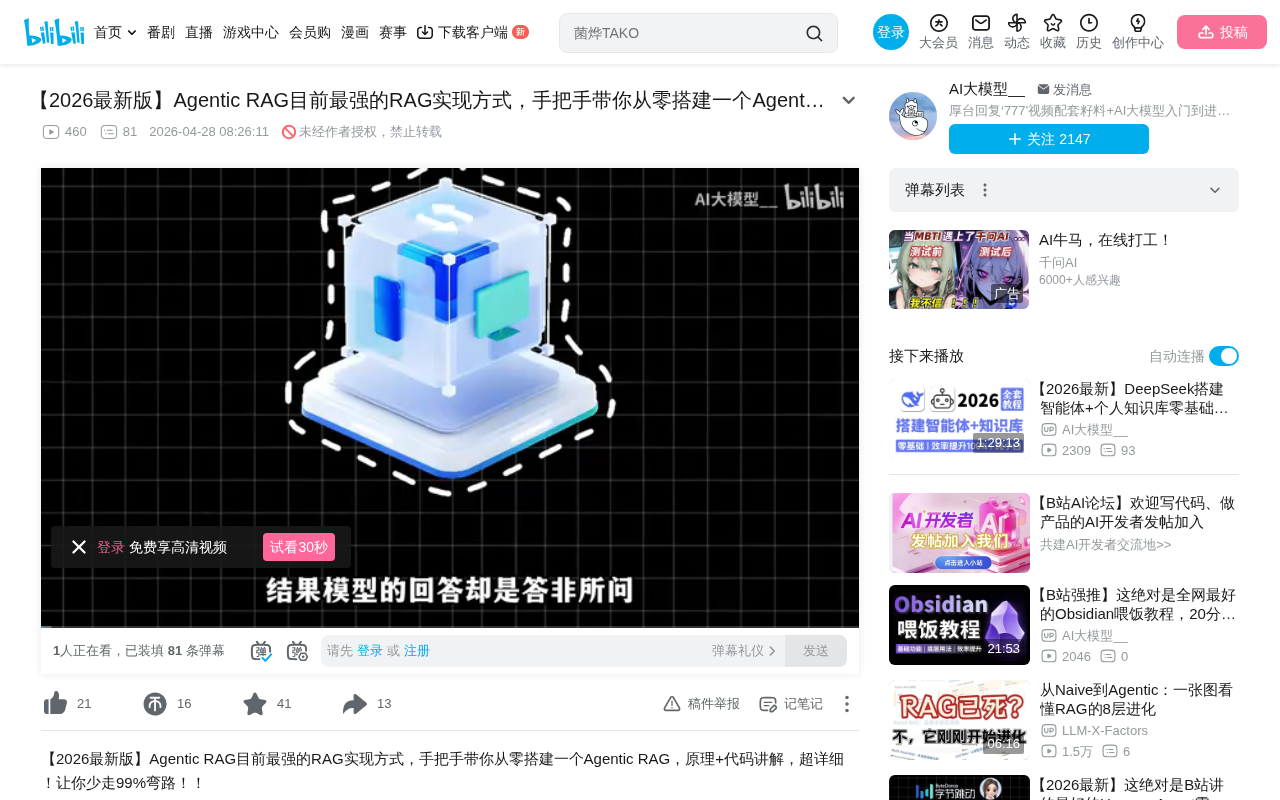
The first core pipeline of traditional RAG is offline preprocessing. Documents in formats like PDF, Word, and TXT are first loaded into memory, then undergo text chunking. Since a complete document may contain tens of thousands of characters and cannot be fed into an LLM's context window all at once, the document needs to be split into fixed-length segments (e.g., 256 characters), with overlapping regions between segments to maintain semantic coherence.
After chunking, each segment is converted into a fixed-dimensional vector representation through an Embedding model (such as Qwen Embedding 0.6B), and finally stored in a vector database (such as ChromaDB). This process is completely independent of user queries and belongs to the system initialization phase.
Technical Background on Embedding Models: Embedding models are neural networks that map natural language text into high-dimensional vector spaces. The core idea stems from the distributional semantics hypothesis — words with similar meanings are close together in vector space. Early models like Word2Vec and GloVe could only handle word-level representations, while modern Embedding models (such as OpenAI's text-embedding-ada-002 and Alibaba's Qwen Embedding series) can encode entire sentences or paragraphs into fixed-dimensional dense vectors (typically 768 or 1024 dimensions). Vector similarity is usually calculated using cosine similarity or inner product distance, enabling semantic retrieval to go beyond traditional keyword matching and capture deep semantic associations like synonyms and paraphrases.
About ChromaDB: ChromaDB is an open-source embedded vector database designed specifically for AI applications. Unlike cloud-native vector databases such as Pinecone and Weaviate, ChromaDB runs entirely locally without requiring a network connection, making it ideal for prototyping and small-to-medium-scale applications. It supports multiple distance metrics (cosine similarity, Euclidean distance, inner product) and includes built-in document auto-chunking and metadata filtering. In production environments, when data scales exceed millions of vectors, you'll typically need to consider vector database solutions like Milvus or Qdrant that support distributed deployment and HNSW index optimization.
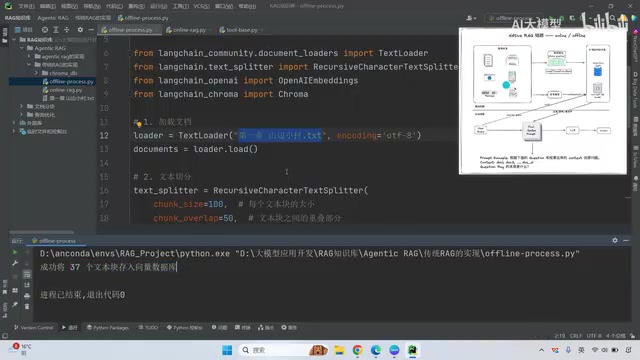
Online Pipeline: Retrieval → Prompt Assembly → Answer Generation
When a user asks a question, the system first performs query rewriting to make it more suitable for retrieval matching. Then retrieval is conducted through two methods: BM25 keyword search and vector similarity matching. After each method returns several segments, the results are merged and re-ranked. The top-K document segments are then injected into a prompt template and sent to the LLM for answer generation.
About BM25 and Hybrid Retrieval Strategies: BM25 (Best Matching 25) is a classic probabilistic ranking algorithm in information retrieval, proposed by Stephen Robertson et al. in the 1990s. It scores document relevance based on three factors: term frequency (TF), inverse document frequency (IDF), and document length normalization. Compared to pure vector retrieval, BM25 has a natural advantage in exact keyword matching (such as proper nouns, code snippets, and numerical identifiers). Hybrid Search combines BM25's exact matching capability with vector retrieval's semantic understanding, using fusion algorithms like Reciprocal Rank Fusion (RRF) to re-rank results from both approaches. In production environments, this typically achieves a 10-20% improvement in recall over any single retrieval method.
The prompt template is usually straightforward: "You are a professional assistant. Please answer the question based on the following reference documents. Context: {retrieved document segments}, Question: {user question}." If the retrieved segments don't contain the answer, the model can only reply with "I don't know."
Why Traditional RAG Falls Short
The entire process is unidirectional, fixed, and one-shot. From the user's question to retrieval, context assembly, and answer generation — it's a straight line from start to finish. When the first round of retrieval fails to hit relevant content, the system has no ability to re-retrieve, try a different query strategy, or proactively supplement context. This is the fundamental limitation of traditional RAG — no feedback loop and no self-correction mechanism.
Agentic RAG: From Fixed Pipeline to Intelligent Decision Loop
Core Concept: Encapsulating Retrieval as Callable Tools
Agentic RAG is a fundamental upgrade to the entire RAG workflow. It encapsulates every component of the RAG pipeline — query rewriting, vector retrieval, keyword search, file reading, etc. — as callable tools, and grants the LLM autonomous decision-making authority.
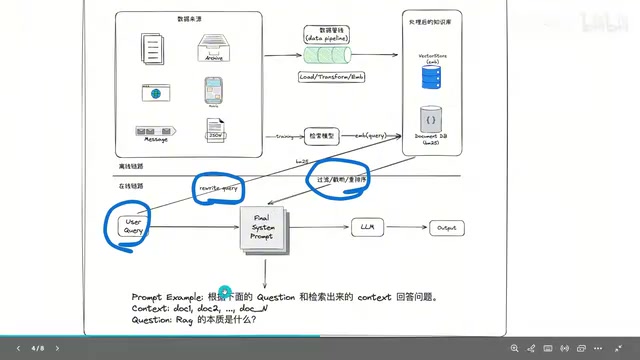
The model no longer passively executes a fixed pipeline. Instead, it enters a Think → Call Tool → Observe Results → Think Again closed loop. Only after gathering sufficient information does it generate the final answer. This is the hallmark behavior pattern of an Agent.
Three Core Capabilities of Agentic RAG
Agentic RAG implementation relies on three key capabilities of the model:
- Planning: The model can plan action steps during Chain-of-Thought reasoning and determine what to do next
- Tool Use: The model can select and invoke appropriate tools based on current needs, and even coordinate multi-agent collaboration
- Multi-step Iteration: The model can perform multiple rounds of tool calls before generating the final answer, continuously refining and supplementing information
The combination of these three capabilities gives Agentic RAG adaptive retrieval and dynamic error correction — features completely absent in traditional RAG.
Theoretical Foundation of the ReAct Pattern: The ReAct (Reasoning + Acting) pattern was proposed by Princeton University and the Google Brain team in 2022, in a paper titled ReAct: Synergizing Reasoning and Acting in Language Models. The core innovation interleaves Chain-of-Thought reasoning with external tool calls — at each step, the model first generates a reasoning trace (Thought), then decides to execute an action (Action), observes the returned result (Observation), and continues reasoning based on the observation. This alternating pattern solves the problem of pure reasoning being prone to hallucinations and pure action lacking planning capability. The ReAct pattern has become the underlying execution paradigm for mainstream Agent frameworks (such as LangChain, AutoGPT, and CrewAI).
ChatBoss Open-Source Project: Agentic RAG Architecture in Practice
Architecture Design Philosophy: Trading Time for Intelligence
Taking the open-source project ChatBoss as an example, its Agentic RAG implementation logic is highly instructive. When a user sends a question, the system first determines whether the current model supports tool calling:
Fallback for Models Without Tool Calling Support: A prompt-based approach determines whether the question requires retrieval. If not, it responds directly; if so, it performs semantic search and injects relevant segments into the context before generating an answer. This "judge first, then retrieve" approach works better than instructing the model to ignore irrelevant context in the prompt.
Full Implementation for Models With Tool Calling Support: All available tools are registered with the model, which autonomously decides which tools to call and in what order. From the moment the user inputs a question, the LLM participates in decision-making — not just at the final generation stage.
Four Core Tool Designs
ChatBoss features four core tools that fully embody the design philosophy of Agentic RAG:
| Tool Name | Functionality | Problem Solved |
|---|---|---|
| Search Query | Basic semantic retrieval | Standard RAG retrieval capability |
| List Files | List files in the knowledge base | Traditional RAG cannot answer "what documents exist" |
| Read File | Read segments by document ID | Proactively supplement surrounding context when information is incomplete |
| Gather File Meta | Read file metadata | Obtain structured document information |
Agent Tool Design Principles: In Agentic systems, the quality of tool design directly determines the Agent's capability boundaries. Excellent tool design follows several principles: First, atomicity — each tool should accomplish one clear function, avoiding feature coupling. Second, description clarity — the tool's name and description must enable the model to accurately understand its purpose and when to invoke it, since the model relies entirely on text descriptions for decision-making. Third, parameter specification — input/output Schema definitions should be strict to reduce the probability of the model generating invalid parameters. Finally, fault tolerance — tools should gracefully handle exceptions and return meaningful error messages rather than crashing, so the Agent can adjust its strategy based on error information.
The List Files tool enables the model to answer metadata queries like "what documents are in the knowledge base" — something traditional RAG simply cannot handle. The Read File tool allows the model to proactively read adjacent segments for additional context when it finds that retrieved segments contain incomplete information, rather than relying solely on semantic similarity retrieval.
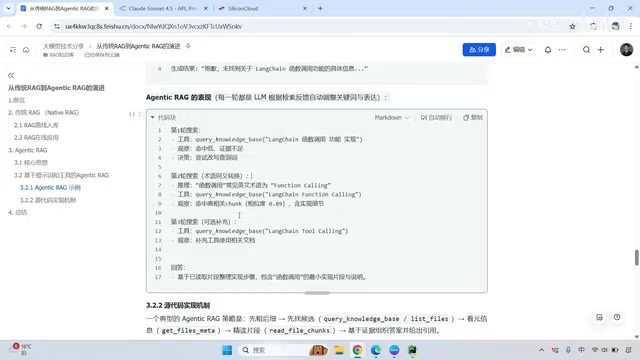
Real-World Performance Comparison
Here's a concrete scenario illustrating the difference:
- Traditional RAG: User query → Vector retrieval → Return results → Generate answer directly (one shot, no chance for correction)
- Agentic RAG: First search → Low hit rate detected → Automatic query rewriting → Second search → Relevant segments found → Third search for supplementary documents → High-quality answer generated from consolidated, complete information
Code Implementation: Traditional RAG vs. Agentic RAG
Traditional RAG with LangChain
Using the LangChain framework, traditional RAG implementation consists of offline and online components:
Offline Component: Load documents → Text splitting (configure chunk_size and overlap) → Embedding vectorization → Store in ChromaDB. The core boils down to three parameters: chunk size, overlap region, and Embedding model selection.
Online Component: Load ChromaDB → Construct user query → Call similarity_search (set K=3 to return the 3 most relevant segments) → Read PageContent → Assemble into prompt template → LLM generates answer.
One important detail: in real projects, the quality of the offline pipeline determines the upper bound of RAG system performance. How you chunk documents, which Embedding model you choose, whether you need a caching strategy — all of these directly impact the quality of the context injected into the prompt.
Agentic RAG with LangGraph
The core of Agentic RAG implementation is LangGraph's create_react_agent function, which implements the ReAct (Reasoning + Acting) pattern:
# 1. Define the tool list
tools = [search_query, list_files, read_file, gather_file_meta]
# 2. Write a system prompt to guide the model's tool usage
system_prompt = "You are an Agentic RAG assistant, please follow these steps..."
# 3. Create the ReAct Agent
agent = create_react_agent(
llm=model, # LLM
tools=tools, # Tool list
system_message=system_prompt # System prompt
)
# 4. Run the Agent
result = agent.invoke({"messages": [user_query]})
About the LangGraph Framework: LangGraph is an Agent orchestration framework released by the LangChain team in 2024, specifically designed for building stateful, multi-step AI applications. Unlike LangChain's linear Chains, LangGraph is based on a directed graph abstraction, allowing developers to define nodes and edges to describe complex control flows, including conditional branching, loops, and parallel execution. Its core advantage lies in built-in state management and checkpointing mechanisms, enabling Agents to maintain context memory across multiple interactions and supporting human-in-the-loop scenarios. create_react_agent is a high-level API provided by LangGraph that encapsulates the complete ReAct loop logic — developers only need to define tools and prompts to quickly build a fully functional Agent.
The code looks concise, but it grants the model autonomous decision-making and dynamic adjustment capabilities. The model continuously calls tools in a "Think-Act-Observe" loop until it has gathered sufficient information to output the final answer.
There's a common pitfall worth noting: the prompt must strictly constrain the model's response format, otherwise the model may strip quotation marks, brackets, or other symbols, causing tool call parameter parsing failures.
Conclusion: Tools Grant Capability, Intelligence Lies in Choice
Traditional RAG is a fixed-process "assembly line" — simple and direct but lacking flexibility and error correction. Agentic RAG is a "closed-loop system" with agent-like behavior — capable of autonomous planning, tool invocation, result reflection, and iterative optimization.
From a technical implementation perspective, the core logic of Agentic RAG isn't complex — encapsulate retrieval capabilities as tools and leverage the ReAct pattern for autonomous model decision-making. The real competitive differentiation lies in three areas: completeness of tool design, precision of prompt engineering, and robust handling of edge cases.
Tools grant capability, but intelligence lies in choice. True Agentic RAG begins with retrieval and succeeds through decision-making.
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.